如何利用CSS选择器抓取京东网商品信息
前几天小编分别利用Python正则表达式、BeautifulSoup、Xpath分别爬取了京东网商品信息,今天小编利用CSS选择器来为大家展示一下如何实现京东商品信息的精准匹配~~

CSS选择器
目前,除了官方文档之外,市面上及网络详细介绍BeautifulSoup使用的技术书籍和博客软文并不多,而在这仅有的资料中介绍CSS选择器的少之又少。在网络爬虫的页面解析中,CCS选择器实际上是一把效率甚高的利器。虽然资料不多,但官方文档却十分详细,然而美中不足的是需要一定的基础才能看懂,而且没有小而精的演示实例。
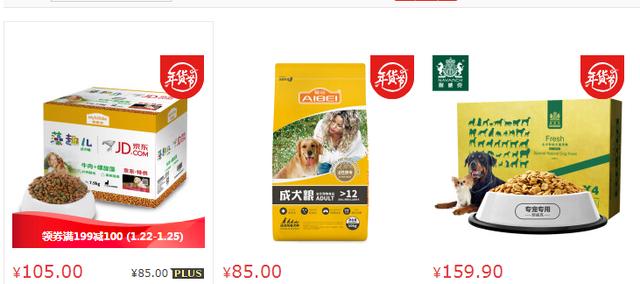
京东商品图
首先进入京东网,输入自己想要查询的商品,向服务器发送网页请求。在这里小编仍以关键词“狗粮”作为搜索对象,之后得到后面这一串网址:
https://search.jd.com/Search?keyword=%E7%8B%97%E7%B2%AE&enc=utf-8,其中参数的意思就是我们输入的keyword,在本例中该参数代表“狗粮”,具体详情可以参考Python大神用正则表达式教你搞定京东商品信息。所以,只要输入keyword这个参数之后,将其进行编码,就可以获取到目标URL。之后请求网页,得到响应,尔后利用CSS选择器进行下一步的数据采集。
商品信息在京东官网上的部分网页源码如下图所示:
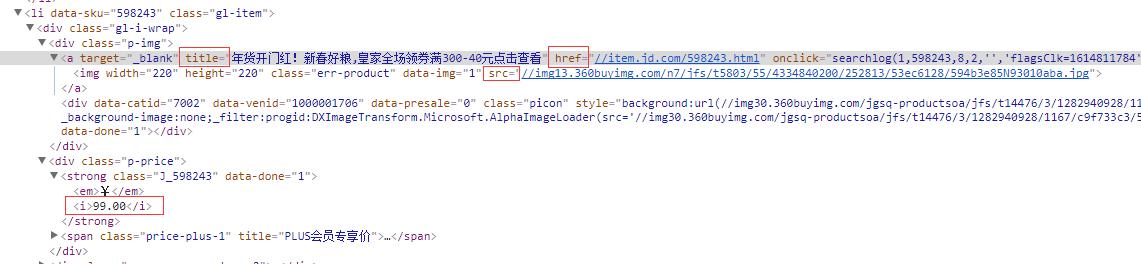
部分网页源码
仔细观察源码,可以发现我们所需的目标信息在红色框框的下面,那么接下来我们就要一层一层的去获取想要的信息。
在Python的urllib库中提供了quote方法,可以实现对URL的字符串进行编码,从而可以进入到对应的网页中去。
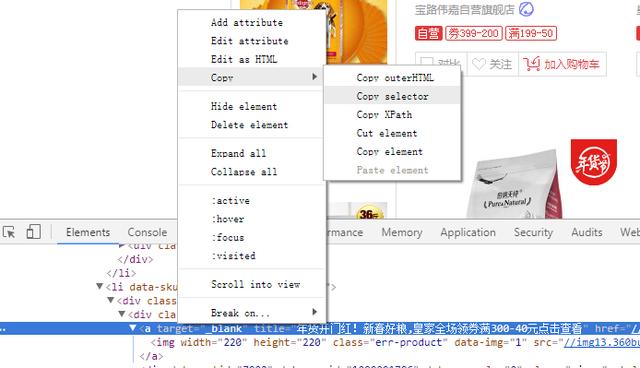
CSS选择器在线复制
很多小伙伴都觉得CSS表达式很难写,其实掌握了基本的用法也就不难了。在线复制CSS表达式如上图所示,可以很方便的复制CSS表达式。但是通过该方法得到的CSS表达式放在程序中一般不能用,而且长的没法看。所以CSS表达式一般还是要自己亲自上手。
直接上代码,利用CSS去提取目标信息,如商品的名字、链接、图片和价格,具体的代码如下图所示:
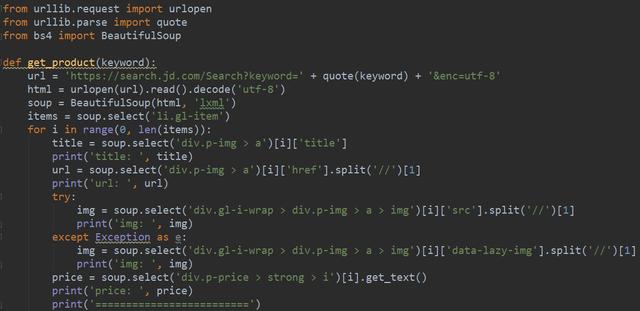
代码实现
如果你想快速的实现功能更强大的网络爬虫,那么BeautifulSoupCSS选择器将是你必备的利器之一。BeautifulSoup整合了CSS选择器的语法和自身方便使用API。在网络爬虫的开发过程中,对于熟悉CSS选择器语法的人,使用CSS选择器是个非常方便的方法。
最后得到的效果图如下所示:
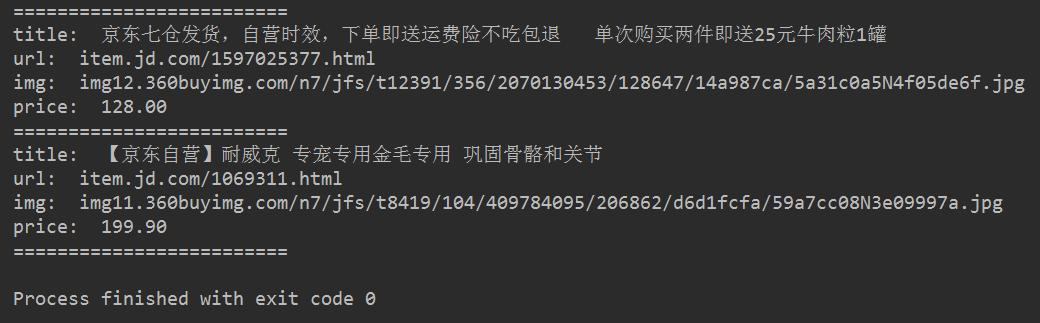
最终效果图
新鲜的狗粮再一次出炉咯~~~

CSS选择器
关于CSS选择器的简单介绍:
BeautifulSoup支持大部分的CSS选择器。其语法为:向tag对象或BeautifulSoup对象的.select()方法中传入字符串参数,选择的结果以列表形式返回,即返回类型为list。
tag.select("string")
BeautifulSoup.select("string")
注意:在取得含有特定CSS属性的元素时,标签名不加任何修饰,如class类名前加点,id名前加 /#。
想学习更多Python网络爬虫与数据挖掘知识,可前往专业网站:http://pdcfighting.com/
最新文章
- centos6 系统安装 system-config-kickstart 工具
- 网络层、传输层、应用层、端口通信协议编程接口 - http,socket,tcp/ip 网络传输与通讯知识总结
- Linux & Oracle 安装目录说明
- ural 1243. Divorce of the Seven Dwarfs
- Routing
- 用maven在eclipse用spring建javaweb工程(一)
- webapi中的自定义路由约束
- EBS initialization parameters - Healthcheck
- Appnium-API-Execute Mobile Command
- [再寄小读者之数学篇](2014-07-27 $H^{-1}$ 中的有界集与弱收敛极限)
- 杂记:解决Android扫描BLE设备名称不刷新问题
- 初学python之感悟
- novnc安装教程
- Android RealativeLayout 布局gravity不能居中的解决办法
- c#经典算法之冒泡排序(Bubble Sort)
- js实现避免浏览器拦截弹出新页面的方法
- svn简单记录
- python3学习笔记(9)_closure
- HTML绘制三角形的方法:
- 新鲜出炉!9个超高分辨率的iPhone 6原型素材打包下载