UntrimmedNets for weakly supervised action recognition and detection概述
0.前言
1.针对的问题
这篇论文之前的行为识别方法严重依赖于修剪过的视频数据来训练模型,然而,获取一个大规模的修剪过的视频数据集需要花费大量人力和时间。
2.主要贡献
从未修剪的视频中引入一种更有效的直接学习动作识别模型的机制。
3.方法
框架流程图如下:
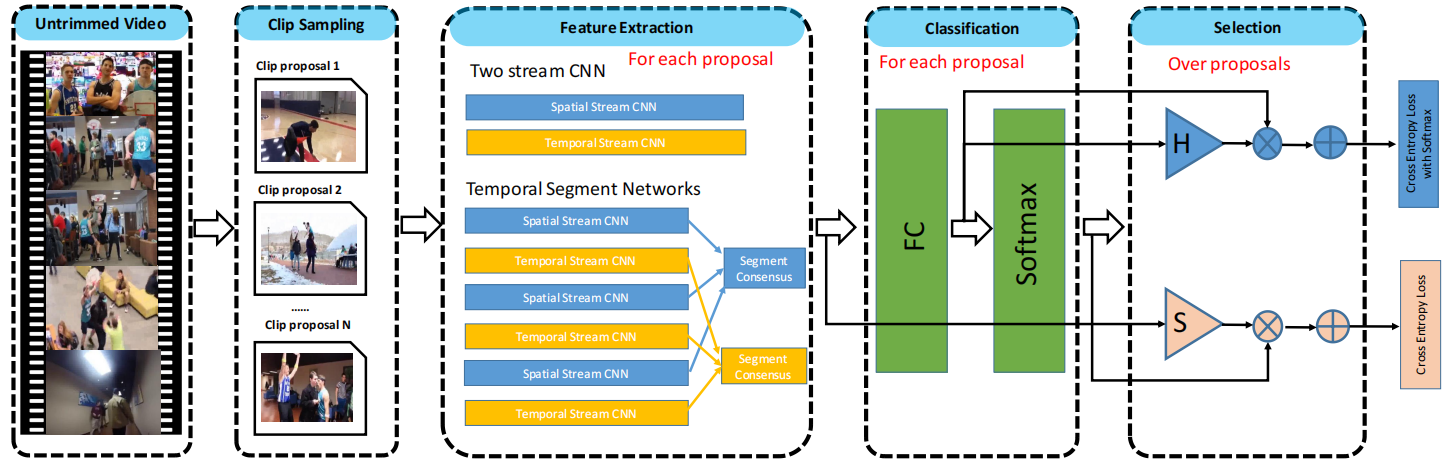
1.生成clip proposal,首先从完整的untrimmed视频中生成shot clip action proposal,论文中使用了两种生成proposal的方法:1、平均采样(Uniform sampling),即把视频均匀分成N段,没有利用到动作信息的连续性,生成proposal不准确。2、Shot-based 采样,先对每帧提取HOG特征,计算每一个当前帧与相邻帧之间的特征距离(绝对值),以此衡量视觉信息变化的程度。如果超过一定阈值,则视为检测到一个shot change,并划分出不同的shot(即以shot为单位粗略划分为不同动作段)。对每个shot内部再采样固定长度为K(设为300)帧的多个shot clips。假设有一个shot(用si=(sbi,sei)表示),根据 从这个shot生成proposals。将这些proposal合并起来,作为UntrimmedNet的训练输入。
从这个shot生成proposals。将这些proposal合并起来,作为UntrimmedNet的训练输入。
2.特征提取模块,将生成的clip propsals分别经过特征提取网络(双流网络,或TSN)提取特征表示。给定一个包含一组clip proposals C={ci}Ni=1的视频V,我们为每个clip proposal c提取表示φ(V;c)∈RD。
3.分类模块,将proposal的特征输入FC层得到原始分类分数xc(c),c表示动作类别数,将原始分类分数输入softmax层得到softmax分类分数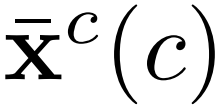 。
。
4.选择模块,图中selection块中的三角形部分,选出最有可能包含动作的clip proposal。分为基于MIL的hard selection和基于attention的soft selection。hard selection使用原始分类分数,选择原始分类得分最高的前k个实例,然后对这些被选择的实例进行平均得到hard selection score xsi(cj),表示对分类i,clip cj被选择的概率。soft selection使用softmax分类分数,利用注意力机制,对所有proposal学习一个用来排序的注意力权重,具体来说,对每个proposal的特征用一个线性层φ(c)进行变换,然后通过softmax层求得注意力分数,即soft selection score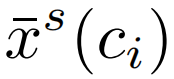 。
。
5.预测,结合classification score和selection score,生成untrimmed视频V的分类预测分数。对于hard selection,对每个分类的top-k个proposal的原始classification score,根据hard selection score取加权平均,再通过softmax得到预测分数,对于soft selection,利用学习的注意力权重,对soft classification score取加权平均得到预测分数。得到的预测分数使用交叉熵损失进行优化。
最新文章
- linux学习日记之老男孩
- pycharm快捷键 - 官方全
- 贪心+构造( Codeforces Round #344 (Div. 2))
- AjaxControlToolKit--TabContainer控件的介绍
- 浅议SNMP安全、SNMP协议、网络管理学习
- Apache Thrift学习之一(入门及Java实例演示)
- Integer对象
- RC2加密算法
- 【CSS3】---元素隐藏(是否占据空间、是否可点击)
- TD(TestDirector 8.0)在win7 ie8下无法用的解决方案:
- 插件和过滤器装饰器开发中的感悟-python-django
- Node Node
- Qt中提高sqlite的读写速度(使用事务一次性写入100万条数据)
- React.js再探(二)
- 酷伯伯实时免费HTTP代理ip爬取(端口图片显示+document.write)
- MySQL索引的原理,B+树、聚集索引和二级索引的结构分析
- rabbitmq 生产者 消费者(多个线程消费同一个队列里面的任务。) 一个通用rabbitmq消费确认,快速并发运行的框架。
- jQuery 实现复选框的全选与反选
- ZOJ3700 Ever Dream 2017-04-06 23:22 76人阅读 评论(0) 收藏
- linux命令(32):free命令