Kubernetes中pod UID的一个用法
2024-10-21 19:09:05
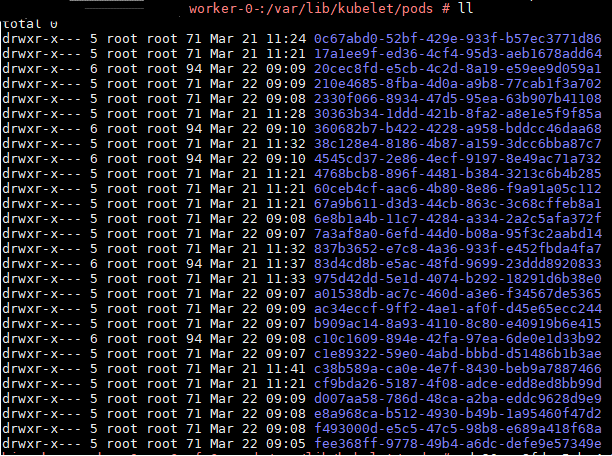
Kubernetes中每个工作Node的路径/var/lib/kubelet/pods里,含该Node上生成的每个pod的一些log文件。而该log文件的名字就是pod对应的UID,如下图所示(Node “worker-0”):
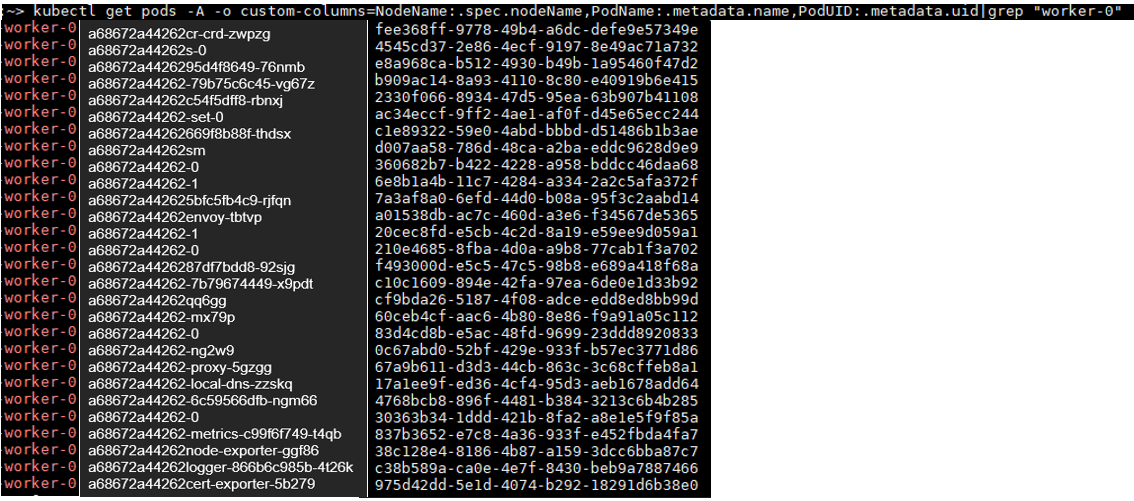
可以通过下述指令过滤出Node“worker-0”中的pod name和pod UID的对应关系:
> kubectl get pods -A -o custom-columns=NodeName:.spec.nodeName,PodName:.metadata.name,PodUID:.metadata.uid | grep "worker-0"
最后根据需要,定位到某个pod的container目录下查看log,例如:
/var/lib/kubelet/pods/60ceb4cf-aac6-4b80-8e86-f9a91a05c112/containers
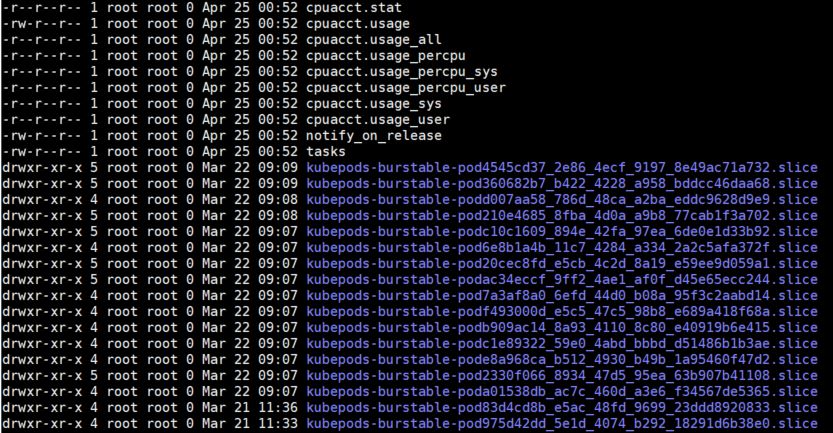
同样的方法,可以用于目录/sys/fs/cgroup/cpu/kubepods.slice/kubepods-burstable.slice的各个pod UID的cpu limit:
(以及目录/sys/fs/cgroup/memory/kubepods.slice/kubepods-burstable.slice的memory limit;以此类推,cgroup目录下的cpuset,pids等)
最新文章
- python 小程序大文件的拆分合并
- 数据库 MySQL安装图解
- Spring MVC4 纯注解配置教程
- 完整卸载 kubuntu-desktop from Ubuntu 14.04 LTS
- Nginx的配置文件
- 协作图 Collaboration diagram
- 从 github 执行 git clone 一个大的项目时提示 error: RPC failed
- oracle查询使用频率和磁盘消耗需要缓存大小
- iOS 网络与多线程--3.异步Get方式的网络请求(非阻塞)
- Android R.layout. 找不到已存在的布局文件
- [原]OS X 10.9 Mavericks - Virtual Serial Port Issues
- win7下wamp扩展memcache
- ASP.NET Core 依赖注入
- 笔记:I/O流-文件操作
- C#中委托。
- Linux(CentOS) 查看当前占用CPU或内存最多的K个进程
- 构建Maven父子工程
- python学习6---排序问题
- Leetcode 26. Remove Duplicates from Sorted Array (easy)
- Node KeyNote