<强化学习>基本概念
马尔可夫决策过程MDP,是强化学习的基础。
MDP --- <S,A,P,R,γ>
AGENT
STATE
ENV
REWARD ,由ENV给出。agent处于状态s下,采取action之后离开状态获得一个reward。即f:S x A --->R
所有强化学习问题解决的目标都可以描述成最大化累积奖励。All goals can be described by the maximisation of expected cumulative reward。即我们的目标是最大化Gt 。

ACTION ,离散分布,或者连续分布。
POLICY ,策略。 π :S x A --->[0,1]
|——Deterministic policy: a = π(s)
|——Stochastic policy: π(a|s) = P[At = a|St = s] //一个典型的随机策略 e-greedy policy derived from Q
VALUE ,a prediction of future reward; 形象地说AGENT.VALUE是agent对env的感觉,这样好,那样不好,对这个感到舒服,对那个感到upside
|——state value V(s),表示State好坏的量。V(s)的值代表了State s的好坏。好坏是对于未来reward累积而言的。
| 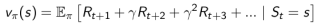
|——state-action value Q(s,a),
| 
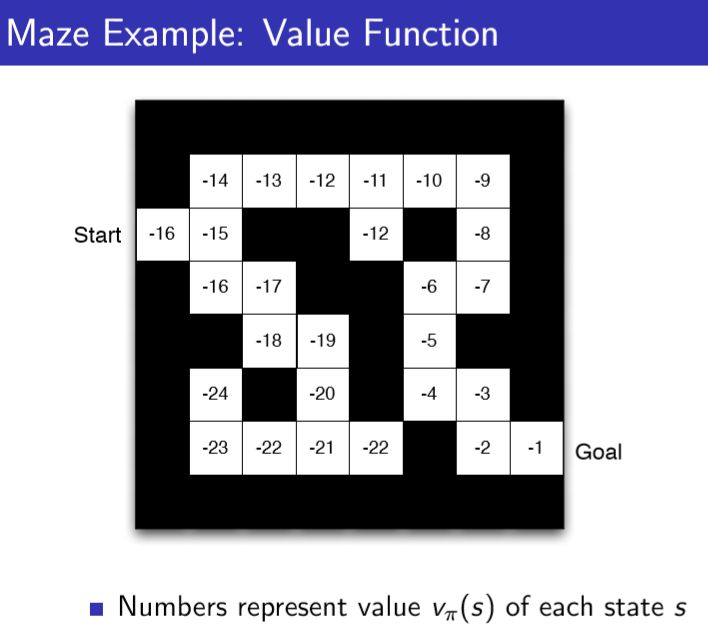
下面是一个”迷宫游戏“的例子:


以及算法中基本上用不到的概念Model,我们也给画出来:

History & Observation & State三个概念辩解:
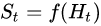
如下图中,红框为History,黑圈为Observation。
至于State,要看f()是如何定义的,St = f(Ht),f()是我们人为定义的。
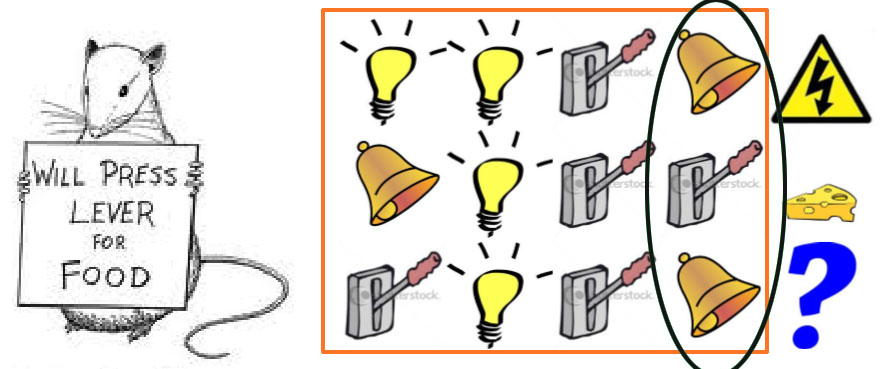
AGENT分为以下三类:

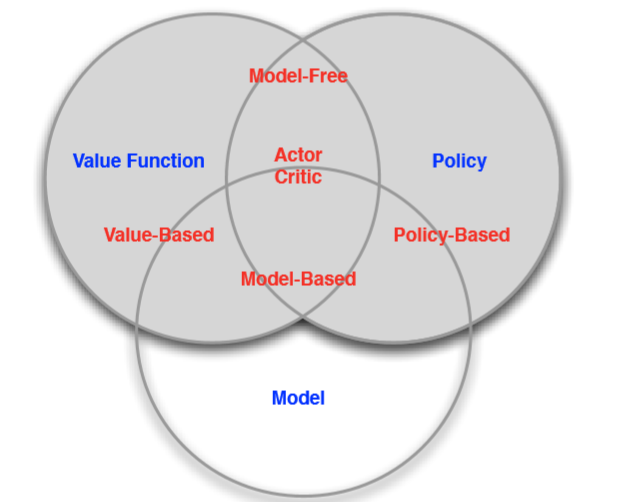
Model free和Model based辩解:
我们进一步把RL算法分为Model free和Model based两类。
Model based算法需要全知env,或者说已知Reward(s,a) for any (s,a)
Model free算法不需要全知env。
最新文章
- 设计模式之美:Visitor(访问者)
- 淘宝(阿里百川)手机客户端开发日记第十二篇 mysql的认识
- BZOJ4293 [PA2015]Siano(线段树)
- qt 汉化 国际化
- UVA11552:Fewest Flops
- JavaScript脚本放在哪里用户体验好
- wireshark 抓包过滤器使用
- 【公众号系列】超详细SAP HANA JOB全解析
- MySQL 1053错误 服务无法正常启动的解决方法
- 使用bat脚本部署hexo到coding和github
- 实践出真知-所谓"java没有指针",那叫做引用!
- Direct3D 11 Tutorial 4: 3D Spaces_Direct3D 11 教程4:3D空间
- php一些简单的作业题
- Robust Real-time Object Detection学习
- Linq测试/查看工具——LinqPad
- springmvc框架开发中解决产生的乱码情况
- 如何配置php客户端(phpredis)并连接Redis--华为DCS for Redis使用经验系列
- 使用powerdesinger逆向生成表结构
- wind10优化
- Codeforces Round #299 (Div. 2)A B C 水 dfs 二分