xpath解析案例
2024-08-31 02:11:39
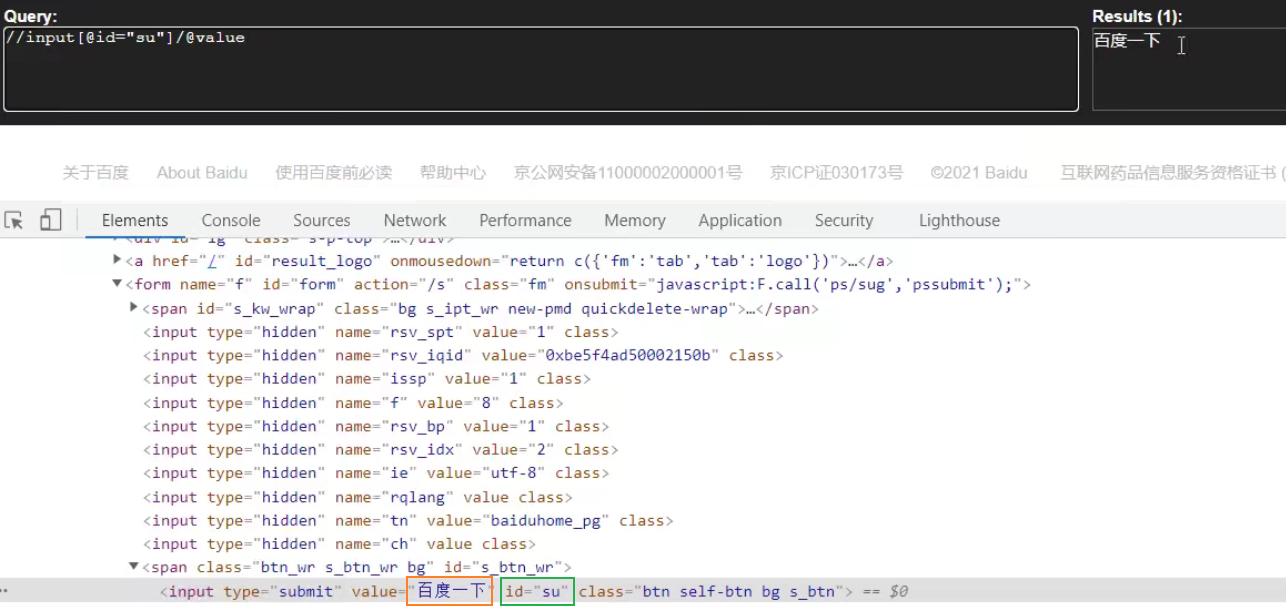
xpath解析百度页面的百度一下
# 1)获取网页的源码
# 2)解析的服务器响应的文件 etree.HTML , 用来解析字符串格式的HTML文档对象,将传进去的字符串转变成 element 对象
# 3)打印 import urllib.request # 请求地址
url = 'https://www.baidu.com/' # 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
} # 请求对象的定制
request = urllib.request.Request(url = url, headers = headers) # 模拟浏览器访问服务器
response = urllib.request.urlopen(request) # 获取网页源码
content = response.read().decode('utf-8') # 解析网页源码 来获取我们想要的数据
from lxml import etree # 解析服务器响应的文件
tree = etree.HTML(content) # 获取想要的数据 xpath的返回值是一个列表类型的数据
result = tree.xpath('//input[@id="su"]/@value')[0] print(result)

最新文章
- C#使用ADO.NET访问数据库(一)
- hive 复杂类型
- bzoj1091: [SCOI2003]切割多边形
- [译] 企业级 OpenStack 的六大需求(第 1 部分):API 高可用、管理和安全
- XSS代码触发条件,插入XSS代码的常用方法
- HM必修1
- twitter storm 源码走读之5 -- worker进程内部消息传递处理和数据结构分析
- 静态Web开发 JavaScript
- CSS围住浮动元素的三种方法
- 如何在CMD下运用管理员权限
- JavaScript基础一(js基础函数与运算符)
- PHP获取一周的日期
- Workflow相关表简单分析
- getWidth()和getMeasuredWidth()的区别
- 谷歌浏览器安装octotree插件
- docker 常用操作
- 【JEECG技术文档】JEECG高级查询构造器使用说明
- 中断标志位 IRQF_ONESHOT
- Mybatis学习(1)
- SpringBoot中使用Redis