【C# IO 操作 】编程对缓冲区的理解
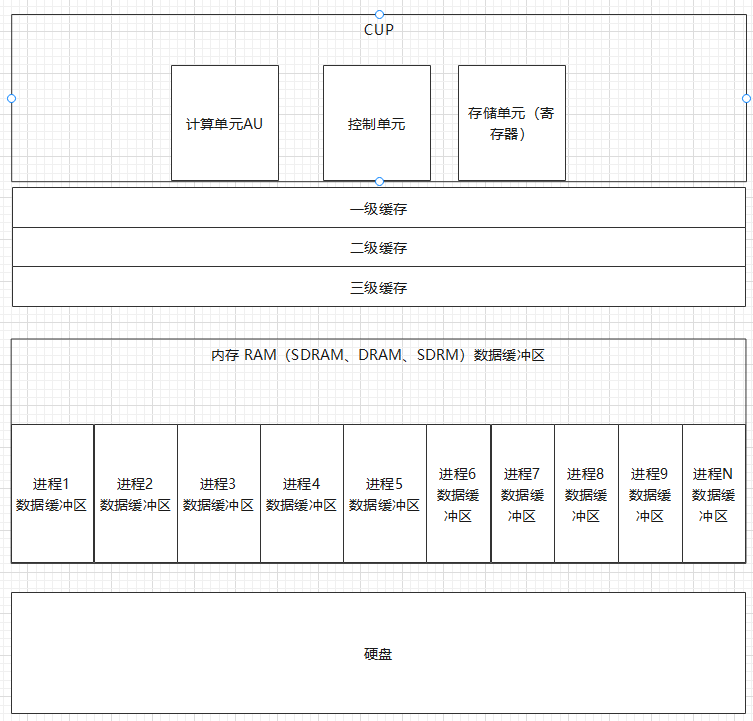
什么是缓冲区
缓冲区又称为缓存,它是内存空间的一部分。也就是说,在内存空间中预留了一定的存储空间,这些存储空间用来缓冲输入或输出的数据,这部分预留的空间就叫做缓冲区。
缓冲区根据其对应的是输入设备还是输出设备,分为输入缓冲区和输出缓冲区。我们可以把内存看作数据缓存区.
为什么要引入缓冲区
我们为什么要引入缓冲区呢?
比如我们从磁盘里取信息,我们先把读出的数据放在缓冲区,计算机再直接从缓冲区中取数据,等缓冲区的数据取完后再去磁盘中读取,这样就可以减少磁盘的读写次数,再加上计算机对缓冲区的操作大大快于对磁盘的操作,故应用缓冲区可大大提高计算机的运行速度。
又比如,我们使用打印机打印文档,由于打印机的打印速度相对较慢,我们先把文档输出到打印机相应的缓冲区,打印机再自行逐步打印,这时我们的CPU可以处理别的事情。
现在您基本明白了吧,缓冲区就是一块内存区,它用在输入输出设备和CPU之间,用来缓存数据。它使得低速的输入输出设备和高速的CPU能够协调工作,避免低速的输入输出设备占用CPU,解放出CPU,使其能够高效率工作。
缓冲区的类型
缓冲区 分为三种类型:全缓冲、行缓冲和不带缓冲。
1、全缓冲
在这种情况下,当填满标准I/O缓存后才进行实际I/O操作。全缓冲的典型代表是对磁盘文件的读写。
2、行缓冲
在这种情况下,当在输入和输出中遇到换行符时,执行真正的I/O操作。这时,我们输入的字符先存放在缓冲区,等按下回车键换行时才进行实际的I/O操作。典型代表是键盘输入数据。
3、不带缓冲
也就是不进行缓冲,标准出错情况stderr是典型代表,这使得出错信息可以直接尽快地显示出来。
缓冲区的刷新
下列情况会引发缓冲区的刷新:
1、缓冲区满时;
2、执行flush语句;
3、执行end语句;
4、关闭文件。
可见,缓冲区满或关闭文件时都会刷新缓冲区,进行真正的I/O操作。
链接:https://www.zhihu.com/question/26190832/answer/825301105
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
以硬盘读写操作为例的完整解释:
背景知识一:我们现在的计算机、手机都是冯诺依曼架构,CPU只能操作内存中的数据,无法直接操作硬盘上的数据。更多关于现代计算机的架构,有兴趣的可以看我的专栏文章:

背景知识二:硬盘上的数据,最小读写单位是扇区(Sector)。老式硬盘上一个扇区是512字节,现代硬盘上一个扇区是4K字节。计算机不能以单个字节为单位访问硬盘上的数据。现在很常见的固态硬盘,物理上最小读写单位是页(Page),但大部分固态硬盘通过主控芯片模拟传统硬盘的扇区来进行读写。现代硬盘常用的LBA(Logical Block Addressing,逻辑块寻址)寻址方式,是把硬盘上的扇区分配从0~N-1的编号(N为硬盘上所有可用扇区数量)。
介绍完背景,假设某个应用现在需要读取一个大小为15K字节的文件A。操作系统和文件系统会把文件路径转换为具体的LBA地址,可能最终转换为读取硬盘上从B扇区开始的4个扇区(按照每个扇区4KB计算)。然而,前面我们说了,CPU并不能直接访问硬盘,因此需要先把这四个扇区的数据,传输到内存中。存放这四个扇区数据的内存,就是Buffer。忽略CPU内部的Cache机制,CPU现在可以对这一段内存以字节为单位进行操作,在所有操作完成后,Buffer所占用的内存会被回收。
写入则是相反,应用程序需要先在内存中准备好这四个扇区的数据,然后硬盘控制器会把这些数据原样写入到硬盘对应的扇区上。同样的,写入完成后Buffer所占用的内存也会被回收。
除了用于临时存放IO设备上的数据,Buffer通常还有其它几种用途:
- 把多次小量数据传输合并为更少次数的批量数据传输, 减少传输过程本身的额外开销;
- 为两个不能直接交换数据的传输进程的提供临时中介存储;
- 确保组成单次传输规定的最小单位
- 对大块数据进行组装或者分解
如果这个应用需要频繁读取文件A,每次都从硬盘读取显然会很慢。如果第一次读取完成后,不直接清空Buffer所占用的内存,而是把这段内存保留下来或者先复制到其它内存地址,以后对这个文件的读取就可以直接从内存访问,无需再次从硬盘读取,应用程序的性能就会快很多。这才是Cache,严谨点来说,这是Read Cache,所以台湾把Cache翻译为“快取”,更多的是指Read Cache。但是,并不是所有从硬盘上读取到Buffer的数据都会被Cache的,例如复制一个包含多个数GB的视频文件的文件夹,通常只有这个文件夹的数据会被Cache,而每个具体的视频文件的数据都不会进入Cache。
有Read Cache自然也有Write Cache。还是这个占用四个扇区的文件,假如应用程序需要先更改第一个扇区的内容并写入硬盘,过一段时间再更改第三个扇区的内容并写入硬盘。这样需要对硬盘进行两次写入。但如果第一次应用要求写入的时候,操作系统只是把这个文件的数据写入到内存中并返回写入完成的响应,但数据并没有真正写入硬盘。等收到后续写入请求的时候才真正写入硬盘,则只需要进行一次写入。通过这样的方式,根据实际情况可能实现:
- 应用程序无需等待真正的写入完成即可继续后续操作,提高应用程序性能;
- 减少写入次数;
- 把多个小数据量的写入合并成一个大数据量的写入;
- 把多个随机写入转换为持续写入。
这几种情况中的一种或者多种,从而提高IO性能。但是,对于首次写入来说,这个性能是必然更低的——假设直接写入需要0.02秒,因为要等待后续的写入请求,可能从发起首次写入请求,到数据真正写入硬盘用了0.5秒。这就是国内把Cache翻译为“缓存”的原因——暂缓存储。所以其实“缓存”和“快取”都只是表达了一半的意思,不存在说“快取”比“缓存”翻译的更好——虽然大部分时候Read Cache比Write Cache更常见。
需要另外提一下的是,Write Cache同时也是Buffer的一种形式,在数据写入到硬盘前,是不能被回收的。
最后,Read Cache和Write Cache并不是严格分离的。很多时候Write Cache同时也可以作为Read Cache使用,但在分布式系统中,则需要考虑Cache一致性的问题。
最新文章
- Android Studio开发RecyclerView遇到的各种问题以及解决(二)
- Aspen 安装
- 0004 plsql的安装
- [NOIP2012] 提高组 洛谷P1084 疫情控制
- 原生js实现简单打字机效果
- POJ2699 The Maximum Number of Strong Kings(最大流)
- 说说php取余运算(%)的那点事
- nyoj 括号匹配
- 除去内容中的HTML代码方法
- 安卓的UI界面开发(初学者推荐)
- Unity 利用UGUI打包图集,动态加载sprite资源
- css之positon与z-index
- Linux下的Hadoop安装(本地模式)
- hdoj:2050
- (GoRails)使用vue和Vuex管理嵌套的JavaScript评论, 使用组件vue-map-field
- Pycharm中安装package出现microsoft visual c++ 14.0 is required问题解决办法
- GAE、SAE与BAE的对比分析(百度云)
- SQL Server 如何添加删除外键、主键,以及更新自增属性
- Python初学者第十二天 购物车程序小作业
- "群英队"电梯演讲