第二十天python3 正则表达式
正则表达式
Regular Expression,缩写为regex、regexp、RE等;
分类
1、BRE 基本正则表达式,grep、sed、vi等软件支持,vim有扩展;
2、ERE 扩展正则表达式,egrep(grep -E)、sed -r等;
3、PCRE 几乎所有高级语言都是PCRE的方言或者变种;“grep -P” 使grep支持perl语言的正则表达式语法;
基本语法
元字符(metacharacter)
. 匹配除换行符外任意一个字符;
[abc] 字符集合,只能表示一个字符位置,匹配所包含的任意一个字符;
[^abc] 字符集合,只能表示一个字符位置,匹配除去集合内字符的任意一个字符;
[a-z] 字符范围,也是一个集合,表示一个字符位置,匹配所包含的任意一个字符;
[^a-z] 字符范围,也是一个集合,表示一个字符位置,匹配除去集合内字符的任意一个字符;
\b 匹配单词的边界;
\B 不匹配单词边界;
\d [0-9]匹配1位数字;
\D [^0-9]匹配1位非数字
\s 匹配1位空白字符,包括换行符、制表符、空格;[\f\r\n\t\v]
\S 匹配1位非空白字符;
\w 匹配[a-zA-Z0-9_],包括中文的字
\W 匹配\w之外的字符
. 匹配除换行符外的任意一个字符

这个点基本上代表所有了;属于贪婪匹配;
[abc] 字符集合,只能表示一个字符位置,匹配所包含的任意一个字符;

如果要匹配dream文件中的av关键字,可以这么写:
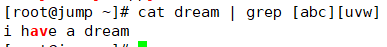
[^abc] 字符集合,只能表示一个字符位置,匹配除去集合内字符的任意一个字符;

[a-z] 字符范围,也是一个集合,表示一个字符位置,匹配所包含的任意一个字符;


[^a-z] 字符范围,也是一个集合,表示一个字符位置,匹配除去集合内字符的任意一个字符;

\b 匹配单词的边界

\B 不匹配单词边界;

可以理解为过滤不是以e结尾e;
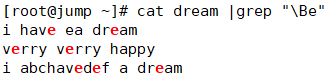
可以理解为过滤不是以e开头的e;

\d [0-9]匹配1位数字;
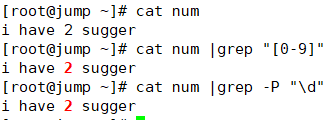
\D [^0-9]匹配1位非数字

\s \S \w \W 这4个涉及到不可见字符,不太好展示,知道这个意思就好;
转义
凡是在正则表达式中有特殊意义的符号,如果想使用它的本意,请使用\转义,反斜杠自身得使用\\;
\r 、\n在转义后代表回车、换行;
重复
* 表示前面的正则表达式会重复0次或多次;
+ 表示前面的正则表达式重复至少1次;
? 表示前面的正则表达式会重复0次;
{n} 重复固定的n次
{n,} 重复至少n次
{n,m} 重复n到m次
#举例说明
# 使用的测试文件
abcd
abbcd
a
ac
ae
ba
bat

表示重复"b"字母0次或者多次,也就是说字母"a"的旁边这个"b"字母是可以不存在的;

表示字母"b"至少要出现1次;也就是b>=1;

表示,字母"v"可以不用出现,但是如果文件中有"vb"、"vvb"关键字,则该正则表达式只匹配一字母"v";
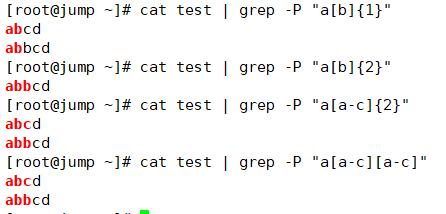
这地方可以这么理解,首先要记住一个核心"对于元字符的匹配,只表示一个字符的位置",所以:
a[b]{1} <==> a[b]
a[b]{2} <==> a[b][b]
a[a-c]{2} <==> a[a-c][a-c]
...以此类推...
{n,}、{n,m}也是此类道理;
# 匹配国内座机:grep -P "\d{3,4}-\d{7,8}"
# 匹配国内手机号:grep -P "\d{11}"
分组
x|y 匹配x或者y
(pattern) 使用小括号指定一个子表达式,也叫分组,捕获后会自动分配组号从1开始,可以改变优先级;
\数字 匹配对应的分组
(?:pattern) 如果仅仅为了改变优先级,就不需要捕获分组;
(?<name>exp)(?'name'exp) 分组捕获,但是可以通过name访问分组,Python语法必须是(?P<name>exp);
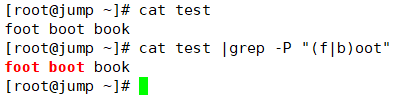
从上图可以看出,通过加竖线的方式,匹配到了foot和boot;
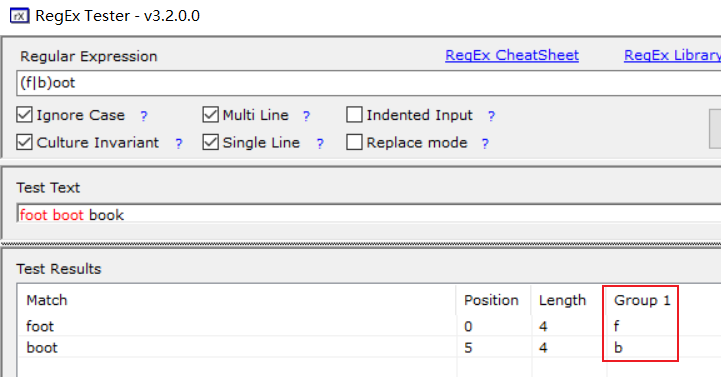
由于grep不能直观的展示正则表达式分组的概念,只能借助工具RegEx Tester来实现,从上图可以看出,对该表达式分了一个组,组成员时f和b;可以看到,分组的代号是1,如果要匹配该分组\1即可;
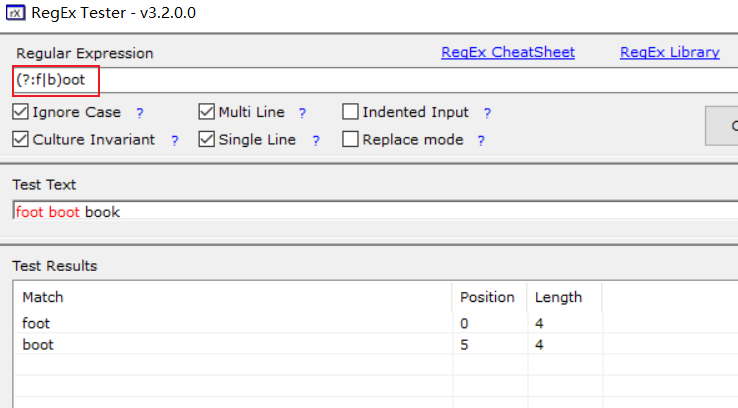
如果不需要捕获该分组,则在分组内加?:即可;从上图可以看出,原来有分组的地方,没有该列了;
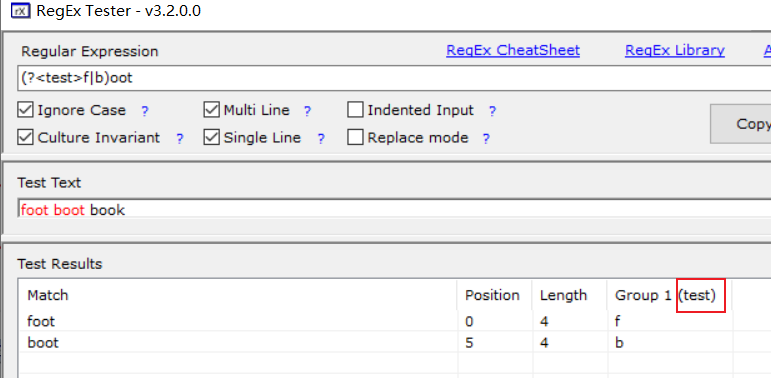
如果不知道该分组的分组号,可以给该分组起个名字;
零宽断言
(?=exp) 零宽度正预测先行断言,断言exp一定在匹配的右边出现,也就是说断言后面一定跟个exp;
(?<=exp) 零宽度正回顾后发断言,断言exp一定在匹配的左边出现,也就是说前面一定有个exp前缀;

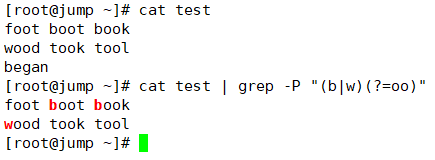
上图所表示的意思就是,断定b或者w后面有"oo";换句话说就是我断定我所匹配的b或w后面有oo;
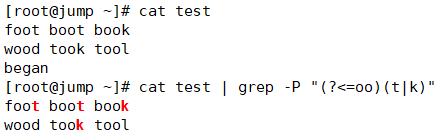
上图所表示的意思就是,我断定我所匹配的t或k的前面有oo;
负向零宽断言
(?!exp) 零宽度负预测先行断言,断言exp一定不会出现在右侧,也就是说断言后面一定不是exp;
(?<!exp) 零宽度负回顾后发断言,断言exp一定不能出现在左侧,也就是说断言前面一定不能是exp;
(?#comment) 注释;示例:f(?=oo)(?#这个后断言不捕获)
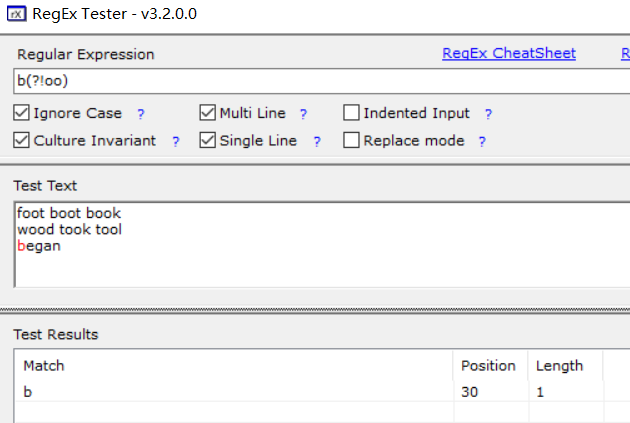
"grep -P"竟然不支持,只能软件展示了,上图中的意思是,断定匹配的字母b右边没有oo;

上图中的意思为,断定匹配的字母n的左边没有oo;
贪婪与非贪婪
默认是贪婪模式,也就是说尽量多匹配更长的字符串;
非贪婪很简单,在重复的符号后面加上一个?问号,就尽量的少匹配了;
*? 匹配任意次,但是尽可能少重复;
+? 匹配至少1次,但尽可能少重复;
?? 匹配0次或1次,但尽可能少重复;
{n,}? 匹配至少n次,但尽可能少重复;
{n,m}? 匹配至少n次,至多m次,但尽可能少重复;


引擎选项
代码 说明 Python
lgnoreCase 匹配时忽略大小写 re.l、re.lGNORECASE;
Singleline 单行模式,可以匹配所有字符,包括\n; re.S、re.MULTILINE
Multiline 多行模式,^行首,$行尾; re.M、re.MULTILINE
lgnorePatternWhitespace 忽略表达式中的空白字符,如果要使用空白字符用转义,#可以用来做注释; re.X、re.VERBOSE
单行模式
. 可以匹配所有字符,包括换行符;
^ 表示整个字符串的开头,$ 整个字符串的结尾
多行模式
. 可以匹配除了换行符之外的字符;
^ 表示行首,$ 表示行尾;
^ 表示真个字符串的开始,$ 表示真个字符串的结尾;开始指的是\n后紧接着下一个字符,结束指的是\n前的字符;
可以认为,单行模式就如同看穿了换行符,所有文本就是一个常常的只有一行的字符串,所有^就是这一行字符串的行首,$就是这一行的行尾;
多行模式,无法穿透换行符,^和$还是行首行尾的意思,只不过限于每一行;
注意:注意字符串中看不见的换行符,\r\n会影响e$的测试;e$只能匹配e\n;
\d 1位数字
[1-9]?\d 1-2位数字
^([1-9]\d\d?|\d) 1-3位数字
^([1-9]\d\d?|\d)$ 1-3位数的行
^([1-9]\d\d?|\d)\r?$ 1-3位数的行,并且忽略回车
^([1-9]\d\d?|\d)(?!\d) 数字开头1-3位数,并且之后不能是数字
ip地址匹配分析:
可以将ip地址拆开来看
000--199 ---> [0-1]?[0-9]?[0-9]
200--249 ---> 2[0-4][0-9]
250--255 ---> 25[0-5]
下面两种形式其实一样,仅仅是把[0-9]换成了\d;
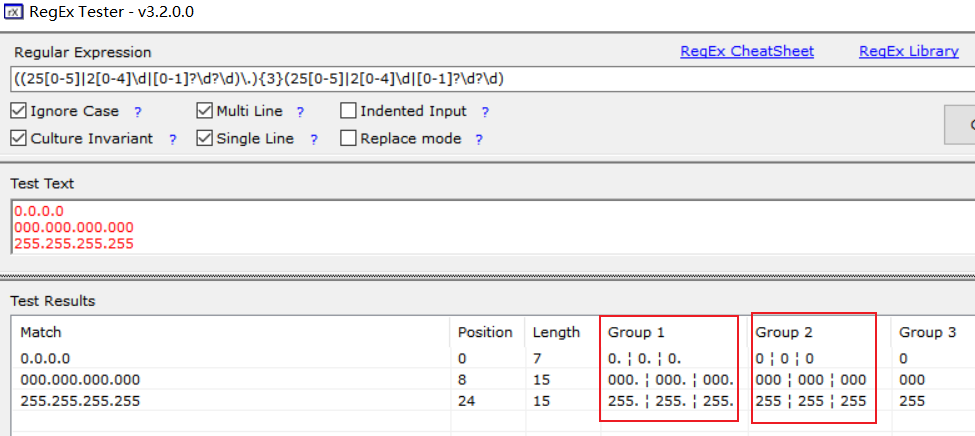
(?:(25[0-5]|2[0-4][0-9]|[0-1]?[0-9]?[0-9])\.){3}(25[0-5]|2[0-4][0-9]|[0-1]?[0-9]?[0-9])
(?:(25[0-5]|2[0-4]\d|[0-1]?\d?\d)\.){3}(25[0-5]|2[0-4]\d|[0-1]?\d?\d)
ip地址分析这地方用?:是因为产生了两个差不多一样的分组,所以需要放弃一个;
选出含有ftp的链接,且文件类型是gz或者xz的文件名:
#示例文件内容
ftp://ftp.astron.com/pub/file/file-5.14.tar.gz
ftp://ftp.gmplib.org/pub/gmp-5.1.2/gmp-5.1.2.tar.xz
ftp://ftp.vim.org/pub/vim/unix/vim-7.3.tar.bz2
http://anduin.linuxfromscnatch.org/sources/LFS/lfs-packages/conglomeration//iana-etc/iana-etc-2.30.tar.bz2
http://anduin.linuxfromscnatch.org/sources/other/udev-lfs-205-l.tar.bz2
http://download.savannah.gnu.org/releases/libpipeline/libpipeline-1.2.4.tar.gz
http://download.savannah.gnu.org/releases/man-db/man-db-2.6.5.tar.xz
http://download.savannah.gnu.org/releases/sysvinit/sysvinit-2.88dsf.tar.bz2
http://ftp.altlinux.org/pub/people/legion/kbd/kbd-1.15.5.tar.gz
http://mirror.hust.edu.cn/gnu/autoconf/autoconf-2.69.tar.xz
http://mirror.hust.edu.cn/gnu/automake/automake-1.14.tar.xz
正则表达式:
取出包含gz|xz后缀文件的路径(三种方式):
.*ftp.*\.(?:gz|xz)
ftp.*/(.*(?:gz|xz))
.*ftp.*/([^/]*\.(?:gz|xz))
取出以gz|xz结尾的文件名:
(?<=.*ftp.*/)[^/]*\.(?:gz|xz)
匹配邮箱地址:
示例文件:
test@hot-mail.com
v-ip@163.com
web.manager@zhide.com.cn
super.user@google.com
a@w-a-com
1072051214@qq.com
匹配:
grep -P "([a-zA-Z-0-9-\.]+)@([\w-\.]+\.[\w-]+)"
grep -P "\w[-.\w]*@[\w-]+(\.[\w-]*)+"
html提取
grep -P "<[^<>]+>(.*)<[^<>]+"
如果要匹配标记a
grep -P "<(\w+)\s+[^<>]+>(.*)(</\1>)"
URL提取:
(\w+)://([^\s]+)
身份证验证:
身份证验证需要使用公式计算,最严格的应该是实名认证,这里简单写一个;
\d{17}[0-9xX]|\d{15}
最新文章
- iOS 10 都有什么改变?
- JUnit操作指南-批量执行单元测试(将多个测试类捆绑在一起执行)
- MySQL增加列,修改列名、列属性,删除列
- sql server 对象资源管理器(一)
- JAVA架构师要求
- Jenkins插件及 测试源码
- C++——string类和标准模板库
- CentOS6.X安装vsftpd服务
- 使用 github.io 免费建站
- .Net中的Socket通讯
- 使用netbeans 搭建 JSF+SPRING 框架
- A(51)和C(51)相互调用
- linux----命令替换
- 使用Fiddler伪造服务端返回数据,绕过软件试用期验证
- Redis简介四
- redis的架构(一)
- Mongodb常用增删改查语法
- asp.net webapi 404/或无效控制器/或无效请求 截取处理统一输出格式
- openvswitch vlan下的虚拟机与物理机通信
- JSP基本_JSTL