转:locality sensitive hashing

Motivation
The task of finding nearest neighbours is very common. You can think of applications like finding duplicate or similar documents, audio/video search. Although using brute force to check for all possible combinations will give you the exact nearest neighbour but it’s not scalable at all. Approximate algorithms to accomplish this task has been an area of active research. Although these algorithms don’t guarantee to give you the exact answer, more often than not they’ll be provide a good approximation. These algorithms are faster and scalable.
Locality sensitive hashing (LSH) is one such algorithm. LSH has many applications, including:

- Near-duplicate detection: LSH is commonly used to deduplicate large quantities of documents, webpages, and other files.
- Genome-wide association study: Biologists often use LSH to identify similar gene expressions in genome databases.
- Large-scale image search: Google used LSH along with PageRank to build their image search technology VisualRank.
- Audio/video fingerprinting: In multimedia technologies, LSH is widely used as a fingerprinting technique A/V data.
In this blog, we’ll try to understand the workings of this algorithm.
General Idea
LSH refers to a family of functions (known as LSH families) to hash data points into buckets so that data points near each other are located in the same buckets with high probability, while data points far from each other are likely to be in different buckets. This makes it easier to identify observations with various degrees of similarity.
Finding similar documents
Let’s try to understand how we can leverage LSH in solving an actual problem. The problem that we’re trying to solve:
Goal: You have been given a large collections of documents. You want to find “near duplicate” pairs.
In the context of this problem//////再次问题的背景下, we can break down the LSH algorithm into 3 broad steps:
- Shingling
- Min hashing
- Locality-sensitive hashing
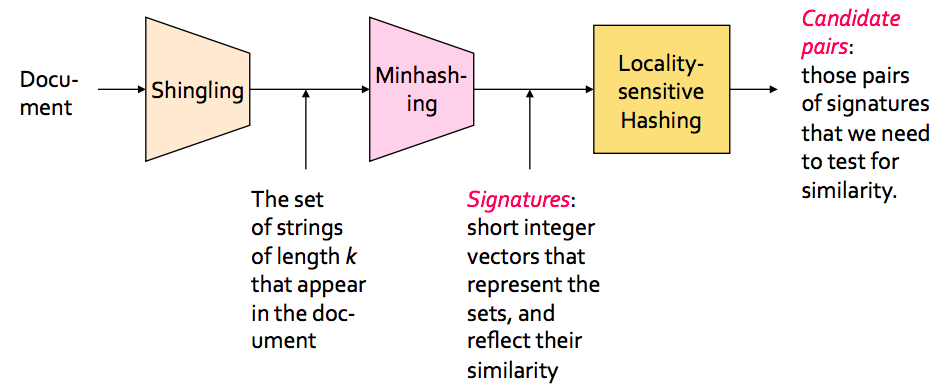
Shingling
In this step, we convert each document into a set of characters of length k (also known as k-shingles or k-grams). The key idea is to represent each document in our collection as a set of k-shingles.
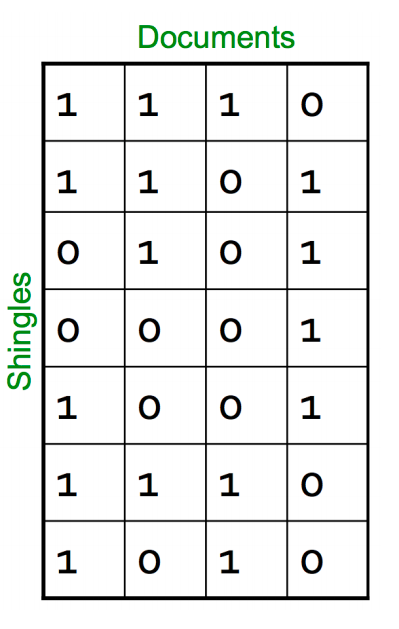
For ex: One of your document (D): “Nadal”. Now if we’re interested in 2-shingles, then our set: {Na, ad, da, al}. Similarly set of 3-shingles: {Nad, ada, dal}.
- Similar documents are more likely to share more shingles
- Reordering paragraphs in a document of changing words doesn’t have much affect on shingles
- k value of 8–10 is generally used in practice. A small value will result in many shingles which are present in most of the documents (bad for differentiating documents)
Jaccard Index
We’ve a representation of each document in the form of shingles. Now, we need a metric to measure similarity between documents. Jaccard Index is a good choice for this. Jaccard Index between document A & B can be defined as:
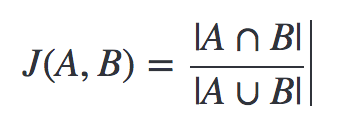
It’s also known as intersection over union (IOU).
A: {Na, ad, da, al} and B: {Na, ad, di, ia}.
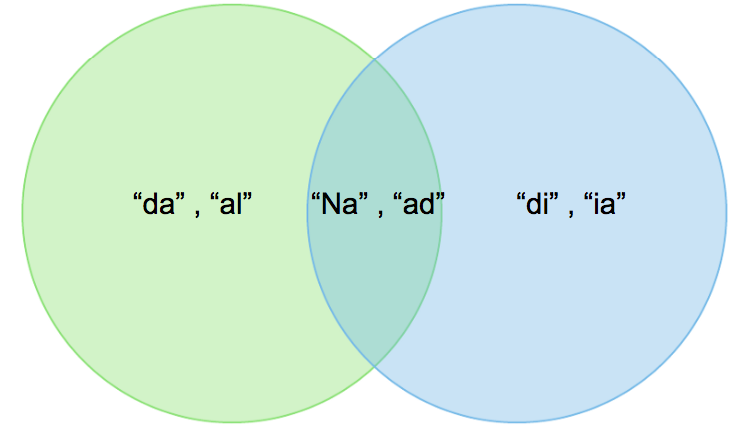
Jaccard Index = 2/6
Let’s discuss 2 big issues that we need to tackle:
Time complexity
Now you may be thinking that we can stop here. But if you think about the scalability, doing just this won’t work. For a collection of n documents, you need to do n*(n-1)/2 comparison, basically O(n²). Imagine you have 1 million documents, then the number of comparison will be 5*10¹¹ (not scalable at all!).
Space complexity
The document matrix is a sparse matrix and storing it as it is will be a big memory overhead. One way to solve this is hashing.
Hashing
The idea of hashing is to convert each document to a small signature using a hashing function H*.* Suppose a document in our corpus is denoted by d. Then:
- H(d) is the signature and it’s small enough to fit in memory
- If similarity(d1,d2) is high then *Probability(H(d1)==H(d2))* is high
- If similarity(d1,d2) is low then *Probability(H(d1)==H(d2))* is low
Choice of hashing function is tightly linked to the similarity metric we’re using. For Jaccard similarity the appropriate hashing function is min-hashing.
Min hashing
This is the critical and the most magical aspect of this algorithm so pay attention:
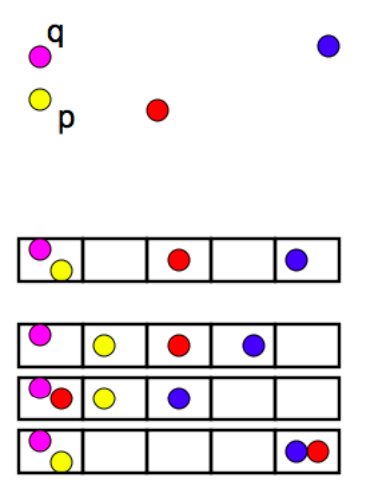
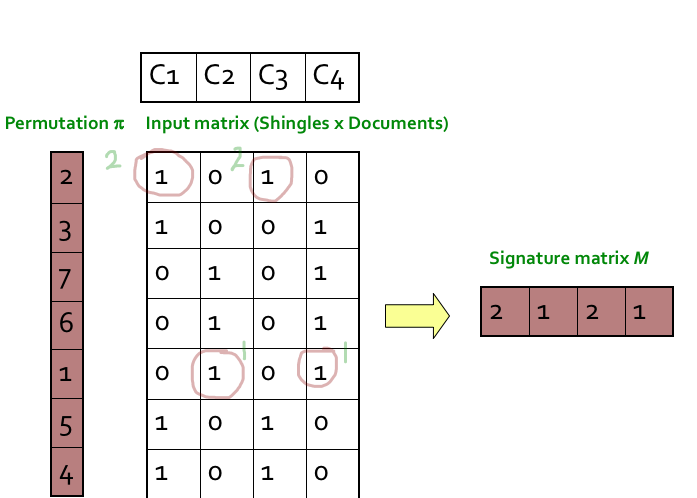
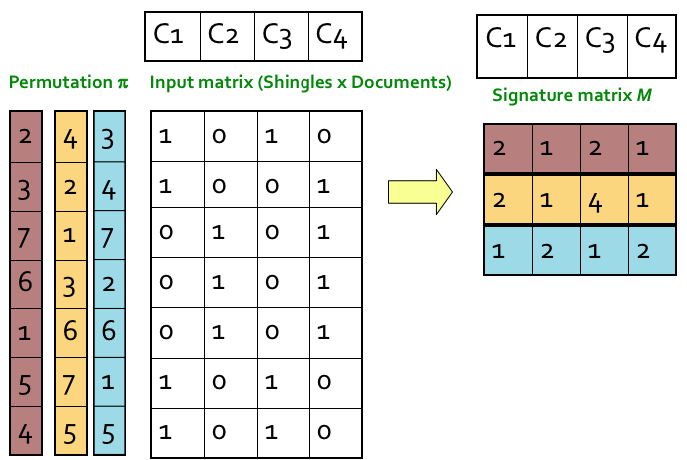
Step 1: Random permutation (π) of row index of document shingle matrix.

////////对行进行随机排列
Step 2: Hash function is the index of the first (in the permuted order) row in which column C has value 1. Do this several time (use different permutations) to create signature of a column.
第2步:哈希函数是列C值为1的第一行(按顺序排列)的索引。这样做几次(使用不同的排列)来创建一个列的签名。
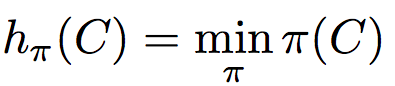
////这个图根本看不懂
最新文章
- [poj1679]The Unique MST(最小生成树)
- [转载]TFS源代码管理
- git 打标签并推送tag到托管服务器
- directive中的参数详解
- RDP协议
- ASP.NET MVC 应用程序的安全性,看一眼你就会了
- hdu 2256 Problem of Precision 构造整数 + 矩阵快速幂
- Noah的学习笔记之Python篇:函数“可变长参数”
- XP 安装
- 有关android 应用的plugin框架调研
- .NET(c#) 移动开发平台 - Smobiler(1)
- C#学习笔记-组合模式
- python3 爬取百合网的女人们和男人们
- java 随机数高效生成
- Django相关问题
- Restful levels and Hateoas
- Webpack + vue 搭建
- fedora 28 , firewalld 防火墙控制,firewall-cmd 管理防火墙规则
- Android入门笔记
- python小数据池概念以及具体范围