分布式图数据库 Nebula Graph 的 Index 实践

导读
索引是数据库系统中不可或缺的一个功能,数据库索引好比是书的目录,能加快数据库的查询速度,其实质是数据库管理系统中一个排序的数据结构。不同的数据库系统有不同的排序结构,目前常见的索引实现类型如 B-Tree index、B+-Tree index、B*-Tree index、Hash index、Bitmap index、Inverted index 等等,各种索引类型都有各自的排序算法。
虽然索引可以带来更高的查询性能,但是也存在一些缺点,例如:
- 创建索引和维护索引要耗费额外的时间,往往是随着数据量的增加而维护成本增大
- 索引需要占用物理空间
- 在对数据进行增删改的操作时需要耗费更多的时间,因为索引也要进行同步的维护
Nebula Graph 作为一个高性能的分布式图数据库,对于属性值的高性能查询,同样也实现了索引功能。本文将对 Nebula Graph的索引功能做一个详细介绍。
图数据库 Nebula Graph 术语
开始之前,这里罗列一些可能会使用到的图数据库和 Nebula Graph 专有术语:
- Tag:点的属性结构,一个 Vertex 可以附加多种 tag,以 TagID 标识。(如果类比 SQL,可以理解为一张点表)
- Edge:类似于 Tag,EdgeType 是边上的属性结构,以 EdgeType 标识。(如果类比 SQL,可以理解为一张边表)
- Property:tag / edge 上的属性值,其数据类型由 tag / edge 的结构确定。
- Partition:Nebula Graph 的最小逻辑存储单元,一个 StorageEngine 可包含多个 Partition。Partition 分为 leader 和 follower 的角色,Raftex 保证了 leader 和 follower 之间的数据一致性。
- Graph space:每个 Graph Space 是一个独立的业务 Graph 单元,每个 Graph Space 有其独立的 tag 和 edge 集合。一个 Nebula Graph 集群中可包含多个 Graph Space。
- Index:本文中出现的 Index 指 nebula graph 中点和边上的属性索引。其数据类型依赖于 tag / edge。
- TagIndex:基于 tag 创建的索引,一个 tag 可以创建多个索引。目前(2020.3)暂不支持跨 tag 的复合索引,因此一个索引只可以基于一个 tag。
- EdgeIndex:基于 Edge 创建的索引。同样,一个 Edge 可以创建多个索引,但一个索引只可以基于一个 edge。
- Scan Policy:Index 的扫描策略,往往一条查询语句可以有多种索引的扫描方式,但具体使用哪种扫描方式需要 Scan Policy 来决定。
- Optimizer:对查询条件进行优化,例如对 where 子句的表达式树进行子表达式节点的排序、分裂、合并等。其目的是获取更高的查询效率。
索引需求分析
Nebula Graph 是一个图数据库系统,查询场景一般是由一个点出发,找出指定边类型的相关点的集合,以此类推进行(广度优先遍历)N 度查询。另一种查询场景是给定一个属性值,找出符合这个属性值的所有的点或边。在后面这种场景中,需要对属性值进行高性能的扫描,查出与此属性值对应的边或点,以及边或点上的其它属性。为了提高属性值的查询效率,在这里引入了索引的功能。对边或点的属性值进行排序,以便快速的定位到某个属性上。以此避免了全表扫描。
可以看到对图数据库 Nebula Graph 的索引要求:
- 支持 tag 和 edge 的属性索引
- 支持索引的扫描策略的分析和生成
- 支持索引的管理,如:新建索引、重建索引、删除索引、list | show 索引等。
系统架构概览
图数据库 Nebula Graph 存储架构
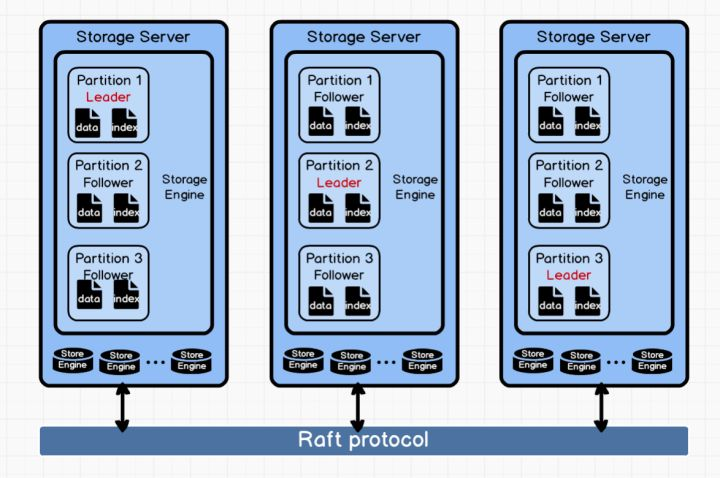
从架构图可以看到,每个Storage Server 中可以包含多个 Storage Engine, 每个 Storage Engine中可以包含多个Partition, 不同的Partition之间通过 Raft 协议进行一致性同步。每个 Partition 中既包含了 data,也包含了 index,同一个点或边的 data 和 index 将被存储到同一个 Partition 中。
业务具体分析
数据存储结构
为了更好的描述索引的存储结构,这里将图数据库 Nebula Graph 原始数据的存储结构一起拿出来分析下。
点的存储结构
点的 Data 结构

点的 Index 结构

Vertex 的索引结构如上表所示,下面来详细地讲述下字段:
PartitionId:一个点的数据和索引在逻辑上是存放到同一个分区中的。之所以这么做的原因主要有两点:
- 当扫描索引时,根据索引的 key 能快速地获取到同一个分区中的点 data,这样就可以方便地获取这个点的任何一种属性值,即使这个属性列不属于本索引。
- 目前 edge 的存储是由起点的 ID Hash 分布,换句话说,一个点的出边存储在哪是由该点的 VertexId 决定的,这个点和它的出边如果被存储到同一个 partition 中,点的索引扫描能快速地定位该点的出边。
IndexId:index 的识别码,通过 indexId 可获取指定 index 的元数据信息,例如:index 所关联的 TagId,index 所在列的信息。
Index binary:index 的核心存储结构,是所有 index 相关列属性值的字节编码,详细结构将在本文的 #Index binary# 章节中讲解。
VertexId:点的识别码,在实际的 data 中,一个点可能会有不同 version 的多行数据。但是在 index 中,index 没有 Version 的概念,index 始终与最新 Version 的 Tag 所对应。
上面讲完字段,我们来简单地实践分析一波:
假设 PartitionId 为 _100,TagId 有 tag_1 和 tag_2,_其中 tag_1 包含三列 :col_t1_1、col_t1_2、col_t1_3,tag_2 包含两列:col_t2_1、col_t2_2。
现在我们来创建索引:
- i1 = tag_1 (col_t1_1, col_t1_2) ,假设 i1 的 ID 为 1;
- i2 = tag_2(col_t2_1, col_t2_2), 假设 i2 的 ID 为 2;
可以看到虽然 tag_1 中有 col_t1_3 这列,但是建立索引的时候并没有使用到 col_t1_3,因为在图数据库 Nebula Graph 中索引可以基于 Tag 的一列或多列进行创建。
插入点
// VertexId = hash("v_t1_1"),假如为 50
INSERT VERTEX tag_1(col_t1_1, col_t1_2, col_t1_3), tag_2(col_t2_1, col_t2_2) \
VALUES hash("v_t1_1"):("v_t1_1", "v_t1_2", "v_t1_3", "v_t2_1", "v_t2_2");
从上可以看到 VertexId 可由 ID 标识对应的数值经过 Hash 得到,如果标识对应的数值本身已经为 int64,则无需进行 Hash 或者其他转化数值为 int64 的运算。而此时数据存储如下:
此时点的 Data 结构

此时点的 Index 结构

说明:index 中 row 和 key 是一个概念,为索引的唯一标识;
边的存储结构
边的索引结构和点索引结构原理类似,这里不再赘述。但有一点需要说明,为了使索引 key 的唯一性成立,索引的 key 的生成借助了不少 data 中的元素,例如 VertexId、SrcVertexId、Rank 等,这也是为什么点索引中并没有 TagId 字段(边索引中也没有 EdgeType 字段),这是因为** IndexId 本身带有 VertexId 等信息可直接区分具体的 tagId 或 EdgeType**。
边的 Data 结构

边的 Index 结构

Index binary 介绍

Index binary 是 index 的核心字段,在 index binary 中区分定长字段和不定长字段,int、double、bool 为定长字段,string 则为不定长字段。由于** index binary 是将所有 index column 的属性值编码连接存储**,为了精确地定位不定长字段,Nebula Graph 在 index binary 末尾用 int32 记录了不定长字段的长度。
举个例子:
我们现在有一个 index binary 为 index1,是由 int 类型的索引列1 c1、string 类型的索引列 c2,string 类型的索引列 c3 组成:
index1 (c1:int, c2:string, c3:string)
假如索引列 c1、c2、c3 某一行对应的 property 值分别为:23、"abc"、"here",则在 index1 中这些索引列将被存储为如下(在示例中为了便于理解,我们直接用原值,实际存储中是原值会经过编码再存储):
- length = sizeof("abc") = 3
- length = sizeof("here") = 4

所以 index1 该 row 对应的 key 则为 23abchere34;
回到我们 Index binary 章节开篇说的 index binary 格式中存在 Variable-length field lenght 字段,那么这个字段的的具体作用是什么呢?我们来简单地举个例:
现在我们又有了一个 index binary,我们给它取名为 index2,它由 string 类型的索引列1 c1、string 类型的索引列 c2,string 类型的索引列 c3 组成:
index2 (c1:string, c2:string, c3:string)
假设我们现在 c1、c2、c3 分别有两组如下的数值:
- row1 : ("ab", "ab", "ab")
- row2: ("aba", "ba", "b")
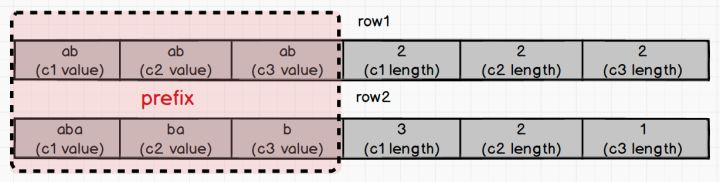
可以看到这两行的 prefix(上图红色部分)是相同,都是 "ababab",这时候怎么区分这两个 row 的 index binary 的 key 呢?别担心,我们有 Variable-length field lenght 。
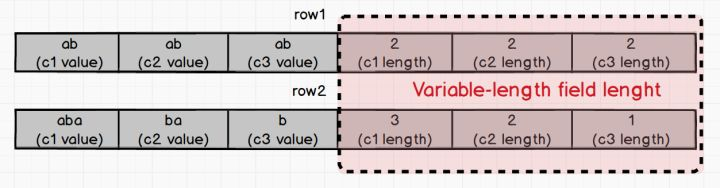
若遇到 where c1 == "ab" 这样的条件查询语句,在 Variable-length field length 中可直接根据顺序读取出 c1 的长度,再根据这个长度取出 row1 和 row2 中 c1 的值,分别是 "ab" 和 "aba" ,这样我们就精准地判断出只有 row1 中的 "ab" 是符合查询条件的。
索引的处理逻辑
Index write
当 Tag / Edge中的一列或多列创建了索引后,一旦涉及到 Tag / Edge 相关的写操作时,对应的索引必须连同数据一起被修改。下面将对索引的write操作在storage层的处理逻辑进行简单介绍:
INSERT——插入数据
当用户产生插入点/边操作时,insertProcessor 首先会判断所插入的数据是否有存在索引的 Tag 属性 / Edge 属性。如果没有关联的属性列索引,则按常规方式生成新 Version,并将数据 put 到 Storage Engine;如果有关联的属性列索引,则通过原子操作写入 Data 和 Index,并判断当前的 Vertex / Edge 是否有旧的属性值,如果有,则一并在原子操作中删除旧属性值。
DELETE——删除数据
当用户发生 Drop Vertex / Edge 操作时,deleteProcessor 会将 Data 和 Index(如果存在)一并删除,在删除的过程中同样需要使用原子操作。
UPDATE——更新数据
Vertex / Edge 的更新操作对于 Index 来说,则是 drop 和 insert 的操作:删除旧的索引,插入新的索引,为了保证数据的一致性,同样需要在原子操作中进行。但是对应普通的 Data 来说,仅仅是 insert 操作,使用最新 Version 的 Data 覆盖旧 Version 的 data 即可。
Index scan
在图数据库 Nebula Graph 中是用 LOOKUP 语句来处理 index scan 操作的,LOOKUP 语句可通过属性值作为判断条件,查出所有符合条件的点/边,同样 LOOKUP 语句支持 WHERE 和 YIELD 子句。
LOOKUP 使用技巧
正如根据本文#数据存储结构#章节所描述那样,index 中的索引列是按照创建 index 时的列顺序决定。
举个例子,我们现在有 tag (col1, col2),根据这个 tag 我们可以创建不同的索引,例如:
- index1 on tag(col1)
- index2 on tag(col2)
- index3 on tag(col1, col2)
- index4 on tag(col2, col1)
我们可以对 clo1、col2 建立多个索引,但在 scan index 时,上述四个 index 返回结果存在差异,甚至是完全不同,在实际业务中具体使用哪个 index,及 index 的最优执行策略,则是通过索引优化器决定。
下面我们再来根据刚才 4 个 index 的例子深入分析一波:
lookup on tag where tag.col1 ==1 # 最优的 index 是 index1
lookup on tag where tag.col2 == 2 # 最优的 index 是index2
lookup on tag where tag.col1 > 1 and tag.col2 == 1
# index3 和 index4 都是有效的 index,而 index1 和 index2 则无效
在上述第三个例子中,index3 和 index4 都是有效 index,但最终必须要从两者中选出来一个作为 index,根据优化规则,因为 tag.col2 == 1 是一个等价查询,因此优先使用 tag.col2 会更高效,所以优化器应该选出 index4 为最优 index。
实操一下图数据库 Nebula Graph 索引
在这部分我们就不具体讲解某个语句的用途是什么了,如果你对语句不清楚的话可以去图数据库 Nebula Graph 的官方论坛进行提问:https://discuss.nebula-graph.io/
CREATE——索引的创建
(user@127.0.0.1:6999) [(none)]> CREATE SPACE my_space(partition_num=3, replica_factor=1);
Execution succeeded (Time spent: 15.566/16.602 ms)
Thu Feb 20 12:46:38 2020
(user@127.0.0.1:6999) [(none)]> USE my_space;
Execution succeeded (Time spent: 7.681/8.303 ms)
Thu Feb 20 12:46:51 2020
(user@127.0.0.1:6999) [my_space]> CREATE TAG lookup_tag_1(col1 string, col2 string, col3 string);
Execution succeeded (Time spent: 12.228/12.931 ms)
Thu Feb 20 12:47:05 2020
(user@127.0.0.1:6999) [my_space]> CREATE TAG INDEX t_index_1 ON lookup_tag_1(col1, col2, col3);
Execution succeeded (Time spent: 1.639/2.271 ms)
Thu Feb 20 12:47:22 2020
DROP——删除索引
(user@127.0.0.1:6999) [my_space]> DROP TAG INDEX t_index_1;
Execution succeeded (Time spent: 4.147/5.192 ms)
Sat Feb 22 11:30:35 2020
REBUILD——重建索引
如果你是从较老版本的 Nebula Graph 升级上来,或者用 Spark Writer 批量写入过程中(为了性能)没有打开索引,那么这些数据还没有建立过索引,这时可以使用 REBUILD INDEX 命令来重新全量建立一次索引。这个过程可能会耗时比较久,在 rebuild index 完成前,客户端的读写速度都会变慢。
REBUILD {TAG | EDGE} INDEX <index_name> [OFFLINE]
LOOKUP——使用索引
需要说明一下,使用 LOOKUP 语句前,请确保已经建立过索引(CREATE INDEX 或 REBUILD INDEX)。
(user@127.0.0.1:6999) [my_space]> INSERT VERTEX lookup_tag_1(col1, col2, col3) VALUES 200:("col1_200", "col2_200", "col3_200"), 201:("col1_201", "col2_201", "col3_201"), 202:("col1_202", "col2_202", "col3_202");
Execution succeeded (Time spent: 18.185/19.267 ms)
Thu Feb 20 12:49:44 2020
(user@127.0.0.1:6999) [my_space]> LOOKUP ON lookup_tag_1 WHERE lookup_tag_1.col1 == "col1_200";
============
| VertexID |
============
| 200 |
------------
Got 1 rows (Time spent: 12.001/12.64 ms)
Thu Feb 20 12:49:54 2020
(user@127.0.0.1:6999) [my_space]> LOOKUP ON lookup_tag_1 WHERE lookup_tag_1.col1 == "col1_200" YIELD lookup_tag_1.col1, lookup_tag_1.col2, lookup_tag_1.col3;
========================================================================
| VertexID | lookup_tag_1.col1 | lookup_tag_1.col2 | lookup_tag_1.col3 |
========================================================================
| 200 | col1_200 | col2_200 | col3_200 |
------------------------------------------------------------------------
Got 1 rows (Time spent: 3.679/4.657 ms)
Thu Feb 20 12:50:36 2020
索引的介绍就到此为止了,如果你对图数据库 Nebula Graph 的索引有更多的功能要求或者建议反馈,欢迎去 GitHub:https://github.com/vesoft-inc/nebula issue 区向我们提 issue 或者前往官方论坛:https://discuss.nebula-graph.io/ 的 Feedback 分类下提建议
最新文章
- IT人可以关注的站
- [游戏模版13] Win32 透明贴图 主角移动
- [JS11] 状态栏滚动
- websocket 待更新
- phpcms 02
- 新买了ipad,在ipad上面看见的一个效果,pc上应该也见过,但是还是ipad上面有印象,如果是弹性运动就最好了
- WinForm程序用使用List对象绑定DataGridView数据源
- Java Web中资源的访问路径
- 触发器记录表某一个字段数据变化的日志 包括插入insert 修改update 删除delete 操作
- awr相关指标解析
- Unhandled Exxception “Unhandled exception type IOException”?
- java中单例设计模式
- 用TTL线在CFE环境下拯救半砖wrt54g路由器
- 【转】qlv文件如何转换成mp4 怎样把下载好的qlv格式视频转换成MP4格式
- Android开发中常见的设计模式 MD
- (转)PWA(Progressive Web App)渐进式Web应用程序
- Python 线程和进程和协程总结
- ChinaCock界面控件介绍-CCSystemBar
- luogu2679 [NOIp2015]子串 (dp)
- 如何使用沙箱测试单笔转账到支付宝账号(php版) https://openclub.alipay.com/read.php?tid=1770&fid=28