Python爬虫-豆瓣电影 Top 250
爬取的网页地址为:https://movie.douban.com/top250
打开网页后,可观察到:TOP250的电影被分成了10个页面来展示,每个页面有25个电影。
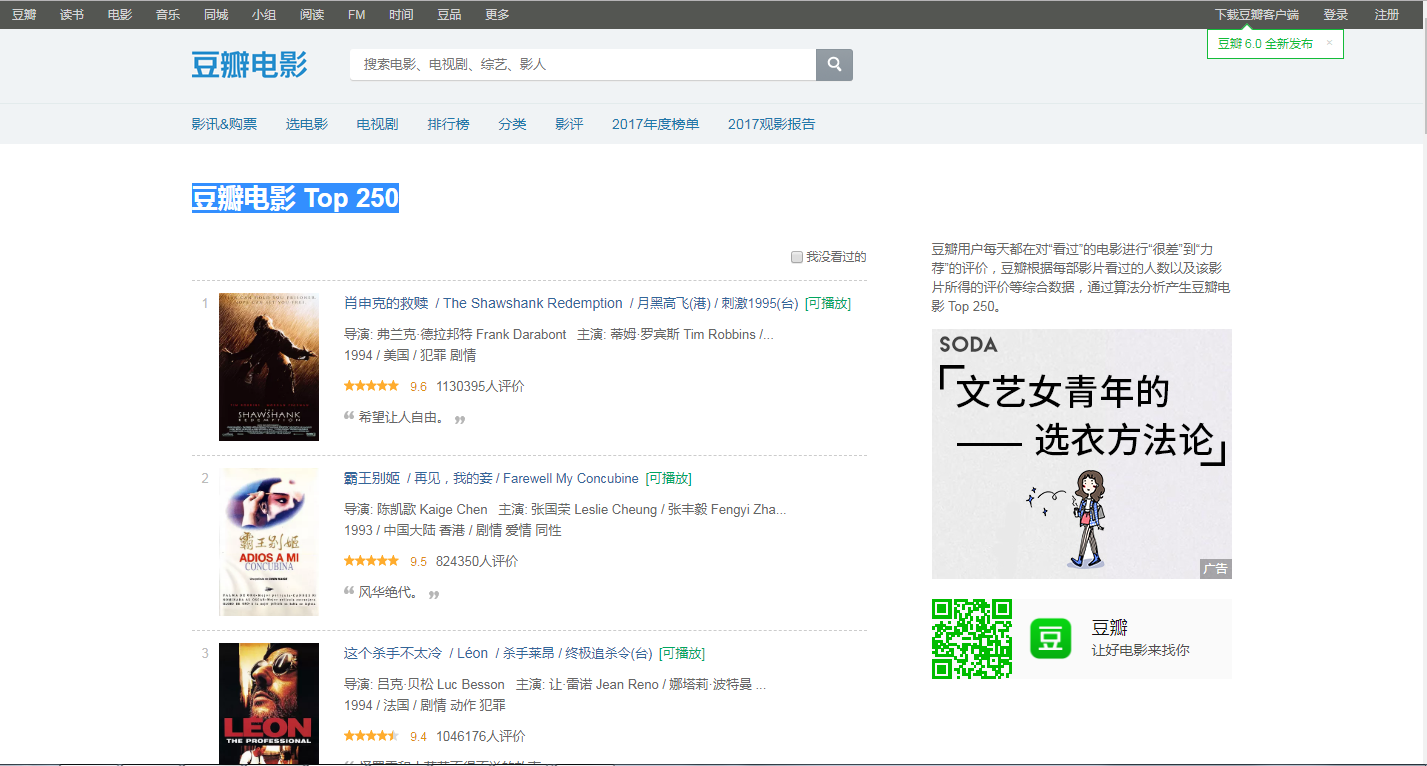
那么要爬取所有电影的信息,就需要知道另外9个页面的URL链接。
第一页:https://movie.douban.com/top250
第二页:https://movie.douban.com/top250?start=25&filter=
第三页:https://movie.douban.com/top250?start=50&filter=
以此类推...
分析网页源代码:以首页为例

观察后可以发现:
所有电影信息在一个ol标签之内,该标签的 class属性值为grid_view;
每个电影在一个li标签里面;
每个电影的电影名称在:第一个 class属性值为hd 的div标签 下的 第一个 class属性值为title 的span标签里;
每个电影的评分在对应li标签里的(唯一)一个 class属性值为rating_num 的span标签里;
每个电影的评价人数在 对应li标签 里的一个 class属性值为star 的div标签中 的最后一个数字;
每个电影的短评在 对应li标签 里的一个 class属性值为inq 的span标签里。
Python主要模块:requests模块 BeautifulSoup4模块
>pip install requests
>pip install BeautifulSoup4
主要代码:
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 |
# -*- coding:utf-8 -*-
import requests # requests模块 from bs4 import BeautifulSoup # BeautifulSoup4模块 import re # 正则表达式模块 import time # 时间模块 import sys # 系统模块 """获取html文档""" """解析数据""" # 得到电影的评分 # 得到电影的评价人数 # 得到电影的短评 ))) # 将输出重定向到txt文件 outputfile.close() |
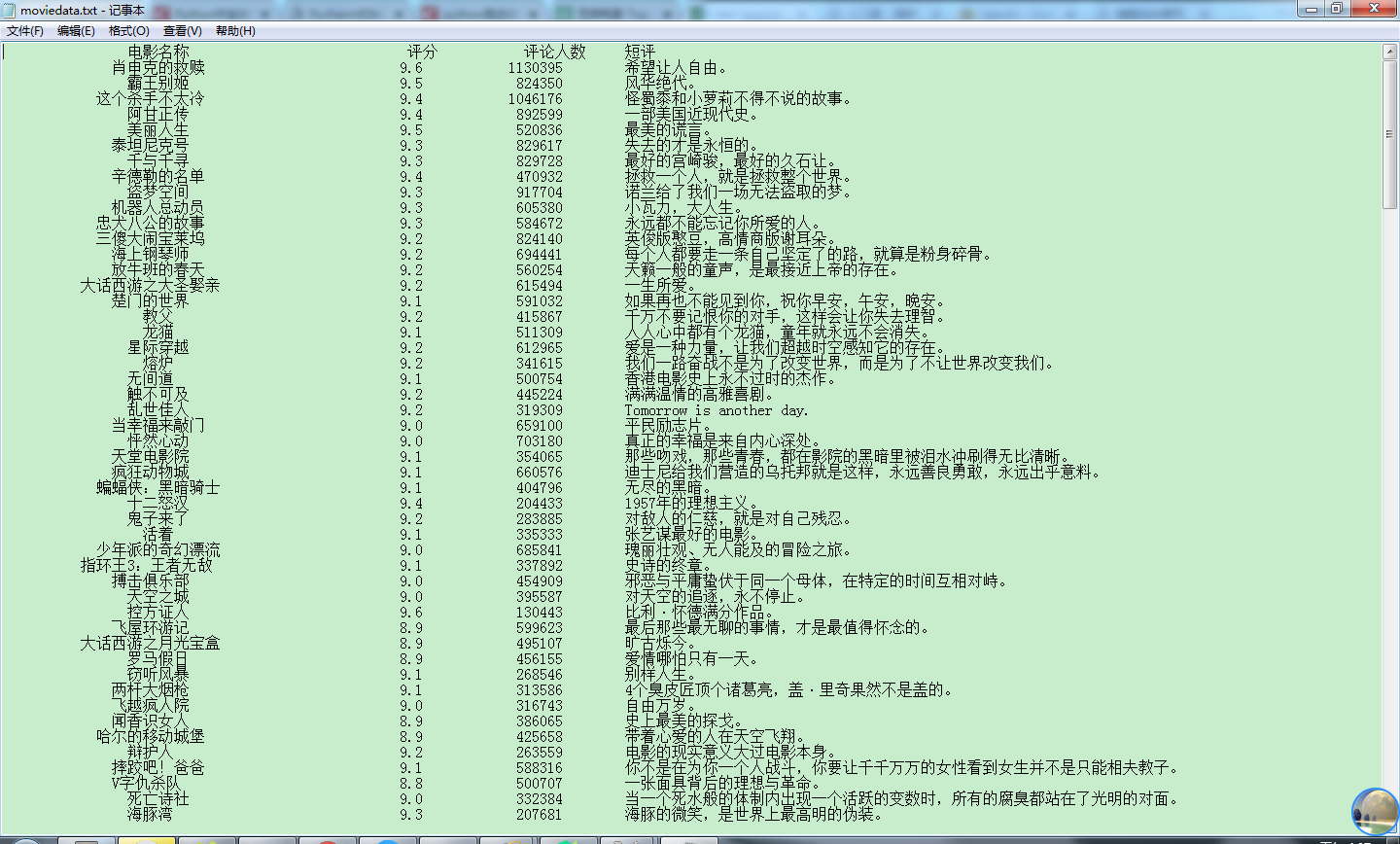
参考出处:https://blog.csdn.net/linzch3/article/details/62444947
最新文章
- java内置数据类型
- JavaScript String 对象
- .Net中的Placeholder控件
- static的应用以及静态与非静态的区别
- 用linux的shell脚本把目录下面的所有文件的文件内容中的小写字母改成大写字母
- javascript闭包特性
- 简单的Ajax
- HDU 4707 Pet(DFS(深度优先搜索)+BFS(广度优先搜索))
- c语言下多线程
- linux下php-5.4.8.tar.gz编译安装全攻略
- Python 之简单线程池创建
- C语言预处理 编译 汇编 链接四个阶段
- synchronized修饰static方法与非static方法的区别
- @Controller和@RestController之间的区别
- Pandas系列(十)-转换连接详解
- 上传图片(photoClip)
- CRM销售管理功能
- <转> 解决异常:IllegalStateException: Fragment <ThisFragment> is not currently in the FragmentManager
- 在SpringMVC中使用@RequestBody注解处理json时,报出HTTP Status 415的解决方案
- 【Java】Java-UTC-时间戳处理