使用celery时要注意的任务调用形式
2024-08-21 20:44:02
因为之前,一直用django和celery紧密集成,不分家。
所以使用时参考了网上的配置之后,没有变更过。
最近,和洪军想用k8s的pod重新规划系统构架时,这个问题才又浮了出来。
只是我们的task和framework集成太深,celery worker确实不容易拆出来,
但原则还是要知道的。
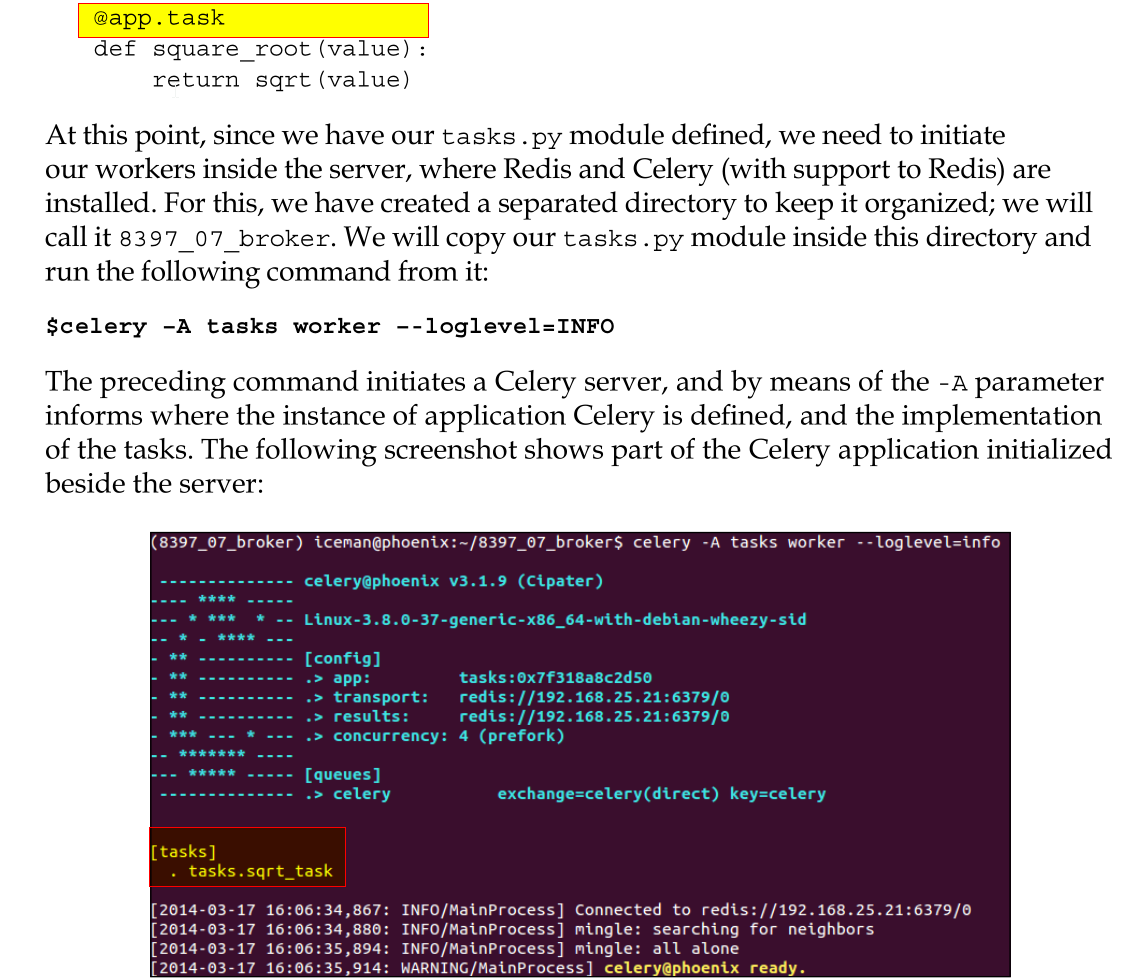
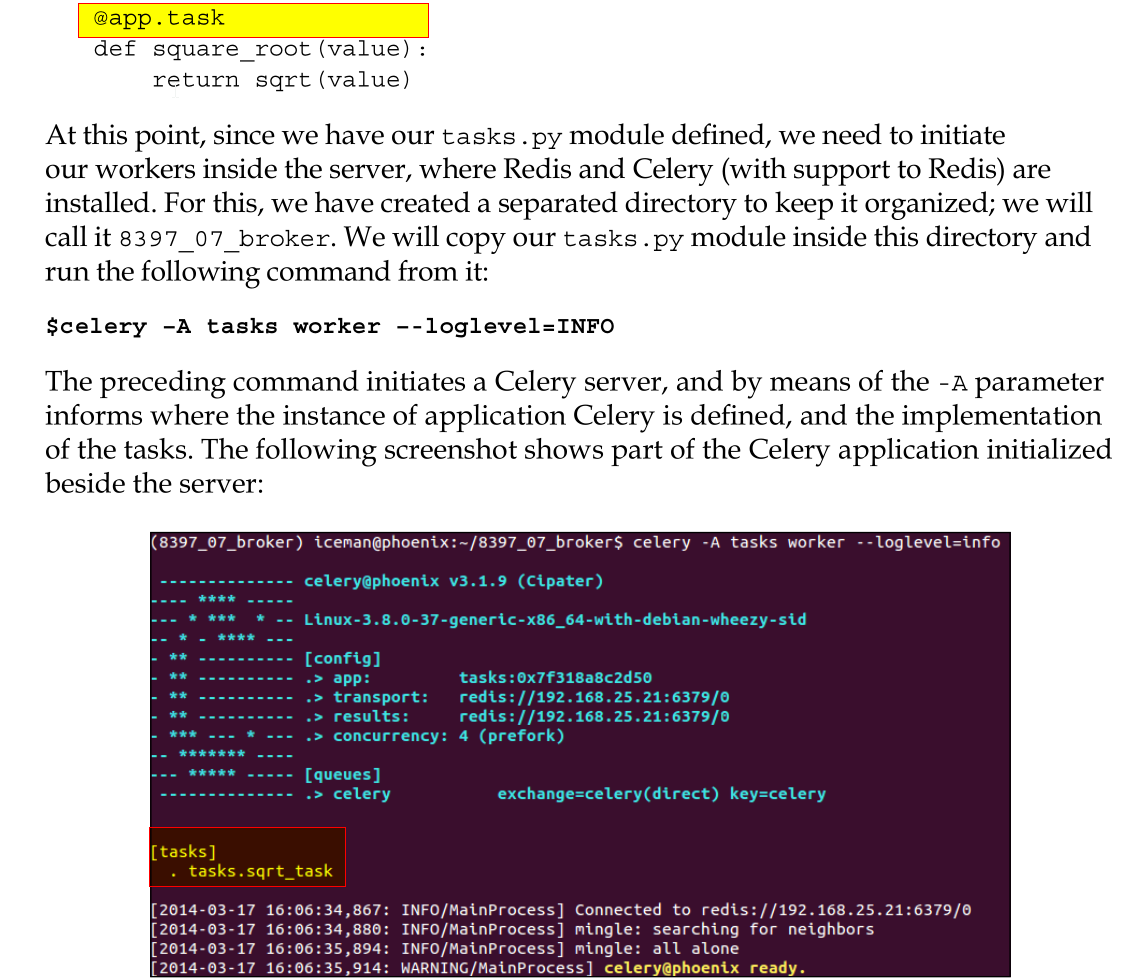
今天看书,代码及注释中说明了,如果client要调用worker上的task,
只需要传递模块内的任务名称,及相关参数即可!!!
而django和celery合作时,是相互缠绕在一起的,无法明辩。

最新文章
- dg
- TensorFlow 源代码初读感受
- [NOIP摸你赛]Hzwer的陨石(带权并查集)
- SVN中Branch和Merge实践
- 八、Linux下的网络服务器模型
- 响应式嵌入 iframe Pym.js
- HDU5627--Clarke and MST (bfs+位运算)
- Memcached 集群的高可用(HA)架构
- Appium--swipe滑动方法
- 关于Linux虚拟化技术KVM的科普 科普二(KVM虚拟机代码揭秘)
- 关于接口(Interface)
- Python金融大数据分析PDF
- 得到一个文件夹中所有文件的名称的几个方法(命令指示符, C++, python)
- 我的SSH框架实例(附源码)
- 零基础用Docker部署微服务
- Robot Framework 的安装配置和简单的实例介绍
- LeetCode: Swap Nodes in Pairs 解题报告
- Eclipse+Spark搭建源码分析环境问题分析
- 自定义spring valid方式实现验证
- MySQL高可用之MGR安装测试