tf–idf算法解释及其python代码实现(上)
2024-08-24 11:00:56
tf–idf算法解释
tf–idf, 是term frequency–inverse document frequency的缩写,它通常用来衡量一个词对在一个语料库中对它所在的文档有多重要,常用在信息检索和文本挖掘中。
一个很自然的想法是在一篇文档中词频越高的词对这篇文档越重要,但同时如果这个词又在非常多的文档中出现的话可能就是很普通的词,没有多少信息,对所在文档贡献不大,例如‘的’这种停用词。所以要综合一个词在所在文档出现次数以及有多少篇文档包含这个词,如果一个词在所在文档出现次数很多同时整个语料库中包含该词的文档又很少的话,说明该词对所在文档很重要。而一个词在所在文档的词频(tf)乘以包含该词的文档数量的倒数(idf)是符合这种想法的
定义:
tf: 最简单的选择就是一个词在所在文档出现次数,例如,用tf(t,d)表示词t在文档d中出现的次数
idf:idf衡量了一个词提供多少信息,如果一个词在整个语料库中每篇文档都出现说明这个词基本没提供任何信息,例如‘的’这个词几乎在任何文中中都会出现,idf通常取对数计算,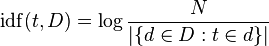
其中N表示文档总数,分母表示语料库中包含词t的数量
然后就可以得到语料库D中第d篇文档中词t的tf-idf值了:

下一篇是python代码的实现
最新文章
- HDU 5384 AC自动机
- java常用加密和解密工具类EncryptUtil.java
- Wall--POJ1113(极角排序+求凸包)
- HDU 4043 FXTZ II (组合数学-排列组合)
- linux/windows 下kill某个pid的进程
- 广州项目实施步骤I_练习安装 CentOS x64 6.4
- echarts雷达图
- Java随机数
- poj 2031 Building a Space Station【最小生成树prime】【模板题】
- Prometheus Operator - 每天5分钟玩转 Docker 容器技术(177)
- LOJ #2719. 「NOI2018」冒泡排序(组合数 + 树状数组)
- SQL Server嵌套事务
- photoshop学习3
- JavaScript实现的抛物线运动效果
- AuthenticationManager、ProviderManager
- 【问题收集·中级】关于XMPP使用Base传送图片
- 【CSS3】好玩的动画线框
- 状压dp终极篇(状态转移的思想)
- 7.css实现三角形
- R语言文本挖掘+词云显示(jiebaR包+wordcloud2包)