Python3基础之数据类型(字符串和列表)
2024-08-30 09:06:18
1、Python字符串方法
1.1、如何在Python中使用字符串
a、使用单引号(')
用单引号括起来表示字符串,例如:
str1="this is string";
print(str1);
b、使用双引号(")
双引号中的字符串与单引号中的字符串用法完全相同,例如:
str2="this is string";
print(str2);
c、使用三引号(''')
利用三引号,表示多行的字符串,可以在三引号中自由的使用单引号和双引号,例如:
str3='''this is string
this is pythod string
this is string'''
print(str3);
2.python 字符串常用的内置方法,对字符串进行操作,如下:
in方法:
#in方法:判断内容是否存在字符串中
name = 'hello bei jing zao an '
print('hello' in name) #判断hello 是否存在name里,执行结果为True
print('shang hai ' in name) #判断 shanghai 是否存在name里,执行结果为False
not方法:
name = 'hello bei jing zao an ' #定义字符串
#not方法:返回表达式结果的'相反值'。如果表达式结果为真,则返回False
print('hello' not in name) #判断hello 不存在name里,执行结果为False
print('abc' not in name) #判断abc 不存在name里,执行结果为True
is方法:
#is 判断的是 内存地址是否相同
a = 'xiaoming'
b = 'xiaoming'
print(a is b ) #a和b的值相同,内存里存放时,指向的内存地址相同,指向结果为True
print(id(a))
print(id(b)) #可以通过id(变量名)这个方法,查看变量的内存地址
3、字符串取值方法
names = 'hello bei jing one day'
print(names[0:10]) # 1.可以通过下标进行取值,切片,顾头不含尾,执行结果是:hello bei for name in names:
print(name) for k in range(len(names)):
print(names[k])#2.通过for循环取值,循环的是循环对象(names)里面的每一个元素 for k in range(len(names)):
print(names[k]) #3.循环names的长度,进行取值,k的值是数字,相当于字符串的下标
4.字符串的endswith、startswith、isalnum、isalpha方法:
name = 'hello world is world'
print(name.endswith('d')) #判断是否以u结尾,执行结果为布尔值 print(name.starstwith('d')) #判断是否以u结尾,执行结果为布尔值 print('ab123'.isalnum()) #判断输入的字符串是否包含数字和字母,判断密码是否包含数字和字母时,可以使用,返回结果为布尔值 print('abcdA'.isalpha()) #判断输入的字符串是否是英文字母,返回结果为布尔值
5.判断输入的字符串是否为数字,如下:
name = ' abcdERF123'
print(''.isdigit()) #判断输入的字符串是否为数字,返回结果为布尔值
6.去除字符串的空格,如下:
#去除空格
print(' ab fs'.lstrip()) #默认去掉字符串左边的空格和换行,执行结果:ab fs
print('hello '.rstrip()) #默认去掉字符串右边的空格和换行,执行结果:hello
print('\nmysql abcd'.strip()) #默认去掉两边的空格和换行,执行结果:mysql abcd,中间的空格不可去除
print('mysqlmy'.strip('m')) #去除指定的字符串,例如:去除两边的m元素,执行结果:ysqlm y
7.字符串的join方法,如下:
#join是用来通过 某个字符串 拼接 一个可迭代对象的每个元素--->join(可迭代对象参数类型)
name = 'abcdABCD123'
#将字符串中的每个元素都使用*号连接,执行结果:a*b*c*d*A*B*C*D*1*2*3,返回一个新的变量值
print('*'.join(name)) nums = ['ybq', 'lhl', 'lsh']
#将列表转换为字符串,每个元素之间使用逗号连接,执行结果为:ybq,lhl,lsh
print(','.join(nums)) #另一种方法将列表转换为字符串
nums = ['ybq', 'lhl', 'lsh']
temp = ''
for i in nums:
temp = temp+i+','
#列表转换为字符串,强制类型转换,执行结果为:ybq,lhl,lsh
print(type(temp),temp)
print(temp.strip(','))
输出结果为:
<class 'str'> ybq,lhl,lsh,
ybq,lhl,lsh
8.替换replace字符串,如下:
st = 'mysql is db mysql mysql mysql'
#将字符串中的mysql替换为oracle
print(st.replace('mysql', 'oracle'))
#替换的元素存在较多时,可以输入想替换的次数
print(st.replace('mysql', 'oracle', 1))
9.查找find,index字符串,如下:
name = 'hello world is world'
print(name.find('world')) #查找字符串的索引
print(name.find('world', 3, 10)) #可以指定查找字符串的范围,3,15 是开始、结束的下标值,下标值顾头不顾尾
print(name.find('xxx')) #查找的字符串不存在时,返回结果为-1
print(name.rfind('world')) #查找字符串,从后往前查找,执行结果为:15
print(name[2])#按照索引查找,索引从0开始,执行结果为:'o'
print(name.index('o'))#按值查找,执行结果:4
10.切割字符串spilt,返回结果类型为list,如下:
#切割字符串,返回的类型是list
name1 = 'zcl,py,zyz,ywq' #将字符串切割成list
name1_list = name1.split(',') #按照逗号分割字符串,返回结果为list,name1的值未改变
print(name1_list) #执行结果为list类型:['zcl', 'py', 'zyz', 'ywq']
print(name1.split()) #按照空格分割字符串,返回结果是list,只有一个元素,执行结果:['zcl,py,zyz,ywq']
print(name1.spilt('\n')) #按照换行符分割字符串
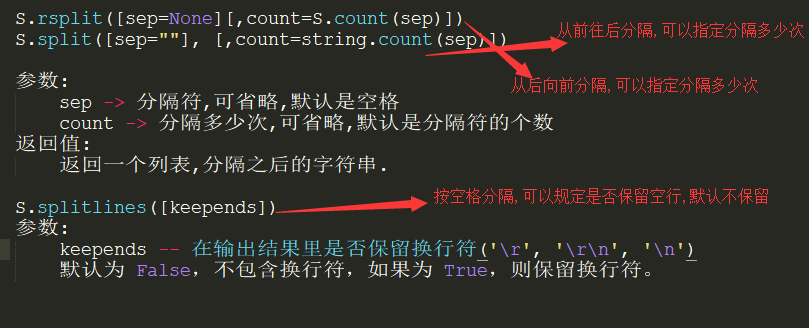
11.按照换行符分割字符串,不常用,如下:
print('1+2+3\n1+3+4'.splitlines()) #按照换行符分割,分割的是每一行文件的内容作为list的一个元素,执行结果:['1+2+3', '1+3+4']
12.字符串随机生成大小写字母、数字,用法如下:
import string
print(string.ascii_letters + string.digits) #输出所有的大小写字母+(0-9)的数字
print(string.ascii_letters) #输出大小写的英文字母,执行结果:abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ
print(string.ascii_lowercase) #输出小写英文字母,执行结果:abcdefghijklmnopqrstuvwxyz
print(string.ascii_uppercase) #输出小写英文字母,执行结果:ABCDEFGHIJKLMNOPQRSTUVWXYZ
13.格式字符串,如下:
print(name.format(name='byz', age=18)) #格式化字符串显示
print(name.format_map({'name': 'zhangsan', 'age': 18})) #格式化字典
14.count 计数
name = 'abcdabcddda'
print(name.count('a'))#统计a在字符串中出现的次数,执行结果:3
字符串不常用的方法,了解即可:
字符串中大小写字母的判断与转换,如下:
name = ' abcdERF123'
print('aa'.islower()) #判断输入的字符串是否为小写字母,返回结果为布尔值
print('ASD'.isupper()) #判断输入的字符串是否为大写字母
print(name.lower()) #将字符串中的大写字母变成小写,执行结果:abcderf123
print(name.upper()) #将字符串中的小写字母变成大写,执行结果:ABCDERF123
print('ABCdef'.swapcase()) #大小写字母反转,执行结果:abcDEF
字符串的映射,可以做密码加密使用,如下:
#映射
p = str.maketrans('abcdefg', '1234567') #前面的字符串和后面的字符串进行映射,a-->1,c-->3 、
print('ccaegg'.translate(p)) #输出结果按照上面的maketrans做映射后的字符串,执行结果为:331577 #反解映射
new_p = str.translate('1234567', 'abcdefg')
print('ccaegg'.translate(new_p)) #输出结果按照上面的maketrans做映射后的字符串,执行结果为:ccaegg
对字符串的首字母进行大写
name = 'hello world is world'
print(name.capitalize()) #首字母大写,执行结果:Hello world
print(name.center(50, '*')) #长度总共为50,将name字符串的值放在中间,两边补充*号显示
2、Python列表方法大全
names = ['a','b','c','d']
1、追加:names.append()
>>> names.append('e')
>>> names
['a', 'b', 'c', 'd', 'e']
2、删除:pop,remove,del
1)pop()
>>> names.pop()
'e'
如果没有指定下标,则默认会删除最后一个元素
>>> names.pop(2)
'c'
指定下标时,就会删除下标所对应的元素
2)remove()
>>> names.remove('e')
>>> names
['a', 'b', 'c', 'd']
3)del
>>> del names[4]
>>> names
['a', 'b', 'c', 'd']
3、查找元素所在位置:index()
>>> names.index('c')
4、统计元素的次数:count()
>>> names.append('d')
>>> names.count('d')
5、反转:reverse()
>>> names.reverse()
>>> names
['d', 'c', 'b', 'a']
6、清空:clear()
>>> names.clear()
>>> names
[]
7、插入:insert()
>>> names.insert(2,'devilf')
>>> names
['a', 'b', 'devilf', 'c', 'd']
还有其他的插入方法:
>>> names[3] = 'lebron'
>>> names
['a', 'b', 'devilf', 'lebron', 'd']
8、排序:sort()按照ascii码来进行排序

>>> names.insert(4,'&&')
>>> names
['a', 'b', 'd', 'devilf', '&&', 'lebron']
>>> names.sort()
>>> names
['&&', 'a', 'b', 'd', 'devilf', 'lebron']
9、拼接两个列表:extend()
>>> names.extend(place)
>>> names
['&&', 'a', 'b', 'd', 'devilf', 'lebron', 'beijing', 'shandong', 'usa']
10、对列表进行切片处理
1)列出所有的元素
>>> names[::]
['&&', 'a', 'b', 'd', 'devilf', 'lebron', 'beijing', 'shandong', 'usa']
2)列出最后一个元素,从中间位置开始,列出后面所有的元素
>>> names[-1]
'usa'
>>> a = int(len(names)/2)
>>> names[a:]
['devilf', 'lebron', 'beijing', 'shandong', 'usa']
11、复制:copy()
>>> names.copy()
['&&', 'a', 'b', 'd', 'devilf', 'lebron', 'beijing', 'shandong', 'usa']
另外的几种复制的方法:
>>> info = ['name',['a',100]]
>>> n1 = copy.copy(info)
>>> n2 = info[:]
>>> n3 = list(info)
在使用copy.copy()时,需要导入copy模块
这些均是浅copy
例如:
>>> info
['name', ['a', 100]]
>>> n1 = info[:]
>>> n2 = copy.copy(info)
>>> n1
['name', ['a', 100]]
>>> n1[0] = 'devilf'
>>> n2[0] = 'lebron'
>>> n1;n2
['devilf', ['a', 100]]
['lebron', ['a', 100]]
>>> n1[1][1] = 80
>>> n1
['devilf', ['a', 80]]
>>> n2
['lebron', ['a', 80]]
这里可以看到修改n1列表中的值,n2中的值也会跟着改变,这就是浅copy,也就是说,浅copy会复制原列表的内存地址,也就是说,我们修改了n1和n2,就是修改了指向同一内存地址的对象,所以info列表会变化,n1和n2都会变化,例如:
>>> info
['name', ['a', 80]]
最新文章
- python安装库
- Windows 2008 R2 强制删除Cluster
- Windows Server+AMD GPU+HDMI时_黑边_不铺满问题的解决办法
- 打包jar文件 外部调用资源 so等
- BizTalk开发系列(三十六) Orchestration单实例执行
- java 使用反射技术解耦
- debian 学习记录-2 -账户 -关机
- 测试MarsEdit
- 【录教程必备】推荐几款屏幕录制工具(可录制GIF)
- javascript的字符串判断方法
- duilib基本流程
- Odoo:全球第一免费开源ERP库龄表的简单实现方法(无需二开)
- Python核心编程笔记 第三章
- JS-对象的数据重复
- Python中的迭代器、生成器
- centos7 清除系统日志、历史记录(包括history)、登录信息
- 【巷子】---middleware---redux-promise-middleware---【react】
- 前台获取枚举的key值
- c# 除掉前三个字符,剩下的4个字符全为数字方为特殊车辆
- 虚拟机三种网络模式详解(Bridge,Nat,Host-only)