Python 3实现网页爬虫
1 什么是网页爬虫
网络爬虫( 网页蜘蛛,网络机器人,网页追逐者,自动索引,模拟程序)是一种按照一定的规则自动地抓取互联网信息的程序或者脚本,从互联网上抓取对于我们有价值的信息。Tips:自动提取网页的程序,为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。
(1) 对抓取目标的描述或定义;
(2) 对网页或数据的分析与过滤;
(3) 对URL的搜索策略。
2 Python爬虫架构
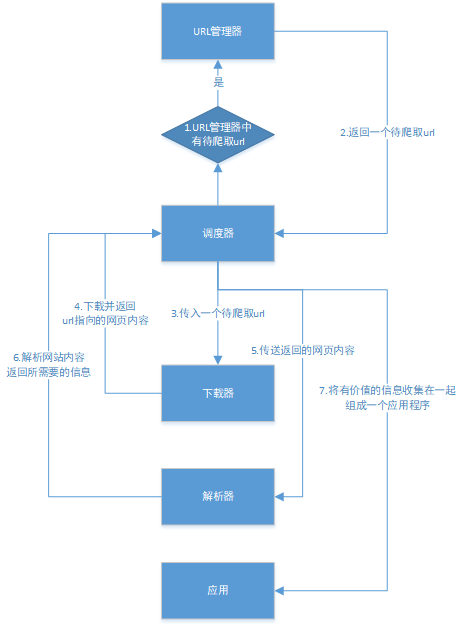
Python爬虫架构主要由调度器、URL管理器、网页下载器、网页解析器、应用程序(爬取的有价值数据)5个部分组成。
- 调度器:相当于一台电脑的CPU,主要负责调度URL管理器、下载器、解析器之间的协调工作。
- URL管理器:包括待爬取的URL地址和已爬取的URL地址,防止重复抓取URL和循环抓取URL,实现URL管理器主要用三种方式,通过内存、数据库、缓存数据库来实现。
- 网页下载器:通过传入一个URL地址来下载网页,将网页转换成一个字符串,网页下载器有urllib2(Python官方基础模块)包括需要登录、代理、和cookie,requests(第三方包)
- 网页解析器:将一个网页字符串进行解析,可以按照我们的要求来提取出我们有用的信息,也可以根据DOM树的解析方式来解析。网页解析器有正则表达式(直观,将网页转成字符串通过模糊匹配的方式来提取有价值的信息,当文档比较复杂的时候,该方法提取数据的时候就会非常的困难)、html.parser(Python自带的)、beautifulsoup(第三方插件,可以使用Python自带的html.parser进行解析,也可以使用lxml进行解析,相对于其他几种来说要强大一些)、lxml(第三方插件,可以解析 xml 和 HTML),html.parser 和 beautifulsoup 以及 lxml 都是以 DOM 树的方式进行解析的。
- 应用程序:就是从网页中提取的有用数据组成的一个应用。
下面用一个图来解释一下调度器是如何协调工作的:
3 urllib.request实现下载网页的三种方式
方法一:使用urllib.request.urlopen(url)方法函数实现最基本请求url的发起(打开url网址的操作)
函数原型如下:urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
方法二:使用response=urllib.request. Request (url)及urllib.request.urlopen(request)函数
response=urllib.request. Request (url)实现对目标url,data,headers以及method访问
urllib.request.urlopen(request)参数为request对象,代码中 response就是上一步得到的request对象(打开url网址的操作)
Tips:构建一个完整的请求,如果请求中需要加入headers(请求头)等信息,我们就需要使用更强大的Request类来构建一个请求。Request存在的意义是便于在请求的时候传入一些信息,而urlopen则不。
方法三:加入urllib.request处理cookie的能力结合urllib.request.urlopen(url)函数实现
Tips:Python 2使用urllib2代替urllib.request,cookies代替http.cookiejar,print代替print()
#!/usr/bin/python
# -*- coding: UTF-8 -*- import http.cookiejar
import urllib.request url = "http://www.baidu.com"
response1 = urllib.request.urlopen(url)
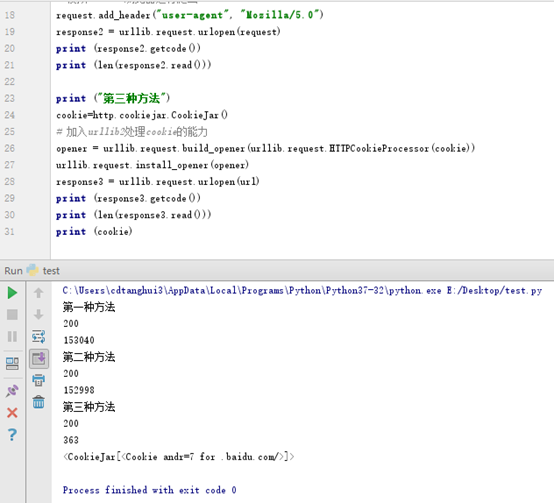
print ("第一种方法")
# 获取状态码,200表示成功
print (response1.getcode())
# 获取网页内容的长度
print (len(response1.read())) print ("第二种方法")
request = urllib.request.Request(url)
# 模拟Mozilla浏览器进行爬虫
request.add_header("user-agent", "Mozilla/5.0")
response2 = urllib.request.urlopen(request)
print (response2.getcode())
print (len(response2.read())) print ("第三种方法")
cookie=http.cookiejar.CookieJar()
# 加入urllib.request处理cookie的能力
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cookie))
urllib.request.install_opener(opener)
response3 = urllib.request.urlopen(url)
print (response3.getcode())
print (len(response3.read()))
print (cookie)
执行结果见下图:
4 使用三方库Beautiful Soup实现解析html文件
4.1 Beautiful Soup的安装
Beautiful Soup:Python 的第三方插件,用来提取 xml 和 HTML 中的数据,官网地址 https://www.crummy.com/software/BeautifulSoup/。
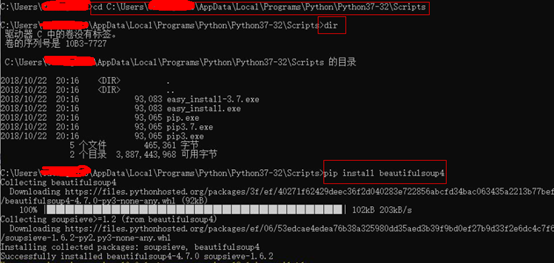
打开cmd(命令提示符),进入到Python(Python3版本)安装目录中的Scripts下,输入dir查看是否有pip.exe,如果用就可以使用Python自带的pip命令进行安装,输入以下命令进行安装即可:
pip install beautifulsoup4
执行如下图:
2、测试是否安装成功
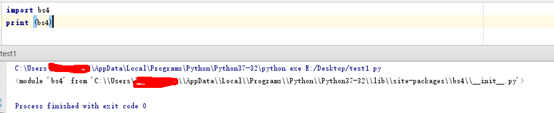
编写一个 Python 文件test.py,输入:
import bs4 print (bs4)
运行该文件,如果能够正常输出则安装成功,如下。
4.2 使用 Beautiful Soup 解析 html 文件
#!/usr/bin/python
# -*- coding: UTF-8 -*- import re from bs4 import BeautifulSoup html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://news.baidu.com" name="tj_trnews" class="mnav">新闻</a>
<a href="https://www.hao123.com" name="tj_trhao123" class="mnav">hao123</a>
<a href="http://map.baidu.com" name="tj_trmap" class="mnav">地图</a>
<a href="http://v.baidu.com" name="tj_trvideo" class="mnav">视频</a>
<a href="http://tieba.baidu.com" name="tj_trtieba" class="mnav">贴吧</a>
<a href="http://xueshu.baidu.com" name="tj_trxueshu" class="mnav">学术</a>
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
# 创建一个BeautifulSoup解析对象
soup = BeautifulSoup(html_doc, "html.parser")
# 获取所有的链接
links = soup.find_all('a')
print ("所有的链接")
for link in links:
print (link.name, link['href'], link.get_text()) print ("获取特定的URL地址")
link_node = soup.find('a', href="http://news.baidu.com")
print (link_node.name, link_node['href'], link_node['class'], link_node.get_text()) print ("正则表达式匹配")
link_node = soup.find('a', href=re.compile(r"hao"))
print (link_node.name, link_node['href'], link_node['class'], link_node.get_text()) print ("获取P段落的文字")
p_node = soup.find('p', class_='story')
print (p_node.name, p_node['class'], p_node.get_text())
执行结果如下:

------------------------------------------------------Tanwheey-------------------------------------------------------------------------
爱生活,爱工作。
最新文章
- PHP build notes - WARNING: This bison version is not supported for regeneration of the Zend/PHP parsers (found: 3.0, min: 204, excluded: 3.0).
- c#串口通信类代码可以直接调用
- 第三个Sprint团队贡献分
- 转载:Robotium之Android控件定位实践和建议(Appium/UIAutomator姊妹篇)
- ABAP自定义类的构造方法
- Jquery的$命名冲突
- SpringMvc学习-增删改查
- 再谈c++中的引用
- Linux进程通信----匿名管道
- USM锐化之openCV实现,附赠调整对比度函数
- <hr/>标签改变颜色注意事项
- Openjudge-计算概论(A)-骑车与走路
- MQ-2烟雾传感器启动
- mysql中group by和order by同时使用无效的替代方案
- Foreign websites
- Centos7 下yum安装mysql
- 富文本编辑器Quill(二)上传图片与视频
- JVM深入理解<一>
- 4.4Python数据类型(4)之字符串函数
- Amazon RDS多区域高可用测试