字符编码 python2与python3的区别
1. 字符编码
字符:就是存储了信息的东西
键盘发送等等是电流——》主机(内存)接收到电流(当做010101011101)——》显示屏 接收电流 (当做010101010——》键盘)
2. 文本编辑器存储信息的过程
文本编辑器——》写文本 ——》存储信息
显示器(内存)——》(转换)硬盘
3. 编码:
1. 编码的历史
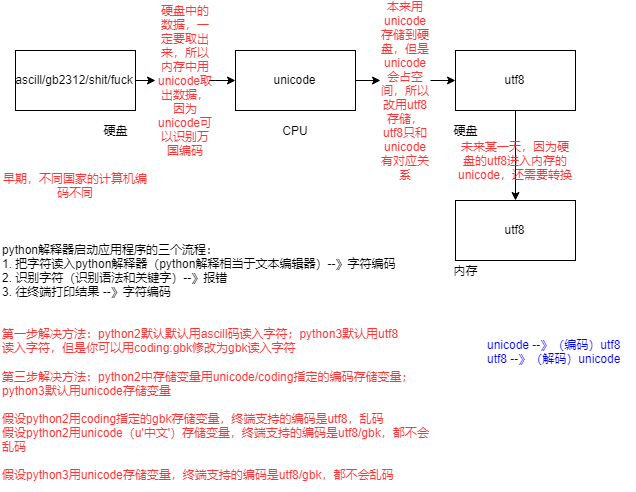
美国:ASCII
中国:gb2312
等等。。。 但这样会妨碍信息文化的交流
然后出现了Unicode编码(一种对应关系)
Unicode可以认识万国编码
现在所有的电脑都是这样的:内存中用Unicode读取硬盘内容,存用utf8存(硬盘)。
内存中不用utf8,是因为utf8和其他编码没有转换关系
注意:虽然说utf是为了使用更少的空间而使用的,但那只是相对于unicode编码来说,如果已经知道是汉字,则使用GB2312/GBK无疑是 最节省的。不过另一方面,值得说明的是,虽然utf-8编码对汉字使用3个字节,但即使对于汉字网页,utf-8编码也会比unicode编码节省,因为网页中包 含了很多的英文字符。
2. gb2312和gbk的区别
gb2312 只支持常用的字词
gbk 支持几乎全部
windows系统的记事本默认是 gbk编码,除此之外都是 utf8
3. 编码和解码
Unicode编码——》(编码)utf8 从内存到硬盘
utf8 ——》(解码)Unicode 从硬盘到内存
4. python解释器 解释代码的流程
1. 读取文本到解释器
python2默认是使用ASCII编码读取
python3默认使用 utf8编码读取
(当有coding头时,他们都使用coding中设定的编码进行读取)
2. 识别代码(检查语法问题)
3. 往终端打印
存储变量:
- python2中存储变量用Unicode/coding指定的编码存储变量
print u'中国' #表示用unicode存储变量
- python3中默认使用Unicode存储变量
假设1:python2用coding指定的gbk存储变量,终端支持的编码是utf8,打印结果:乱码
假设2:python2用Unicode(u'中文')来存储变量,终端支持的编码是utf8/gbk,打印结果:都不会乱码
假设3:python3用Unicode存储变量,终端支持的编码是utf8/gbk,打印结果:都不会乱码
最新文章
- 前端学HTTP之客户端识别和cookie
- iOS/Android网络消息推送的实现两种方法
- [日常训练]常州集训day7
- IOS-synthesize和dynamic的异同(转)
- 创建型模式之Singleton模式
- http://www.cnblogs.com/yjmyzz/p/3941043.html
- 金蝶KIS 13.0专业版破解方法破解安装流程 金蝶KIS 13.0专业版安装流程
- POJ 3276 Face The Right Way 翻转(开关问题)
- 将stack翻译成"堆栈"实在是误人子弟
- JQ实战天猫淘宝放大镜
- Ajax,纯Js+Jquery
- 解决ExtJs Uncaught TypeError: c is not a constructor错误
- Ons 让人欲哭无泪问题,官方介绍不详
- C#设计模式——单例模式的实现
- rocketmq安装与基本操作
- jq中each的中断
- C++编程技巧降低编译时间
- istio 配置解读
- P2733 家的范围 Home on the Range
- Safari 不能播放Video ,Chrome等可以 问题解决。