Web应用中的缓存一致性问题
上篇总结了缓存中出现频率比较高的一些问题,今天详细说说web应用中的缓存一致性问题。
主要说以下三个方面
- 数据库与缓存中数据不一致出现的情形
- 发生不一致时的优化思路
- 如何保证数据库与缓存的一致性
先来讨论下结论
由于操作缓存与操作数据库不是原子的,所以非常有可能出现执行失败的情况。
假设先写数据库,再淘汰缓存:这时候如果出现写数据库成功,淘汰缓存失败,则会出现DB中是新数据,cache中是旧数据,数据不一致,此时获取数据仍然为旧数据,在cache失效之前,获取的数据均为异常数据如下:
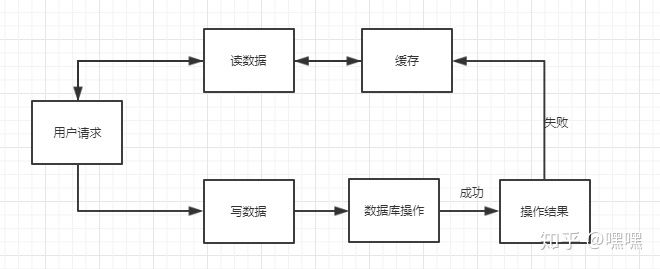
假设先淘汰缓存,再写数据库:第一步淘汰缓存成功,第二步写数据库失败,则只会引发一次cache miss
综上,在涉及缓存操作时应该先淘汰缓存,再修改数据
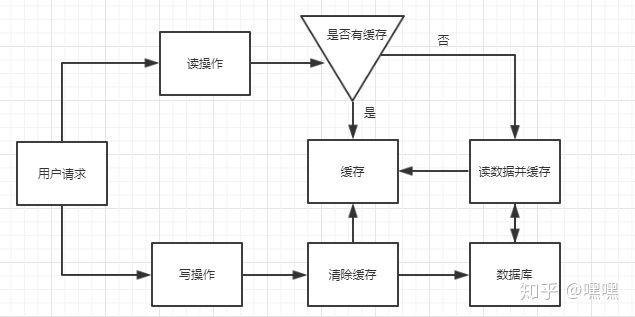
不一致出现的情形
在分布式环境下,数据的读写都是并发的,上游有多个应用,通过一个服务的多个部署(为了保证可用性,一定是部署多份的),对同一个数据进行读写,在数据库层面并发的读写并不能保证完成顺序,也就是说后发出的读请求很可能先完成(读出脏数据):
(1)发生了写请求A,A的第一步淘汰了cache
(2)A的第二步写数据库,发出修改请求
(3)发生了读请求B,B的第一步读取cache,发现cache中是空的
(4)B的第二步读取数据库,发出读取请求,此时A的第二步写数据还没完成,读出了一个脏数据放入cache
即在数据库层面,后发出的请求4比先发出的请求2先完成了,读出了脏数据,脏数据又入了缓存,缓存与数据库中的数据不一致出现了
不一致优化思路
如果能做到先发出的请求先执行完成,那是不是能避免这个问题呢?答案是肯定的。那如何能达到这个目的?这里提供2个思路。
第一个是mysql的可串行化
可串行化——SERIALIZABLE
事务的最高级别,在每个读的数据行上,加上锁,使之不可能相互冲突,因此,会导致大量的超时现象。
同一个数据用同一个链接
在用连接池进行访问数据库的时候,针对同一个数据的DB访问,使用同一个链接进行操作,这样也可以达到先发出的请求完成之后才会进行下一个访问。
转载自:https://zhuanlan.zhihu.com/p/38919743
最新文章
- Elasticsearch 调优 (官方文档How To)
- Bluemix中国版体验(一)
- 分享一段数据库中表数据更新SQL
- sql练习记录
- 细数.NET 中那些ORM框架 —— 谈谈这些天的收获之一
- 使用sp_addextendedproperty添加描述信息
- Java面向对象编程概述
- True Zero Downtime HAProxy Reloads--转载
- Installutil.exe 注册exe
- Android 自定义View可拖动移动位置及边缘拉伸放大缩小
- php快递查询
- mysql 子查询优化
- 02-TypeScript中新的字符串
- HierarchicalClustering:编写HierarchicalClustering层次聚类算法—Jason niu
- RestTemplate -springwebclient
- 如何在servlet中获取spring创建的bean
- 一个困扰了我N久的bug , android.enableAapt2=false 无效
- 关于能量场和力场弯曲空间的实验证明 EXPERIMENTAL PROOF ON THE BENDING SPACE OF ENERGY FIELD AND FORCE FIELD
- 2. Get the codes from GIT
- thrift0.5入门操作