深度学习论文翻译解析(十八):MobileNetV2: Inverted Residuals and Linear Bottlenecks
论文标题:MobileNetV2: Inverted Residuals and Linear Bottlenecks
论文作者:Mark Sandler Andrew Howard Menglong Zhu Andrey Zhmoginov Liang-Chieh Chen
论文地址:https://arxiv.org/pdf/1801.04381.pdf
参考的 MobileNetV2翻译博客:请点击我
(这篇翻译也不错:https://blog.csdn.net/qq_31531635/article/details/80550412)
声明:小编翻译论文仅为学习,如有侵权请联系小编删除博文,谢谢!
小编是一个机器学习初学者,打算认真研究论文,但是英文水平有限,所以论文翻译中用到了Google,并自己逐句检查过,但还是会有显得晦涩的地方,如有语法/专业名词翻译错误,还请见谅,并欢迎及时指出。
如果需要小编其他论文翻译,请移步小编的GitHub地址
传送门:请点击我
如果点击有误:https://github.com/LeBron-Jian/DeepLearningNote


摘要
在本文中,我们描述了一种新的移动端网络架构 MobileNetV2,该架构提高了移动模型在多个任务和多个基准数据集上以及在不同模型尺寸范围内的最佳性能。我们还描述了在我们称之为SSDLite的新框架中将这些移动模型应用于目标检测的有效方法。此外,我们还演示了如何通过 DeepLabv3的简化形式,我们称之为 Mobile DeepLabv3来构建移动语义分割模型。
MobileNetV2 架构基于倒置的残差结构,其中快捷连接位于窄的bottleneck之间。中间展开层使用轻量级的深度卷积作为非线性源来过滤特征。此外,我们发现了表示能力,去除窄层中的非线性是非常重要的。我们证实了这可以提高性能并提供了产生此设计的直觉。
最后,我们的方法允许将输入/输出域与变换的表现力解耦,这为进一步分析提供了便利的框架。我们在 ImageNet[1]分类,COCO目标检测[2],VOC图像分割[3]上评估了我们的性能。我们评估了在精度,通过乘加(Multiply-Adds,MAdd)度量的操作次数,以及实际的延迟和参数的数量之间的权衡。


1,引言
神经网络已经彻底改变了机器智能的许多领域,使具有挑战性的图像识别任务获得了超过常人的准确性。然而,提高准确性的驱动力往往需要付出代价:现在先进网络需要超出许多移动和嵌入式应用能力之外的高计算资源。
本文介绍了一种专为移动和资源受限环境量身定制的新型神经网络架构。我们的网络通过显著减少所需操作和内存的数量,同时保持相同的精度推进了移动定制计算机视觉模型的最新水平。
我们的主要贡献是一个新的层模型:具有线性瓶颈的倒置残差。该模块将输入的低维压缩表示首先扩展到高维并用轻量级深度卷积进行过滤。随后用线性卷积将特征投影回低维表示。官方实现可作为 [4] 中 TensorFlow-Slim 模型库的一部分(https://github.com/tensorflow/ models/tree/master/research/slim/ nets/mobilenet)。
这个模块可以使用任何现代框架中的标准操作来高效的实现,并允许我们的模型使用基线沿多个性能点击败最先进的技术。此外,这种卷积模块特别适用于移动设计,因此它可以通过从不完全实现大型中间张量来显著的减少推断过程中所需的内存占用。这减少了许多嵌入式硬件设计中对主存储器访问的需求,这些设计提供了少量高速软件控制缓存。


2,相关工作
调整深层神经架构以在精确性和性能之间达到最佳平衡已成为过去几年研究活跃的一个领域。由许多团队进行的手动架构搜索和训练算法的改进,已经比早期的设计(如AlexNet【5】,VGGNet【5】,GoogLeNet【7】和ResNet【8】)有了显著的改进。最近在算法架构探索方面取得了很多进展,包括超参数优化【9,10,11】,各种网络修剪方法【12,13,14,15,16,17】和连接学习【18,19】。也有大量的工作致力于改变内部卷积块的连接结构如ShuffleNet【20】或引入稀疏性【21】和其他【22】。
最近,【23,24,25,26】开辟了一个新的方向,将遗传算法和强化学习等优化方法代入架构搜索。然而,一个缺点是是最终所得到的网络非常复杂。在本文中,我们追求的目标是发展了解神经网络如何运行的更好直觉,并使用它来指导最简单可能的网络设计。我们的方法应该被视为【23】中描述的方法和相关工作的补充。在这种情况下,我们的方法与【20,22】所采用的方法类似,并且可以进一步提高性能,同时可以一睹其内部的运行。我们的网络设计基于MobileNetV1【27】。它保留了其简单性,并且不需要任何特殊的运算符,同时显著提高了它的准确性,为移动应用实现了在多种图像分类和检测任务上的最新技术。


3,预备知识,讨论,直觉
3.1 深度可分离卷积
深度可分离卷积对于许多有效的神经网络结构来说都是非常关键的组件(ShuffleNet, MobileNetV1,Xception),而对我们的工作来说,也是如此,基本想法是利用一个分解版本的卷积来代替原来的标准卷积操作,即将标准卷积分解成两步来实现,第一步叫深度卷积,它通过对每个输入通道执行利用单个卷积进行滤波来实现轻量级滤波,第二步是一个1*1卷积,叫做逐点卷积,它负责通过计算输入通道之间的线性组合来构建新的特征。
MobileNet 是一种基于深度可分离卷积的模型,深度可分离卷积是一种将标准卷积分解成深度卷积以及一个 1*1 的卷积即逐点卷积。对于 Mobilenet 而言,深度卷积针对每个单个输入通道应用单个滤波器进行滤波,然后逐点卷积应用 1*1 的卷积操作来结合所有深度卷积得到的输出。而标准卷积一步即对所有的输入进行结合得到新的一系列输出。深度可分离卷积将其分为了两步,针对每个单独层进行滤波然后下一步即结合。这种分解能够有效地大量减少计算量以及模型的大小。
一个标准卷积层输入 DF*DF*M 的特征图 F,并得到一个 DG*DG*N 的输出特征图 G,其中DF 表示输入特征图的宽和高,M是输入的通道数(输入的深度),DG 为输出特征图的宽和高,N是输出的通道数(输出的深度)。
标准卷积层通过由大小为 DK*DK*M*N 个卷积核 K 个参数,其中 DK是卷积核的空间维数,M 是输入通道数,N是输出通道数。
标准卷积的输出卷积图,假设步长为1,则padding由下式计算:
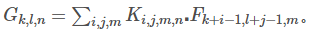
其计算量为 DK*DK*M*N*DF*DF,其由输入通道数 M,输出通道数 N,卷积核大小 DK,输出特征图大小DF 决定。MobileNet 模型针对其进行改进。首先,使用深度可分离卷积来打破输出通道数与卷积核大小之间的互相连接作用。
标准的卷积操作基于卷积核和组合特征来对滤波特征产生效果来产生一种新的表示。滤波和组合能够通过分解卷积操作来分成两个独立的部分,这就叫做深度可分离卷积,可以大幅度降低计算成本。
深度可分离卷积由两层构成:深度卷积和逐点卷积。我们使用深度卷积来针对每一个输入通道用单个卷积核进行卷积,得到输入通道数的深度,然后运用逐点卷积,即应用一个简单的 1*1 卷积来对深度卷积中的输出进行线性结合。Mobilenets 对每层使用 BatchNorm 和 ReLU 非线性激活。
深度卷积对每个通道使用一种卷积核,可以写为:
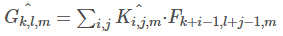
其中 Khat 是深度卷积核的尺寸 DK*DK*M,Khat中第m个卷积核应用于 F中的第 m 个通道来产生第 m 个通道的卷积输出特征图 Ghat。
深度卷积的计算量为:DK*DK*M*DF*DF。
深度卷积相对于标准卷积十分有效,然而其只对输入通道进行卷积,没有对其进行组合来产生新的特征。因此下一层利用另外的层利用1*1 卷积来对深度卷积的输出计算一个线性组合从而产生新的特征。
那么深度卷积加上 1*1 卷积的逐点卷积的结合就叫做深度可分离卷积,最开始在(Rigid-motion scattering for image classification) 中被提出。
深度可分离卷积的计算量为:DK*DK*M*DF*DF + M*N*DF*DF
通过将卷积分为滤波和组合的过滤得到对计算量缩减为:

MobileNet 使用 3*3 的深度可分离卷积相较于标准卷积少了 8~9 倍的计算量,然而只有极小的准确率下降。MobileNetV2 也使用了k=3(3*3 可分离卷积层)。

3.2 线性瓶颈(Linear Bottlenecks)
考虑一个深层神经网络有 n 层 Li 构成,每一层之后都有维数为 hi*wi*di 的激活张量,通过这节我们将会讨论这些激活张量的基本属性,我们可以将其看做具有 di 维的有 hi*wi 像素的容器。非正式的,对于真实图片的输入集,一组层激活(对于任一层 Li)形成一个“感兴趣流形”,长期以来,人们认为神经网络中的感兴趣流形可以嵌入到低维子空间中。换句话说,当我们单独看一层深度卷积层所有 d 维通道像素时,这些依次嵌入到低维子空间的值以多种形式被编码成信息。
这段应该是本文的难点了,我这里结合网上大佬说的,再理解一下:我们认为深度神经网络是由 n 个 Li 层构成,每层经过激活输出的张量为 hi*wi*di,我们认为一连串的卷积和激活层形成一个兴趣流形(mainfold of interest,这就是我们感兴趣的数据内容),现阶段还无法定量的描述这种流形,这里以经验为主的研究这些流形性质。长期依赖,人们认为:在神经网络中兴趣流行可以嵌入到低维子空间,通俗说,我们查看的卷积层中所有单个 d 通道像素时,这些值中存在多种编码信息,兴趣流形位于其中的。我们可以变换,进一步嵌入到下一个低维子空间中(例如通过 1*1 卷积变换维数,转换兴趣流形所在空间维度)。
咋一看,这可以通过简单的约减一层的维度来做到,从而减少了运算空间的维度。这已经在 MobileNetV1 中被采用,通过宽度乘法器来有效对计算量和准确率进行权衡。并且已经被纳入了其他有效的模型设计当中(Shufflenet: An extremely efficient convolutional neural network for mobile devices)。遵循这种直觉,宽度乘法器允许一个方法来减少激活空间的维度直到感兴趣的流形横跨整个空间。然而,这个直觉当我们这知道深度卷积神经网络实际上对每个坐标变换都有非线性激活的时候被打破。就好像 ReLU,比如,ReLU 应用在一维空间中的一条线就产生了一条射线,那么在 Rn 空间中,通常产生具有 n 节的分段线性曲线。

 很容易看到通常如果 ReLU 层变换的输出由一个非零值 S,那么被映射到 S 的点都是对输入经过一个线性变换 B 之后获得,从而表明对应整个维数的输出部分输入空间被限制在为一个线性变换。换句话说,深度网络只对输出域部分的非零值上应用一个线性分类器。我们应用一个补充材料来更加详细的正式描述。
很容易看到通常如果 ReLU 层变换的输出由一个非零值 S,那么被映射到 S 的点都是对输入经过一个线性变换 B 之后获得,从而表明对应整个维数的输出部分输入空间被限制在为一个线性变换。换句话说,深度网络只对输出域部分的非零值上应用一个线性分类器。我们应用一个补充材料来更加详细的正式描述。
另一方面,当没有ReLU作用通道时,那么必然失去了那个通道的信息。然而,如果我们通道数非常多时,可能在激活流形中有一个结构,其信息仍然被保存在其他的通道中。在补充材料中,我们展示了如果输入流形能嵌入到一个显著低维激活子空间中,那么ReLU激活函数能够保留这个信息同时将所需的复杂度引入到表达函数集合中。


总的来说,我们已经强调了两个性质,他们表明了感兴趣的流形应该存在于高维激活空间中的一个低维子空间中的要求。
1,如果感兴趣流形在ReLU之后保持非零值,那么它对应到一个线性变换。
2,ReLU 能够保存输入流形的完整信息,但是输入流形必须存在于输入空间的一个低维子空间中。
这两点为我们优化现有神经网络提供了经验性的提示:假设感兴趣流形是低维的,我们能够通过插入线性瓶颈层到卷积块中来得到它。经验性的证据表明使用线性是非常重要的,因为其阻止了非线性破坏了太多的信息。在第6节中,我们展示了经验性的在瓶颈中使用非线性层使得性能下降了几个百分点,这更加进一步的验证了我们的假设。我们注意到有类似的实验在(Deep pyramidal residual networks)中,即传统的残差块的输入中去掉非线性结果提升了在 CIFAR 数据集的性能。论文的接下来部分,我们将利用瓶颈卷积,我们将输入瓶颈尺寸和内部尺寸的比值称为扩展率。

图1,低维流形嵌入到高维空间的ReLU转换的例子。在这些例子中,一个原始螺旋形被利用随机矩阵 T 经过 ReLU 后嵌入到一个 n 维空间中,然后使用 T-1 投影到二维空间中。例子中,n=2,3 导致信息损失,可以看到流形的中心点之间的互相坍塌。同时 n=15, 30 时的信息变成高度非凸。
此图表明:如果当前激活空间内兴趣流形完整度较高,经过ReLU,可能会让激活空间坍塌,不可避免的会丢失信息,所以我们设计网络的时候,想要减少运算量,就需要尽可能将网络维度设计的低一些但是维度如果低的话,激活变换ReLU函数可能会滤除很多有用信息。然后我们就想到了,反正ReLU另外一部分就是一个线性映射,那么如果我们全用线性分类器,会不会就不会丢失一些维度信息,同时可以设计出维度较低的层呢?。
所以论文针对这个问题使用Linear Bottleneck(即不使用ReLU激活,做了线性变换)的来代替原本的非线性激活变换。到此,优化网络架构的思想也出来了:通过在卷积模块中后插入 linear bottleneck来捕获兴趣流形。实验证明,使用linear bottleneck 可以防止非线性破坏太多信息。
从linear bottleneck 到深度卷积之间的维度比成为 Expansion factor(扩展系数),该系数控制了整个 block 的通道数。
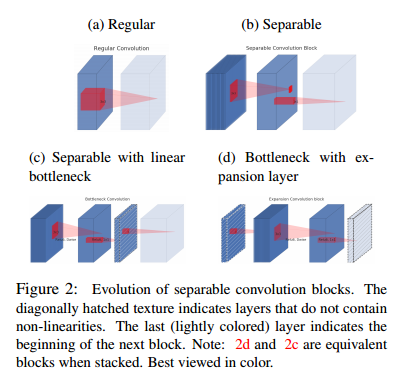
图2,深度可分离卷积的演化过程。对角线阴影纹理表示层不含非线性。最后的浅色层表示下一个卷积块的起始。注意:d和c从颜色上可以看出是等效块。


3.3 反向残差(Inverted residuals)
瓶颈块看起来与残差块相同,每个块包含一个输入接几个瓶颈然后进行扩展。然而,受到直觉的启发,瓶颈层实际上包含了所有必要的信息,同时一个扩展层仅仅充当实现张量非线性变换的实现细节部分,我们直接在瓶颈层之间运用 shortcuts,图3提供了一个设计上差异的可视化。插入 shortcuts 的动机与典型的残差连接相同,我们想要提升在多层之间梯度传播的能力,然而,反向设计能够提高内存效率(第五节详细描述)以及在我们的实验中变现的更好一些。
瓶颈层的运行时间和参数量,基本的实现结构在表1中体现。对于一个大小为 h*w 的块,扩展因子 t 和卷积核大小 k, 输入通道数为 d ' ,输出通道数为 d '' ,那么乘加运算有:
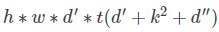
与之前的计算量比较,这个表达式多出了一项,因为我们有额外的 1*1 卷积,然而我们的网络性质允许我们利用更小的输入和输出的维度。在表3中我们比较了不同分辨率下的 MobileNetV1,MobileNetV2,ShuffleNet 所需要的尺寸大小。
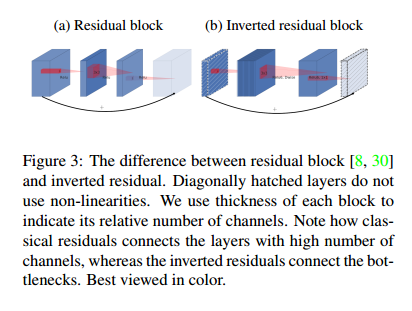
图3:残差块在(Aggregated residual transformations for deep neural networks.)与ResNet的不同。对角线阴影层没有用非线性,块中的厚度表示相关的通道数,注意到,经典的残差连接的层都是通道数非常多的层,然而,反向残差连接的是瓶颈层。

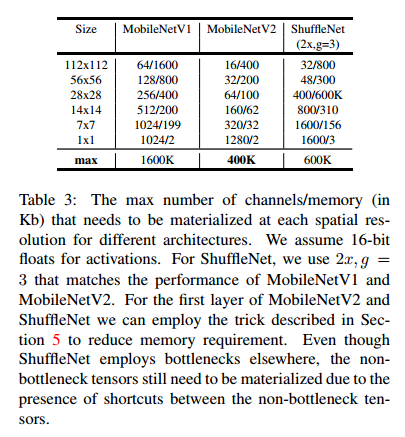
表3 在不同结构的每个空间分辨率下都需要实现通道数/内存的最大值。假设激活需要 16bit,对于 ShuffleNet,我们使用 2x,g=3来匹配 MobileNetV1,MobileNetV2。对于MobileNetv2 和 ShuffleNet 的第一层而言,我们利用在第5节中的技巧来减少内存的需要。虽然 ShuffleNet 在其他地方利用了瓶颈,非瓶颈张量由于非瓶颈张量之间的 shortcuts 存在仍然需要被实现。

3.4 信息流解释
我们结构的一个特性在于构建块(瓶颈层)的输入输出域之间提供一个自然分离,并且层变换这是一种输入到输出之间的非线性函数。前者能看成是网络每层的容量,而后者看做是网络的表达能力。这与传统卷积块相反,传统卷积块的正则化和可分离性,在表达能力和容量都结合在一起,是输出层深度的函数。
特别的,在我们的例子中,当内层深度为0时,下面层卷积由于 shortcuts 变成了恒等函数。当扩展率小于1时,这就变成了一个经典的残差卷积块。然而,为了我们的目的,当扩展率大于1时是最有效的。
这个解释允许我们从网络的容量来研究网络的表达能力,而且我们相信对可分离性更进一步探索能够保证对网络的性质理解更加深刻。


4,模型结构
现在我们详细的描述我们的模型结构。就像前面提到的一样,基本的构建块是残差瓶颈深度可分离卷积块,块的详细结构在表1中可以看到。MobileNetV2包含初始的 32个卷积核的全连接层,后接 19 个残差瓶颈层(如表2),我们使用 ReLU6 作为非线性激活函数,用于低精度计算时,ReLU6 激活函数更加鲁棒。我们总使用大小为 3*3 的卷积核,并且在训练时利用 dropout 和 batchnorm 规范化。
除开第一层之外,我们在整个网络中使用常数扩展率。在我们的实验中,我们发现扩展率在 5~10 之间几乎有着相同的性能曲线。随着网络规模的缩小,扩展率略微降低效果更好,而大型网络有更大的扩展率,性能更佳。
我们主要的实验部分来说,我们使用扩展率为6应用在输入张量中。比如,对于一个瓶颈层来说,输入为 64 通道的张量,产生一个 128 维的张量,内部扩展层就是 64*6=384 通道。

权衡超参数 就像MobileNetV1 中的一样,我们对于不同的性能要求制定不同的结构。通过使用输入图像分辨率以及可调整的宽度乘法器超参数来根据期望的准确率/性能折中来进行调整。我们先前的工作(宽度乘法器,1,224*224),有大约3亿的乘加计算量以及使用了340万的参数量。我们探索对输入分辨率从 96 到 224,宽度乘法器从 0.35 到 1.4 来探索性能的权衡。网络计算量从 7 变成了 585MMads,同时模型的尺寸变换影响参数量从1.7M到 6.9M。
与MobileNetV1 实现小小不同的是,MobileNetV1 的宽度乘法器的取值小于1,除了最后一层卷积层,我们对所有层都应用了宽度乘法器,这对于小模型提升了性能。
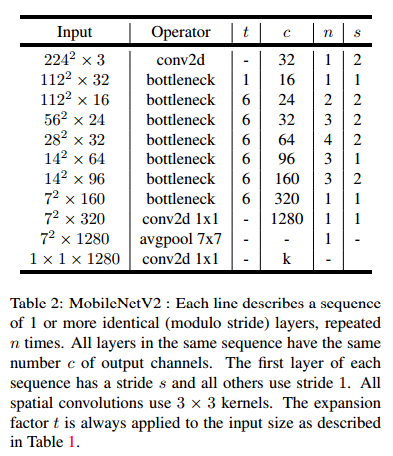
表2 MobileNetV2 :每行描述了1个或多个相同的层的序列,重复 n 次。所有序列相同的层有相同的输出通道数c,第一层的序列步长为s,所有其他的层都用步长为1,所有空间卷积核使用 3*3 的大小,扩展因子 t 总是应用在表1描述的输入尺寸中。
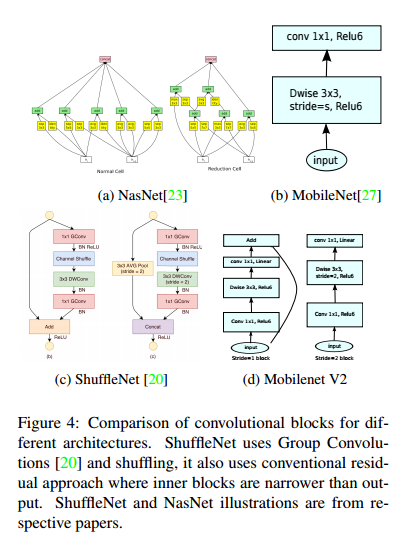
这里再来聊一下,MobileNet V2 的网络模块样式,其样式如下(和上面差不多,不过我这里拿了网页的图):
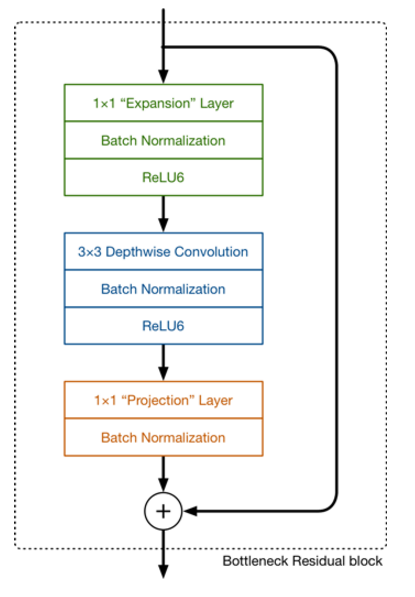
我们知道,MobileNetV1 网络主要思想就是深度可分离的卷积的堆叠。在V2的网络设计中,我们除了继续使用深度可分离(中间那个)结构之外,还使用了Expansion layer 和 Projection layer。这个 projection layer 也使用 1*1 的网络结构将高维空间映射到低维空间的设计,有些时候我们也将其称之为 Bottleneck layer。
而 Expansion layer 的功能正好相反,使用1*1 的网络结构,目的是将低维空间映射到高维空间。这里 Expansion 有一个超参数是维度扩展几倍。可以根据实际情况来做调整的,默认是6,也就是扩展6倍。
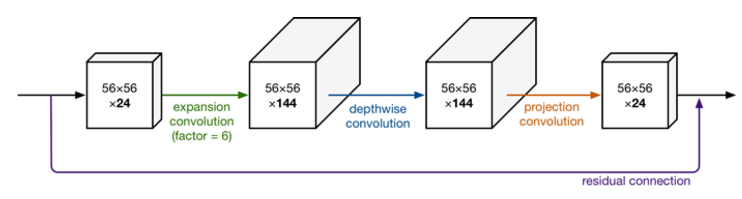
此图也更加详细的展示了整个模块的结构。我们输入是 24维,最后输出也是 24维。但这个过程中,我们扩展了6倍,然后应用深度可分离卷积进行处理。整个网络是中间胖,两头窄,像一个纺锤型。而ResNet中 bottleneck residual block 是两头胖中间窄,在MobileNet V2中正好相反,所以我们MobileNet V2中称为 inverted rediduals。另外,residual connection 是在输入和输出的部分进行连接。而linear bottleneck 中最后projection conv 部分,我们不再使用ReLU激活函数而是使用线性激活函数。



5,执行记录
5.1 内存有效管理
反向残差瓶颈层允许一个特别的内存有效管理方式,这对于移动应用来说非常重要。一个标准有效的管理比如说 TensorFlow或者 Caffe,构建一个有向无环计算超图G,由表示操作的边和表示内部计算的张量构成。为了最小化需要存储在内存中的张量数,计算是按顺序进行的。在最一般的情况下,其搜索所有可能的计算顺序 ΣG,然后选能够最小化下式的顺序。
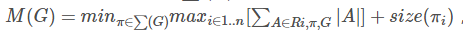
其中 R(i, π, G) 是与任意点{ π1, π2,....πn}相连接的中间张量列表。 |A| 表示张量 A的模,size(i) 表示 i 操作期间,内部存储所需要的内存总数。
对于只有不重要的并行结构的图(如残差连接),只有一个重要可行的计算顺序,因此在测试时所需要的总的内存在计算图G中可以简化为:
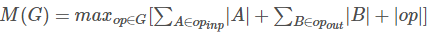 所有操作中,内存量只是结合输入和输出的最大总的大小,在下文中,我们展示了如果我们将一个瓶颈残差块看做一个单一操作(并且将内部卷积看做一个一次性的张量),总的内存量将会由瓶颈张量的大小决定,而不是瓶颈内部的张量大小决定(这可能会更大)。
所有操作中,内存量只是结合输入和输出的最大总的大小,在下文中,我们展示了如果我们将一个瓶颈残差块看做一个单一操作(并且将内部卷积看做一个一次性的张量),总的内存量将会由瓶颈张量的大小决定,而不是瓶颈内部的张量大小决定(这可能会更大)。



瓶颈残差块 图3b 中所示的 F(x) 可以表示为三个运算符的组合 F(x)=[A*N*B]x,其中A是线性变换 ,N是一个非线性的每个通道的转换,B是输出域的线性转换。
对于我们的网络 N=ReLU6*dwise*ReLU6,但结果适用于任何的按通道转换。假设输入域的大小是 |x| 并且输出域的大小是 |y|,那么计算 F(X) 所需要的内存可以低至 |s2k|+|s'2k'|+o(max(s2, s'2))。
该算法基于以下事实:内部张量 L 可以表示为 t 张量的连接,每个大小为 n/t,则我们的函数可以表示为:
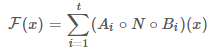
通过累加和,我们只需要将一个大小为 n/t 的中间块始终保留在内存中。使用 n=t ,我们最终只需要保留中间表示的单个通道。这使得我们能够使用这一技巧的两个约束是(a)内部变换(包括非线性和深度)是每个通道的事实,以及(b)连续的非按通道运算符具有显著的输入输出大小比,对于大多数传统的神经网络,这种技巧不会产生显著的改变。
我们注意到,使用 t 路分割计算 F(X) 所需的乘加运算符的数目是独立于 t 的,但是在现有实现中,我们发现由于增加的缓存未命中,用几个较小的矩阵乘法替换一个矩阵乘法会很损坏运行时的性能。我们发现这种方法最有用,t 是 2和5之间的一个小常数。它显著的降低了内存需求,但仍然可以利用深度学习框架提供的高度优化的矩阵乘法和卷积算子来获得的大部分效率。如果特殊的框架优化可能导致进一步的运行时改进,这个方法还有待观察。


6,实验
6.1 ImageNet 分类
训练设置 我们利用 TensorFlow 训练模型,实验标准的 RMSProp 优化方法,并且衰减率和动量都设置为 0.9,我们在每一层之后都使用 batch normalization ,标准的权重衰减设置为 0.00004,接着 MobilenetV1 的设置,我们使用初始学习率为 0.045,学习率衰减为每个 epoch 衰减 0.98,我们使用 16 个 GPU 异步工作器并且使用 96个作为 batch size。
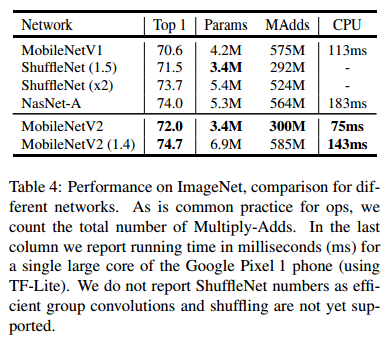
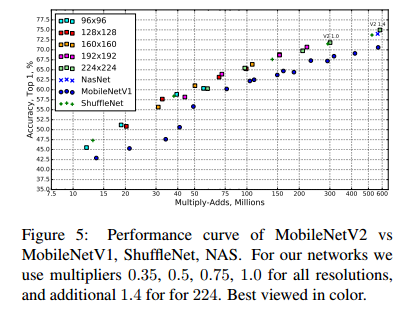
结果 我们与MobileNetV1,ShuffleNet,NASNet-A 模型进行比较,几个模型的统计数据如表4.性能的比较在图5中。

6.2 目标检测
我们评估和比较MobileNetV2和 MobileNetV1的性能,MobileNetV1 使用了 COCO数据集【2】上 Single Shot Detector(SSD)【34】的修改版本作为目标检测的特征提取器【33】。我们还将 YOLOv2【35】和原始SSD(以VGG-16为基础网络)作为基准进行比较。由于我们专注于移动/实时模型,因此我们不会比较 Faster RCNN 【36】和 RFCN【37】等其他架构的性能。
SSDLite 在本文中,我们将介绍常规SSD的移动友好型变种,我们在SSD 预测层中用可分离卷积(深度方向后接 1*1 投影)替换所有常规卷积。这种设计符合 MobileNets 的整体设计,并且在计算上效率更高。我们称之为修改版本的 SSDLite。与常规SSD相比,SSDLite显著降低了参数计数和计算成本,如表5所示。
对于 MobileNet V1,我们按照【33】中的设置进行,对于 MobileNet V2,SSDLite 的第一层被附加到层15的扩展(输出步长为 16),SSDLite层的第二层和其余层连接在最后一层的顶部(输出步长为32)。此设置与MobileNetV1 一致,因为所有层都附加到相同输出步长的特征图上。

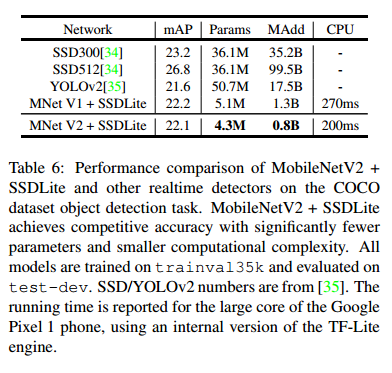
MobileNet 模型都经过了开源 TensorFlow 目标检测 API 的训练和评估【38】。两个模型的输入分辨率为 320*320。我们进行了基准测试并比较了 mAP(COCO挑战度量标准),参数数量和 Multiply-Adds 数量。结果如表6所示。MobilenetV2 SSDLite 不仅是最高效的模型,而且也是三者中最准确的模型。值得注意的是,MobilenetV2 SSDLite 效率高20倍,模型要小10倍,但仍然优于 COCO 数据集上的 YOLOv2 。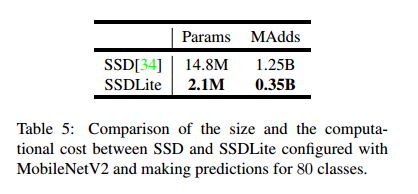


6.3 语义分割
在本节中,我们使用 MobileNetV1 和 MobileNetV2 模型作为特征提取器与 DeepLabv3【39】在移动语义分割任务上进行比较。DeepLabV3 采用了空洞卷积【40, 41, 42】,这是一种显式控制计算特征映射分辨率的强大工具,并构建了五个平行头部,包括(a)包含三个具有不同空洞率的 3*3 卷积的 Atrous Spatial Pyramid Pooling 模块(ASPP),(b)1*1 卷积头部,以及(c)图像级特征【44】。我们用输出步长来表示输入图像空间分辨率与最终输出分辨率的比值,该分辨率通过适当地应用空洞卷积来控制。对于语义分割,我们通常使用输出 stide=16或8来获取更密集的特征映射。我们在 PASCAL VOC 2012 数据集上进行了实验,使用【45】中的额外标注图像和评估指标mIOU。
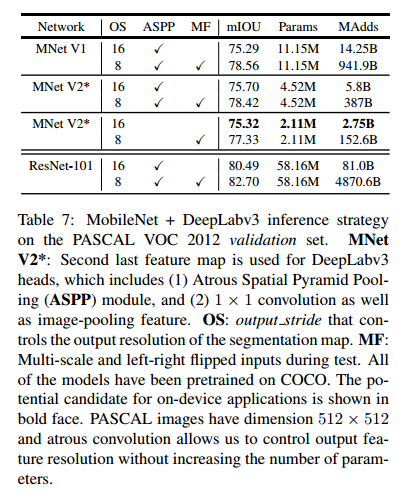
为了构建移动模型,我们尝试了三种设计变体:(1)不同的特征提取器,(2)简化 DeepLabv3 头部以加快计算速度,以及(3)提高性能的不同推断策略。我们的结果总结在表7中。我们已经观察到:(a)包括多尺度输入和添加左右翻转图像的推断策略显著增加了 MAdds,因此不适合于在设备上应用,(b)使用输出步长16比使用输出步长8更有效率,(c)MobileNetV1 已经是一个强大的特征提取器,并且只需要比 ResNet-101 少约 4.9~5.7倍的 MAdds【8】(例如,mIOU: 78.56 与 82.70和 MAdds:941.9B vs 4870.6B ),(d)在MobileNet V2的倒数第二个特征映射的顶部构建 DeepLabv3 头部比在原始的最后一个特征映射上更高效,因为倒数第二个特征映射包含 320 个通道而不是 1280个通道,这样我们就可以达到类似的性能,但是要比 MobileNet V1 的通道数少 2.5 倍,(e)DeepLabv3 头部的计算成本很高,移除 ASPP模块会显著减少 MAdds并且只会稍稍降低性能。在表7末尾,我们鉴定了一个设备上的潜在候选应用(粗体),该应用可以达到 75.32% mIOU 并且只需要 2.75B MAdds。

6.4 模块简化测试
倒置残差连接。 残差连接的重要性已经被广泛研究【8, 30, 46】。本文报告的新结果是连接瓶颈的快捷连接性能优于连接扩展层的快捷连接(请参见图6b以供比较)。
线性瓶颈的重要性。线性瓶颈模型的严格来说比非线性模型要弱一些,因为激活总是可以在线性状态下进行,并对偏差和缩放进行适当的修改。然而,我们在图 6a 中展示的实验表明,线性瓶颈改善了性能,为非线性破坏低维空间中的信息提供了支持。

7,结论和未来工作
我们描述了一个非常简单的网络结构,允许我们能够构建一个高效的移动端模型。我们的基础构建单元有一个特殊的属性使得其更加适合移动应用。其能实现内存管理更加高效并且能够在所有神经框架上的标准操作来实现。
对于 ImageNet 数据集,我们的结构对于性能点的广泛范围提升到了最好的水平。
对于目标检测任务,就COCO数据集上的准确率和模型复杂度来说,我们的网络优于最好的实时检测器模型。尤其,我们的模型与 SSDLite 检测模块结合,相较于 YOLOV3而言,计算量少了 20多倍,参数量少了 10多倍。
理论层面,提出的卷积块有一个独一无二的性质,即从网络的容量(由瓶颈输入进行编码)中分离出网络的表达能力(对扩展层进行编码),探索这个是未来研究的一个重要方向。
最新文章
- [.net 面向对象程序设计进阶] (1) 开篇
- background-size扫盲
- Javascript获取地址栏参数值
- 英文 数字 不换行 撑破div容器
- asp:保留两位小数:
- MySQL数据库恢复(使用mysqlbinlog命令)
- easy ui 学习笔记,不断整理中............
- 允许Ubuntu14.04"保存"屏幕亮度值
- 单词计数,杭电0j-2072
- Java 调用python说明文档
- eclipse自身导致的项目问题:上边提示需要移除无用包,下边类提示需要导入包。
- Javascript高级编程学习笔记(85)—— Canvas(2)2D上下文
- 用powermock 方法中new对象
- SVN添加用户
- npm安装cnpm、vue、react
- linux 下通过xhost进入图形界面,经常会出现报错“unable to open display”
- THML
- POJ 1486 Sorting Slides(二分图完全匹配必须边)题解
- ES6展开运算符的3个用法
- Oracle12cr1新特性之容器数据库(CDB)和可插拔数据库(PDB) 的启动和关闭