基于python的数学建模---轮廓系数的确定
2024-10-20 11:53:42
直接上代码
from sklearn import metrics
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn import preprocessing
import pandas as pd data = pd.read_csv('tae.csv')
info_scaled = preprocessing.scale(data)
X = info_scaled
score = []
for i in range(2, 18):
km = KMeans(n_clusters=i, init='k-means++', n_init=10, max_iter=300, random_state=0)
km.fit(X)
score.append(metrics.silhouette_score(X, km.labels_, metric='euclidean'))
plt.figure(dpi=150)
plt.plot(range(2, 18), score, marker='o')
plt.xlabel('Number of clusters')
plt.ylabel('silhouette_score')
plt.show()
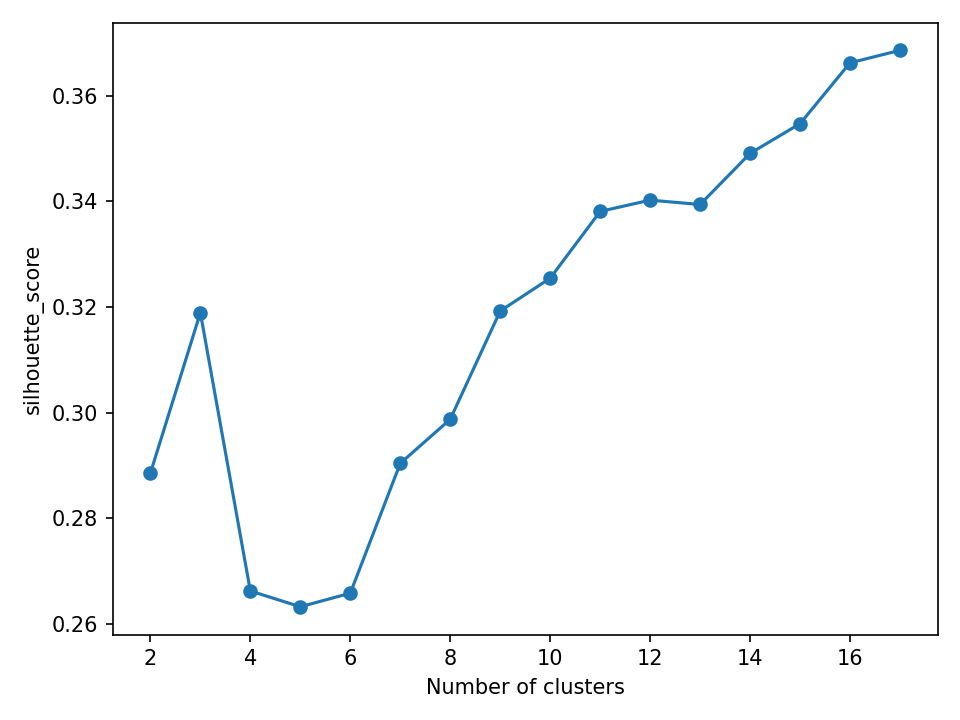
点越高,结果就越准确
最新文章
- SharePoint Online 申请试用链接地址
- SQL Server 递归
- 基于jquery封装的颜色下拉选择框
- 30天C#基础巩固-----多态,工厂模式
- 让 innerHTML 进来的 script 代码跑起来
- paip.指针 引用 c++ java的使用总结.
- php面试题之三——PHP语言基础(基础部分)
- epoll 应用
- linux下重启mysql php nginx
- python杂记-1(os模块)
- Linux远程文件传输
- POJ 3070 Fibonacci(矩阵快速幂)
- openstacks
- linux视频学习4(crontab和进程)
- 成为一名Java架构师的必修课
- 常见的js算法
- 网络编程 -- RPC实现原理 -- RPC -- 迭代版本V1 -- 本地方法调用
- linux网卡eth1如何修改为eth0
- Github 指令上手 --- 分支
- linux中tree命令