scrapy 在爬取过程中抓取下载图片
2024-10-19 21:07:03
先说前提,我不推荐在sarapy爬取过程中使用scrapy自带的 ImagesPipeline 进行下载,是在是太耗时间了
最好是保存,在使用其他方法下载
我这个是在 https://blog.csdn.net/qq_41781877/article/details/80631942 看到的,可以稍微改改来讲解
文章不想其他文章说的必须在items.py 中建立 image_urls和image_path ,可以直接无视
只需要yield返回的item中有你需要的图片下载链接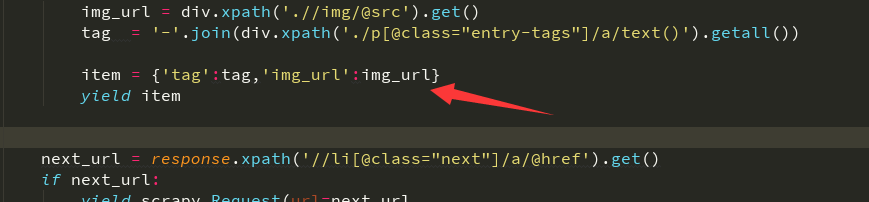
设置mid中的ua和ip,异常情况啥的,接下来是在pip中借用scrapy自带的图片下载类
ImagesPipeline 接下来基本是固定模板,创建一个类三个函数,都是固定的,除了方法可能根据需求改写 pip文件重写
from scrapy.pipelines.images import ImagesPipeline
from scrapy.exceptions import DropItem import re
import scrapy class SaveImagePipeline(ImagesPipeline):
# 使用这个类,运行的第一个函数是这个get_media_requestsdef get_media_requests(self, item, info):# 下载图片,如果传过来的是集合需要循环下载
# meta里面的数据是从spider获取,然后通过meta传递给下面方法:file_path
# yield Request(url=item['url'],meta={'name':item['title']}) # 这是我自己改的,根据yield给的tag和img_url切割得到一个图片名,传递给下一个函数
name = item['tag'] + item['img_url'].split('/')[-1]
yield scrapy.Request(url=item['img_url'], meta={'name':name}) # 第三个运行函数,判断有没有保存成功 ,我该写了没有保存成功者保存在本地文件中,以后进行抓取
def item_completed(self, results, item, info):
# 是一个元组,第一个元素是布尔值表示是否成功
if not results[0][0]:
with open('img_error.txt', 'a')as f:
error = str(item['tag']+' '+item['img_url'])
f.write(error)
f.write('\n')
raise DropItem('下载失败')
return item
# 第二个运行函数
# 重命名,若不重写这函数,图片名为哈希,就是一串乱七八糟的名字
def file_path(self, request, response=None, info=None):
# 接收上面meta传递过来的图片名称
# 我写的图片名
name = request.meta['name']
# 根据情况来选择,如果保存图片的名字成一个体系,那么可以使用这个
image_name = request.url.split('/')[-1]
# 清洗Windows系统的文件夹非法字符,避免无法创建目录
folder_strip = re.sub(r'[?\\*|“<>:/]', '', str(name))
# 分文件夹存储的关键:{0}对应着name;{1}对应着image_guid
# filename = u'{0}/{1}'.format(folder_strip, image_name) # 如果有体系,可以使用这个
filename = u'{0}'.format(folder_strip)
return filename
接下来在settings中设置文件放置在哪
IMAGES_STORE = ‘./meizi’ # meizi是放置图片的文件夹,随意设置名字
# 打开pip
ITEM_PIPELINES = {
'爬虫.pipelines.SaveImagePipeline': 300,
}
,如果图片有反爬,可以设置一个referer
我的如下 ,连同ua一起设置
import user_agent
class Girl13_UA_Middleware(object):
def process_request(self, request, spider):
request.headers['User_Agent'] = user_agent.generate_user_agent()
referer = request.url
if referer:
request.headers['Referer'] = referer
settings中将这个中间件mid设置为1
不过用这个还是很多下载出现错误404 ,虽然有一些下载下来了,五五开吧
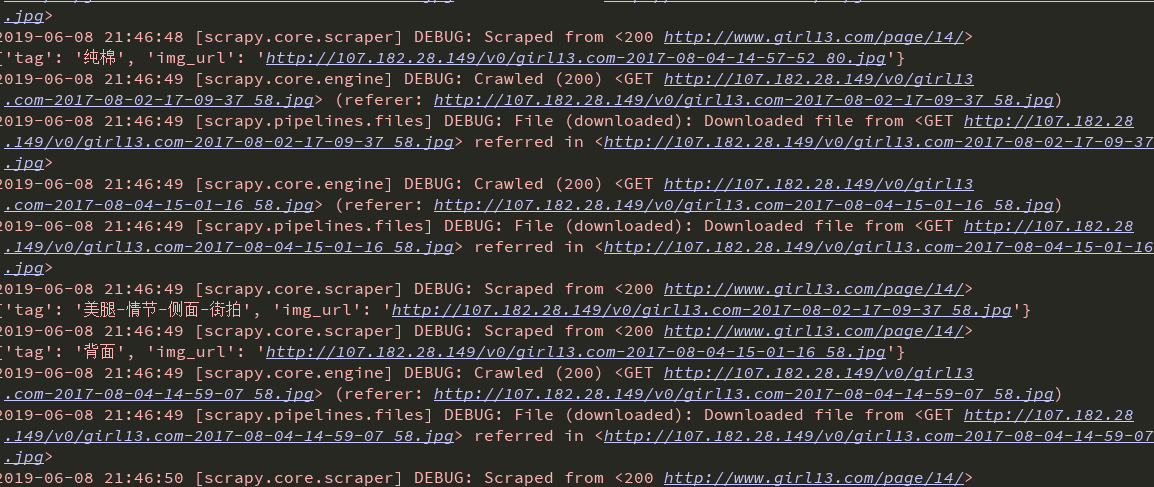
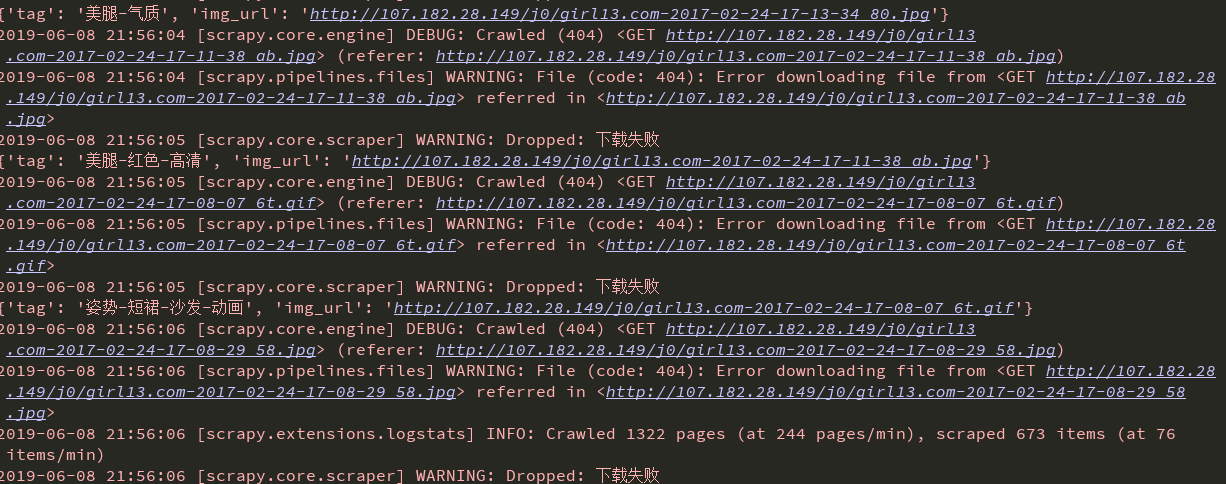
要么一堆一次成功,要么一堆错误,有可能是ip访问频率问题吧,下次我再试试
github源码地址 https://github.com/z1421012325/girl13_spider
最新文章
- 给linux安全模块LSM添加可链式调用模块(一)
- 1497: [NOI2006]最大获利 - BZOJ
- 理解SVG坐标系统和变换: transform属性
- python 学习笔记整理
- power desinger 学习笔记<二>
- char和int的转换
- swift闭包-备
- python高级编程(第12章:优化学习)3
- ThinkPHP3.2 生成二维码
- 【BZOJ3924】幻想乡战略游戏(动态点分治)
- hadoop学习视频
- MySql:SELECT 语句(四)通配符的使用
- 解决Tomcat v6.0 Server at localhost was unable to start within 45 seconds
- C++中,关于#include<***.h>和#include"***.h"的区别
- Java 默认事务级别read committed对binlog_format的需求
- jquery全部版本
- return, break and continue
- java虚拟机-垃圾回收算法
- eclipse问题 - windows版
- java语言描述 用抽象类模拟咖啡机的工作