hadoop克隆三台虚拟机安装JDK和hadoop并配置环境变量
首先将模板虚拟机关机,进行对模板虚拟机的克隆。
选择完整克隆
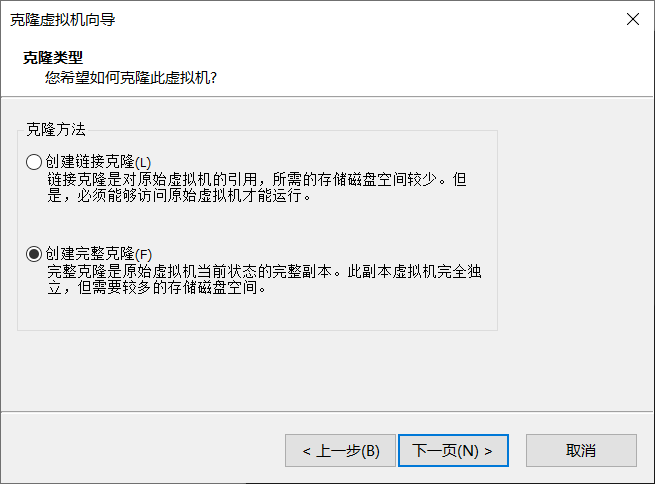
克隆三台虚拟机。
注意虚拟机的移除与删除
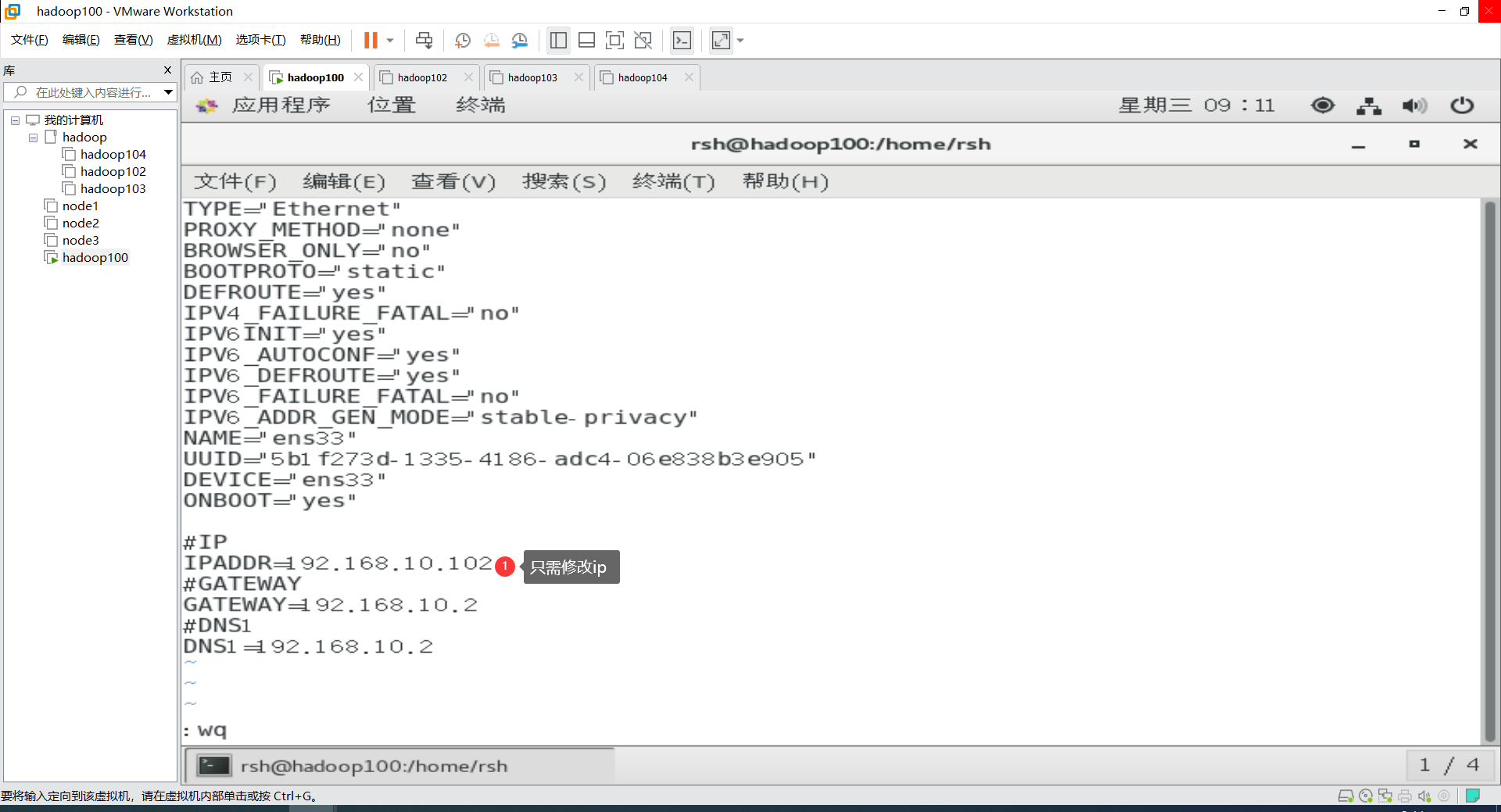
打开hadoop102,修改ip地址与hostname
切换至root用户,或以root用户登录
vim /etc/sysconfig/network-scripts/ifcfg-ens33
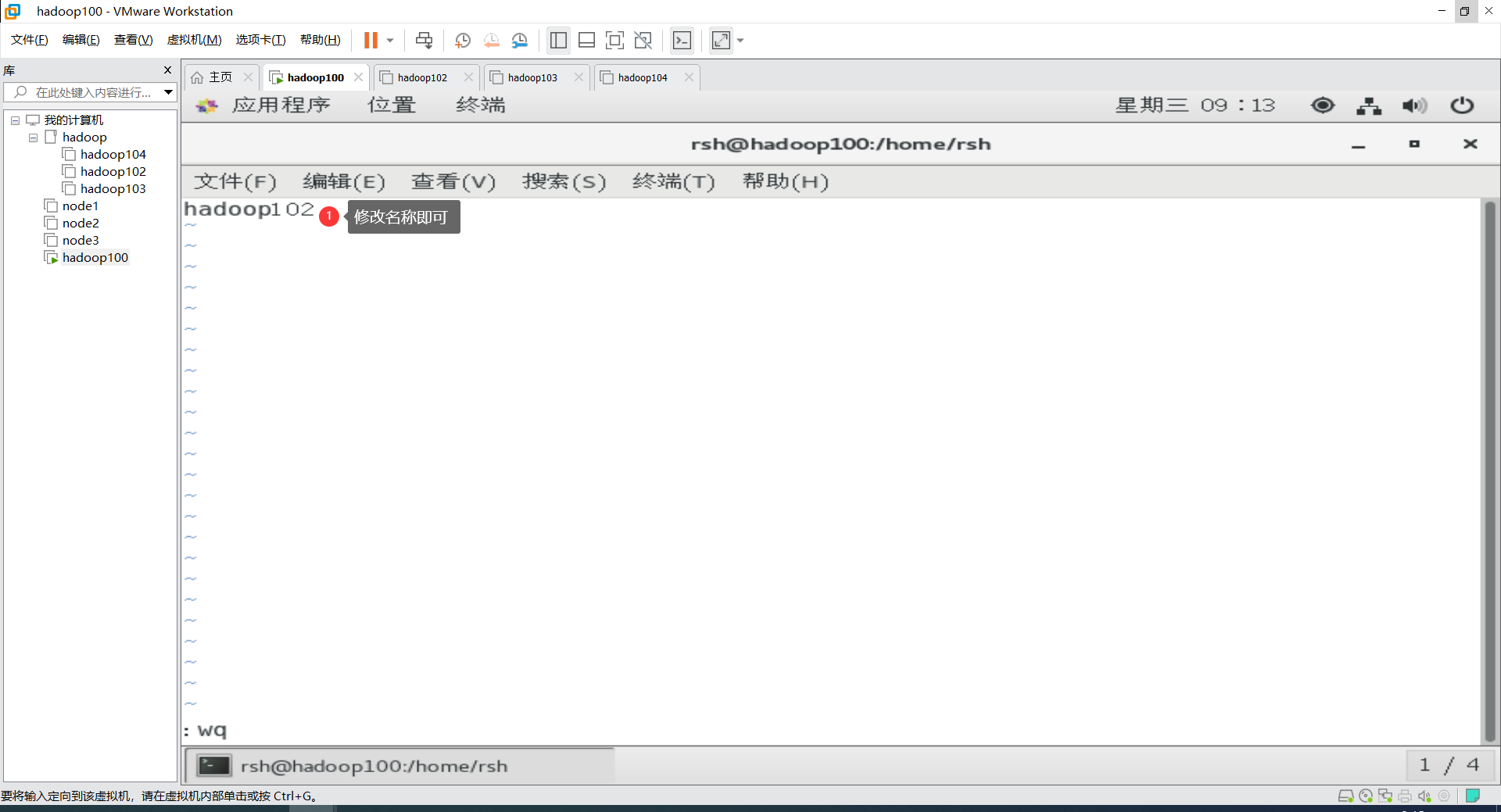
vim /etc/hostname
然后reboot
对hadoop103、hadoop104重复上述操作。
安装JDK与hadoop
先在hadoop102上进行安装,然后拷贝到103、104.
使用xftp将JDK、Hadoop资料上传到hadoop102 的/opt/software 文件夹下
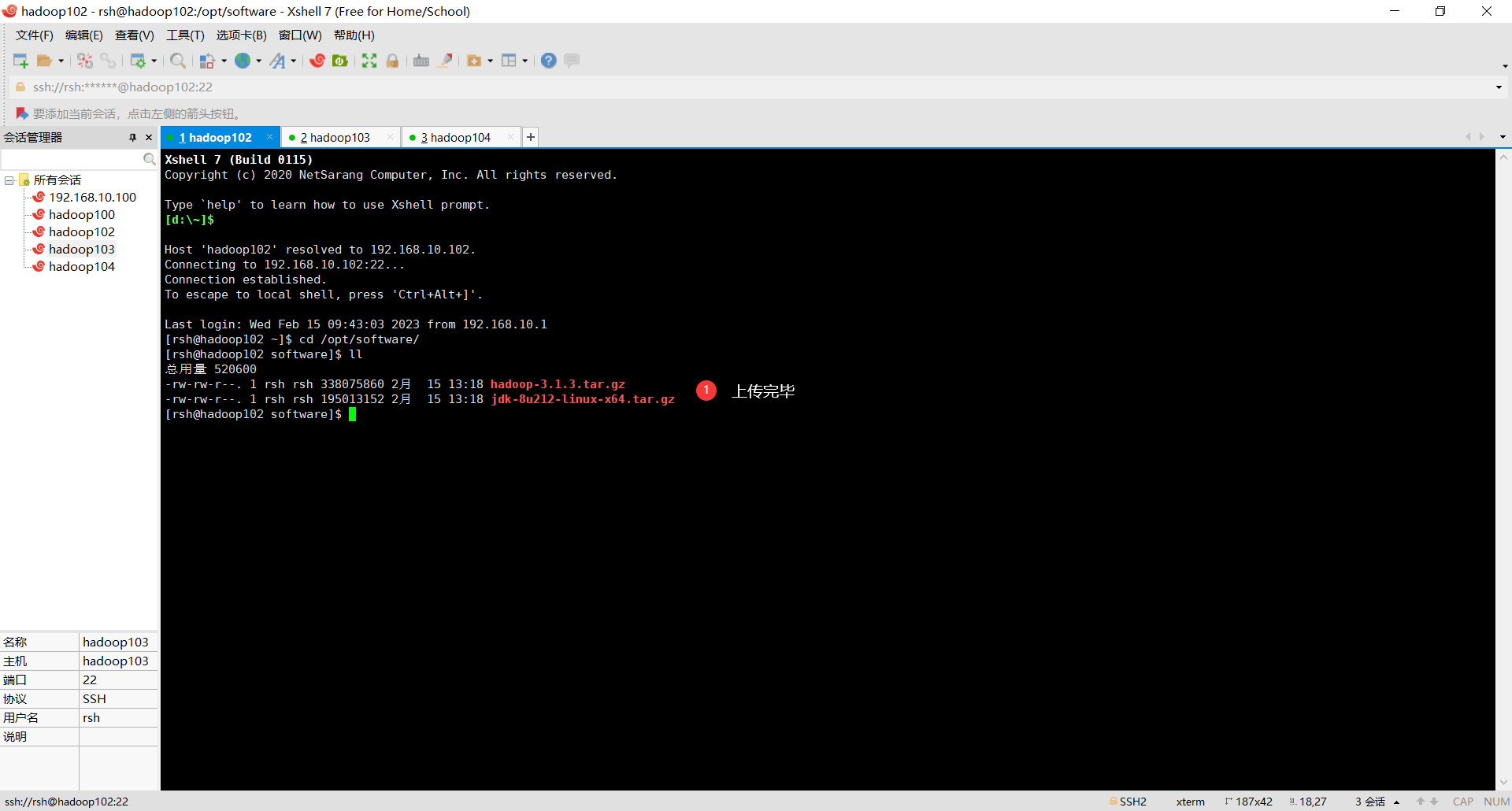
将JDK的jar包解压到/opt/module中
tar -zxvf jdk.... -C /opt/module
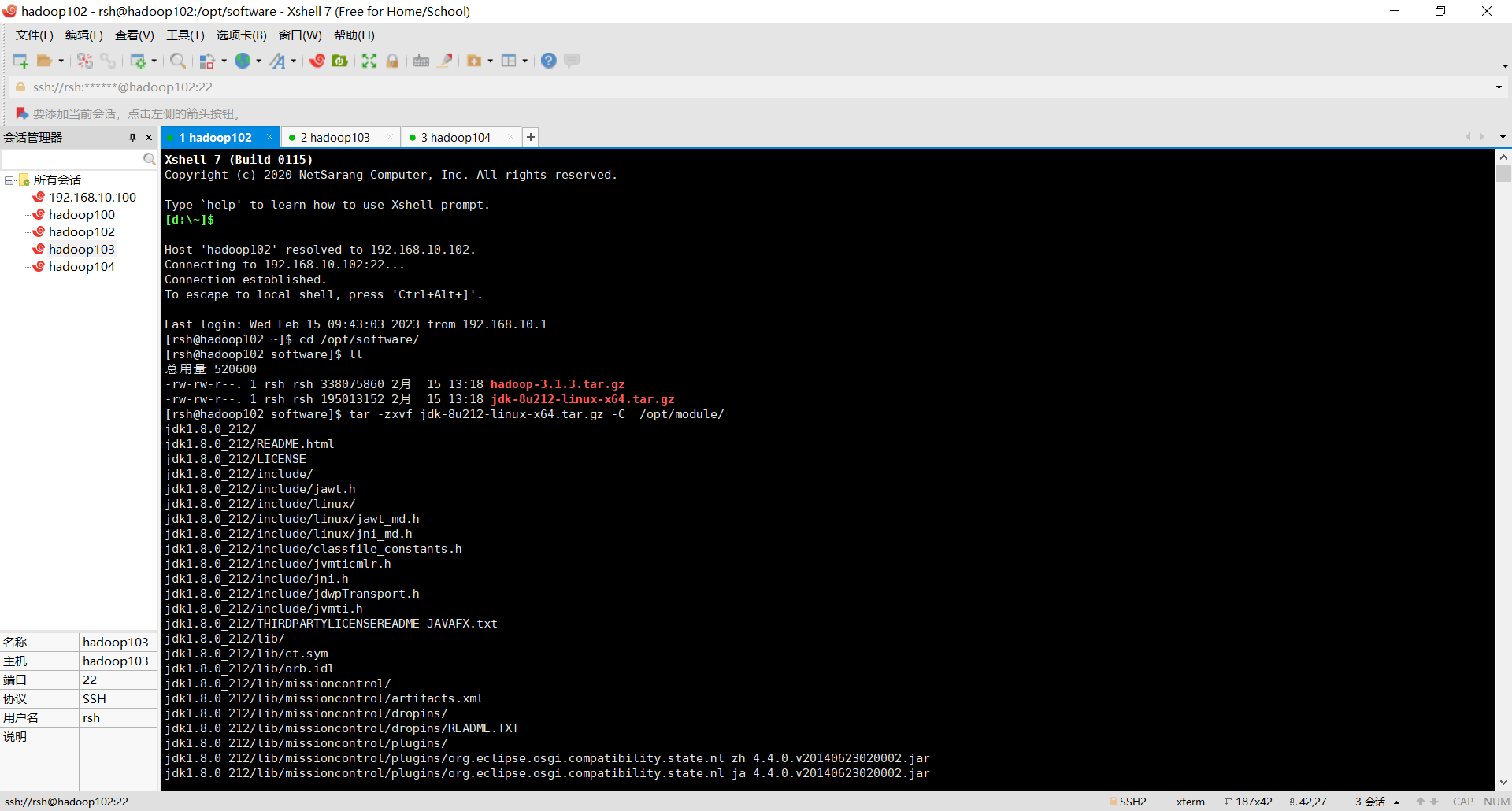
查看安装的JDK
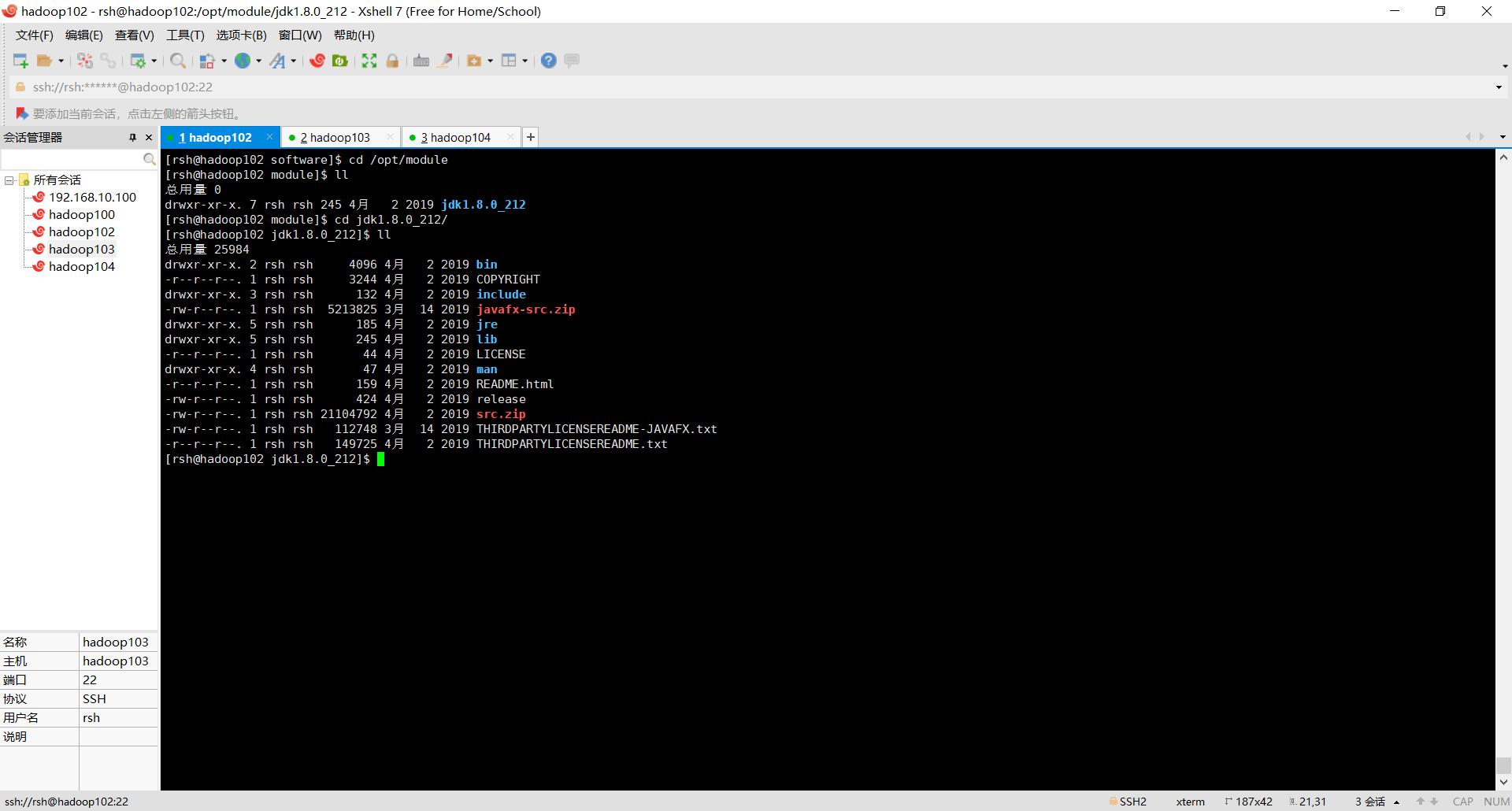
配置环境变量
sudo cd /etc/profile.d
sudo cd /etc/profile.d/
ll显示配置文件.
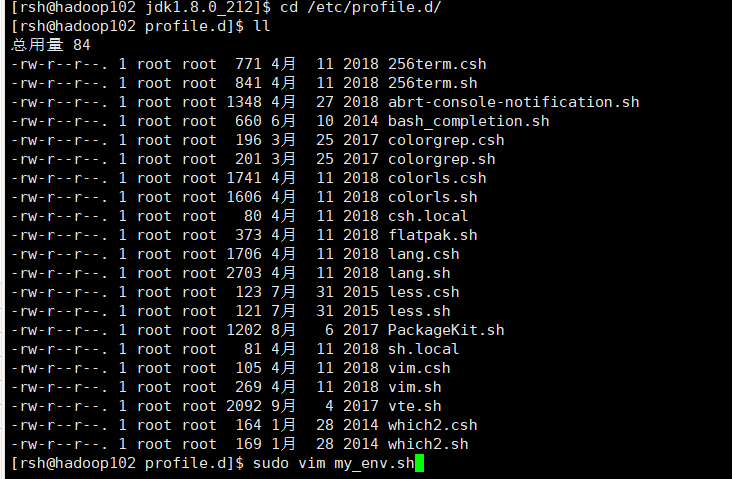
创建my_env.sh配置文件。定义环境变量
sudo vim my_env.sh
#JAVA_HOME=......
export JAVA_HOME=......
PATH=$PATH:$JAVA_HOME/bin
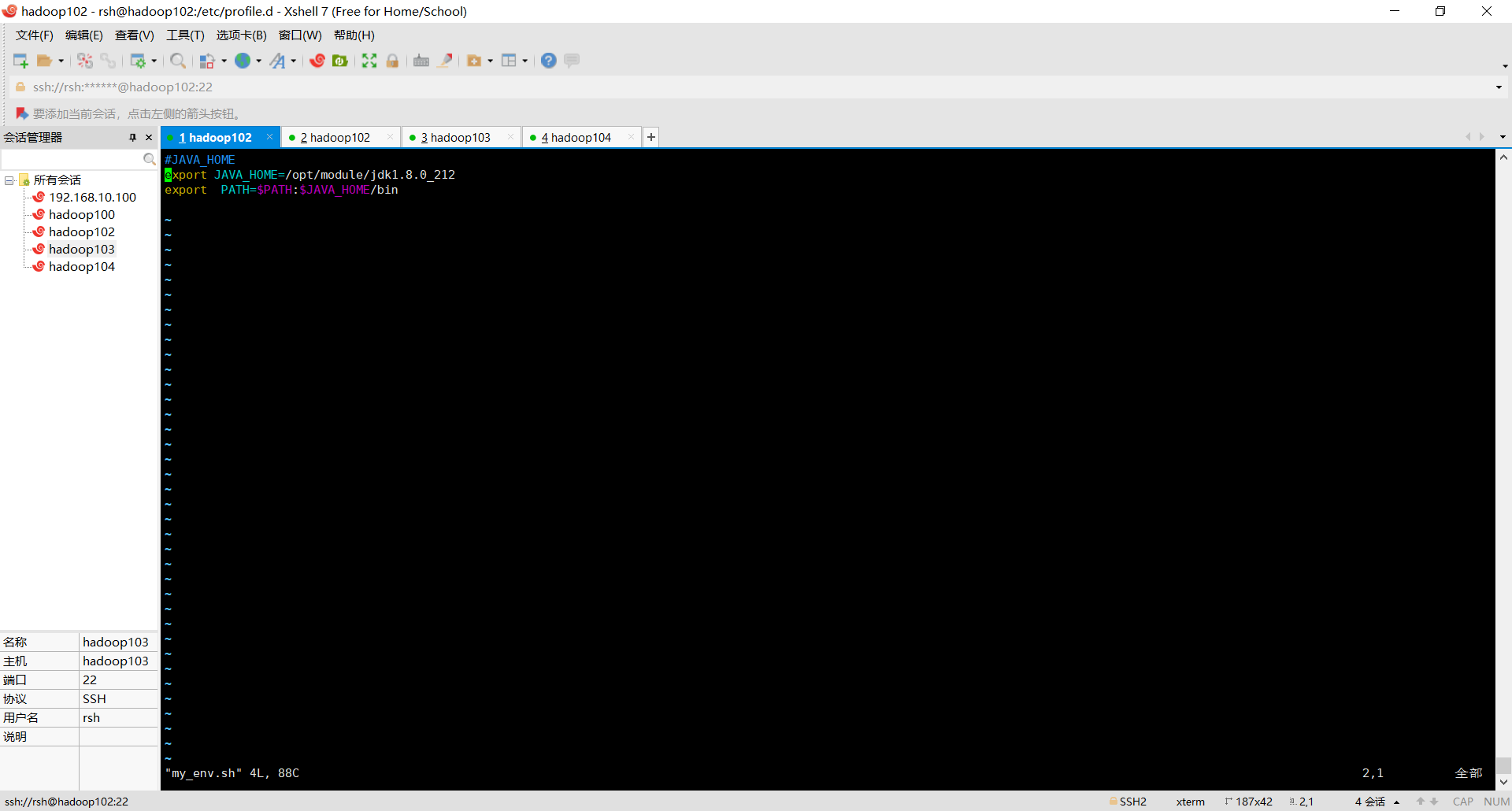
source /etc/profile
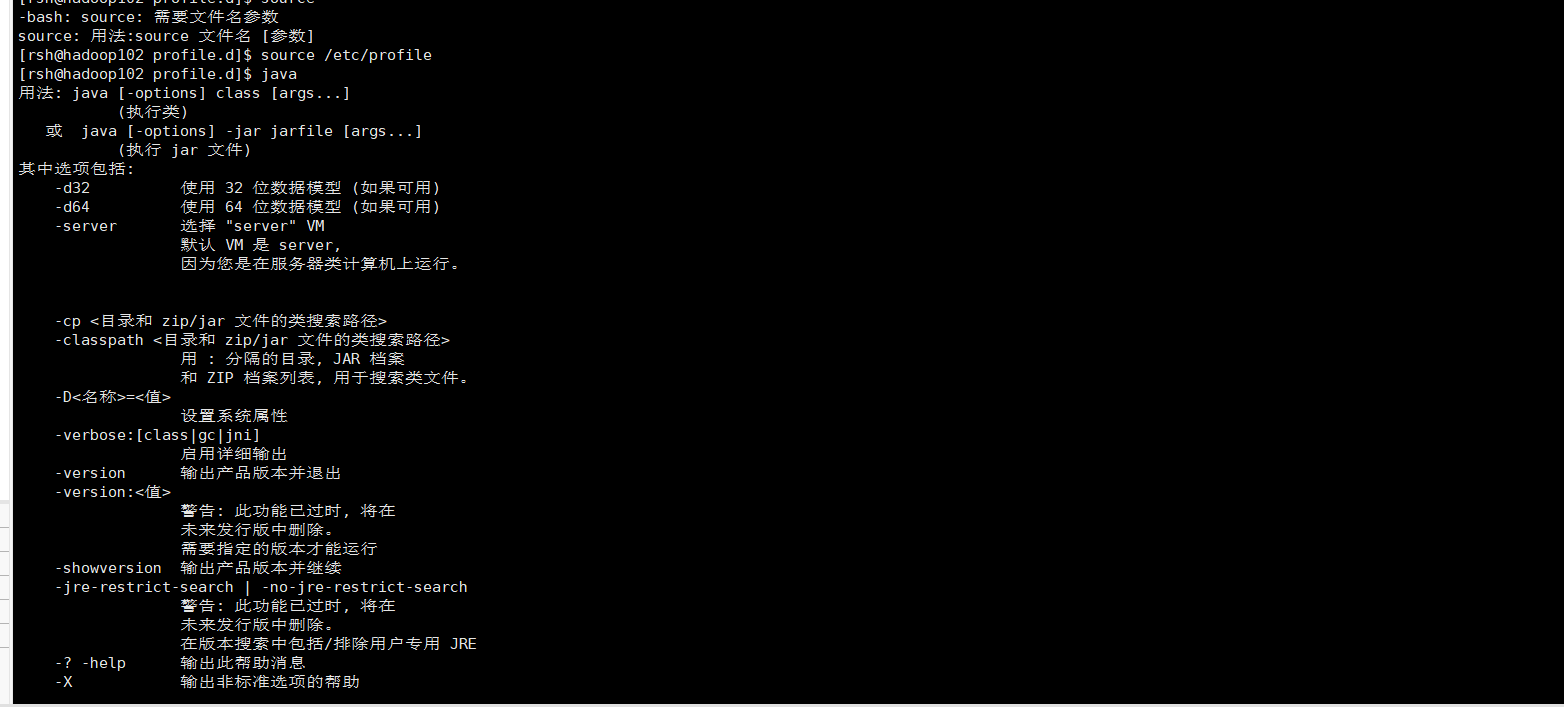
输入java验证环境变量是否配置成功
安装hadoop并配置环境变量
cd /opt/software/
tar -zxvf hadoop.... -C /opt/module/
cd /opt/module/hadoop../
sudo /etc/profile.d/my_env.sh
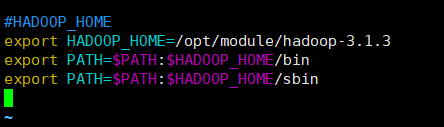
#HADOOP_HOME
export HADOOP_HOME=....
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
创建xsync脚本分发环境变量。
sudo ./bin/xsync /etc/profile.d/my_en.sh
最新文章
- Oracle 11G在用EXP 导出时,空表不能导出解决
- 细数改善WPF应用程序性能的10大方法
- Swift 中的函数(下)
- linux运维工程师
- 通过布赛尔曲线以及CAShapeLayer的strokeStart 、strokeEnd 属性来实现一个圆形进度条
- BZOJ 2763
- 【hibernate】spring+ jpa + hibername 配置过程遇到的问题
- jersey + tomcat 实现restful风格
- 【转】Angularjs Controller 间通信机制
- 开始学习<p>标签,添加段落
- [C#参考]事件和委托的关系
- 工作流管理系统 jBPM
- java与c/c++进行socket通信
- Python基础篇(九)
- 求求你别用SimpleDateFormat了!
- 多态练习题(通过UML建模语言来实现饲养员喂养动物)
- linux条件判断:eq、ne、gt、lt、ge、le
- group by分组后获得每组中符合条件的那条记录
- springboot整合redis(简单整理)
- Spark内存管理机制