scrapy五大核心组件
2024-10-21 03:53:17
scrapy五大核心组件
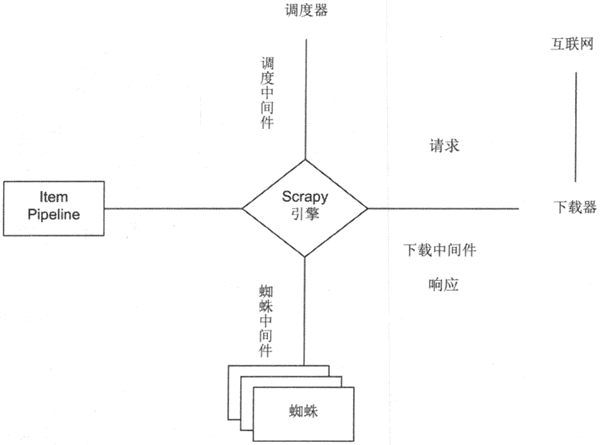
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
最新文章
- 网站中使用echart
- Winform的"透明"
- Object[]arr代码输出奇怪字符的解释
- [转载]字符编码笔记:ASCII,Unicode和UTF-8
- Android调试优化篇
- js原生之scrollTop、offsetHeight和offsetTop等属性用法详解
- 【渗透测试】PHPCMS9.6.0 任意文件上传漏洞+修复方案
- Chef 自动化运维:开始“烹饪”
- JMeter调试参数是否取值正确,调试正则提取的结果(log.info|log.error|print)
- Windows下安装MySQL5.7.18的方法
- PAT基础6-10
- 一个关于margin-top的问题
- 子序列的按位或 Bitwise ORs of Subarrays
- svn导出文件进行比较
- 触发Full GC执行的情况 以及其它补充信息
- Python开发【模块】:M2Crypto RSA加密、解密
- DataGridView绑定list的注意事项
- Selenium WebDriver(Python)API
- java数组复制的简单方法(一)
- Sqlserver风格规范