生产调优3 HDFS-多目录配置
HDFS-多目录配置
NameNode多目录配置
NameNode的本地目录可以配置多个,且每个目录存放内容相同,增加了可靠性

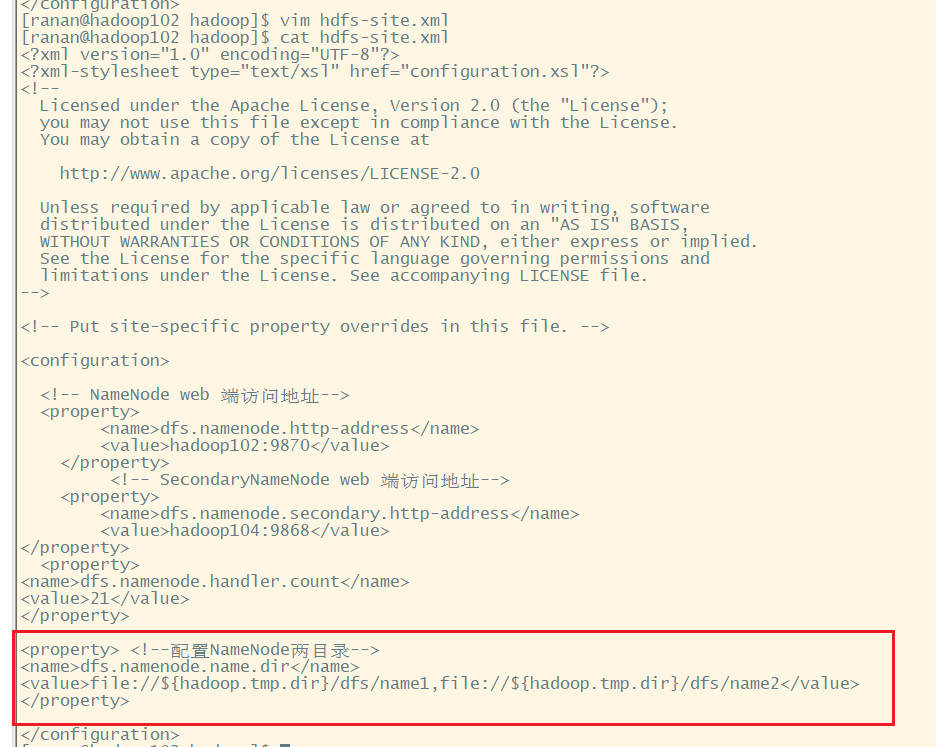
1.修改hdfs-site.xml
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name1,file://${hadoop.tmp.dir}/dfs/name2</value>
</property>
注意: 因为每台服务器节点的磁盘情况不同, 所以这个配置配完之后,可以选择不分发
hadoop.tmp.dir的配置文件在 /opt/module/hadoop-3.1.3/etc/hadoop下的core-default.xml(核心配置文件)
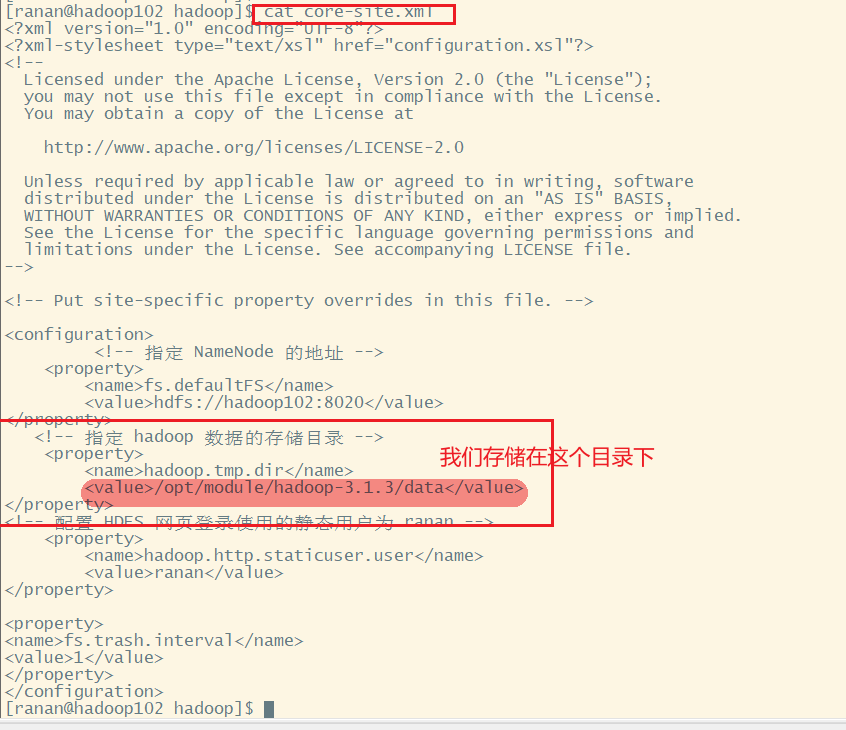
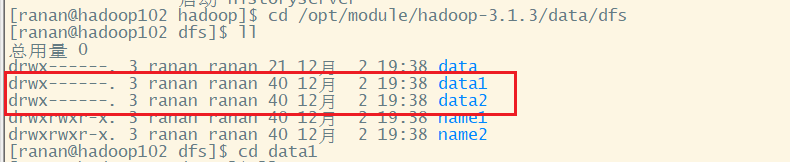
去/opt/module/hadoop-3.1.3/data/dfs目录查看修改前的目录结构
修改 /opt/module/hadoop-3.1.3/etc/hadoop下的hdfs-site.xml文件
2.格式化NameNode
格式化NameNode步骤
1.停止集群
2.删除data和logs中的所有数据
3.格式化集群并启动
停止集群,删除三台节点的data和logs中所有数据
[ranan@hadoop102 hadoop-3.1.3]$ myhadoop.sh stop
[ranan@hadoop102 hadoop-3.1.3]$ rm -rf data/ logs/
[ranan@hadoop103 hadoop-3.1.3]$ rm -rf data/ logs/
[ranan@hadoop104 hadoop-3.1.3]$ rm -rf data/ logs/
格式化集群步并启动,这里只启动HDFS
[ranan@hadoop102 hadoop-3.1.3]$ hdfs namenode -format
[ranan@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
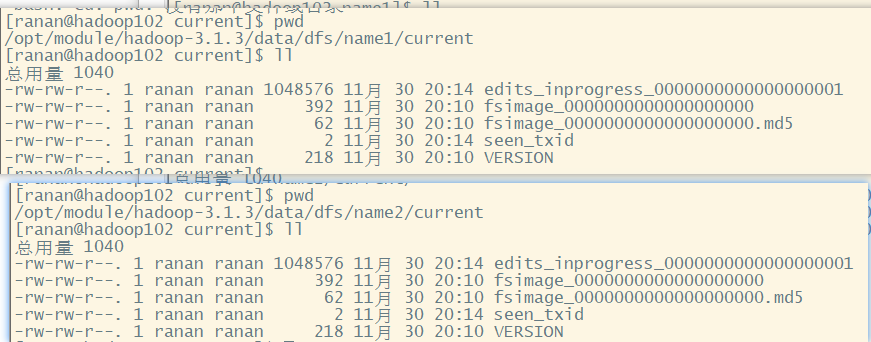
去/opt/module/hadoop-3.1.3/data/dfs目录查看修改后的目录结构

两个NameNode目录存放内容相同,只是提高了可靠性,并没有真正提高高可用性,了解即可
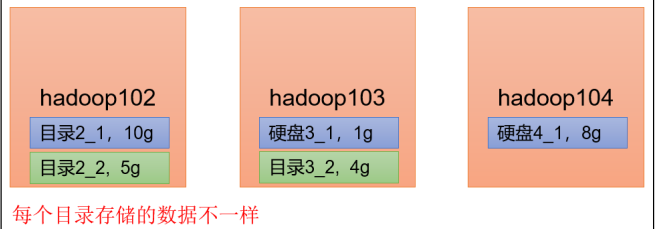
DataNode多目录配置(重要)
DataNode可以配置多个目录,每个目录存储的数据不一样(不是副本)
随着Data越来越多,可以增加硬盘空间来存储更多的数据
1.修改hdfs-site.xml
去/opt/module/hadoop-3.1.3/data/dfs目录查看修改前的目录结构

修改 /opt/module/hadoop-3.1.3/etc/hadoop下的hdfs-site.xml文件
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data1,file://${hadoop.tmp.dir}/dfs/data2</value>
</property>
重启集群,去/opt/module/hadoop-3.1.3/data/dfs目录查看修改前的目录结构
[ranan@hadoop102 hadoop]$ myhadoop.sh stop
[ranan@hadoop102 hadoop]$ myhadoop.sh start
[ranan@hadoop102 hadoop]$ cd /opt/module/hadoop-3.1.3/data/dfs
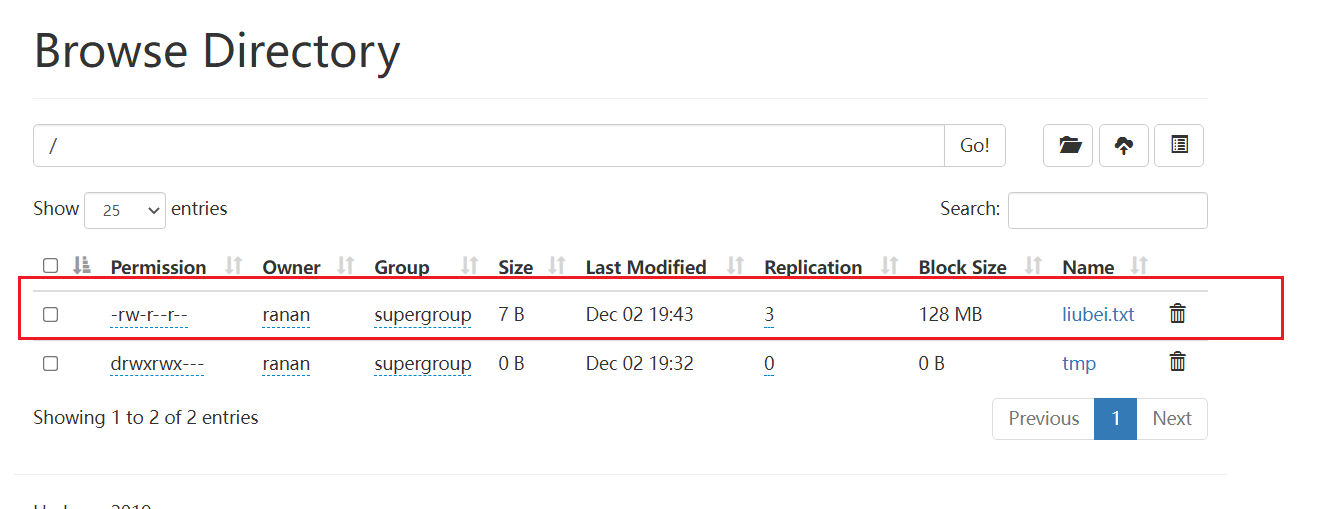
2.测试两个DataNode数据不一致
向集群上传一个文件,再次观察两个文件夹里面的内容一个有一个没有
[ranan@hadoop102 hadoop-3.1.3]$ hadoop fs -put liubei.txt /
data2数据为空
[ranan@hadoop102 finalized]$ ll
总用量 0
[ranan@hadoop102 finalized]$ pwd
/opt/module/hadoop-3.1.3/data/dfs/data2/current/BP-233650876-192.168.10.102-1638274259376/current/finalized
data1有数据
[ranan@hadoop102 finalized]$ cd /opt/module/hadoop-3.1.3/data/dfs/data1/current/BP-233650876-192.168.10.102-1638274259376/current/finalized/subdir0/subdir0/
[ranan@hadoop102 subdir0]$ ll
总用量 8
-rw-rw-r--. 1 ranan ranan 7 12月 2 19:43 blk_1073741825
-rw-rw-r--. 1 ranan ranan 11 12月 2 19:43 blk_1073741825_1001.meta
单节点内磁盘间数据均衡(Hadoop3.x 新特性)
生产环境,由于硬盘空间不足,往往需要增加一块硬盘。刚加载的硬盘没有数据时,可
以执行磁盘数据均衡命令,让磁盘数据均匀。
针对单节点内部磁盘之间的均衡

1 生成均衡计划
如果只有一块磁盘,不会生成计划
注意:这里使用虚拟机模拟的,虚拟机装在了D盘只有一个磁盘,虽然之前给了两个路径但实际还是一块,这里没办法演示
不同的两块硬盘,有独立地址
hdfs diskbalancer -plan hadoop102
2 执行均衡计划
hadoop103.plan.json 是上一步生成的文件
hdfs diskbalancer -execute hadoop102.plan.json
3 查看当前均衡任务的执行情况
hdfs diskbalancer -query hadoop102
4 取消均衡任务
hdfs diskbalancer -cancel hadoop103.plan.json最新文章
- MySQL数据迁移到MSSQL-以小米数据库为例-测试828W最快可达到2分11秒
- 高并发下MySQL出现checking permissions
- filter应用案例三:解决全站编码问题
- mingw 环境编译 liburl故障一例
- HDU 1422 重温世界杯
- [转]JavaScript作用域安全构造函数
- Javascript设计模式之装饰者模式详解篇
- 火狐解决OCSP回应包含过期信息的问题
- 冯如杯day1
- 学习flex布局(弹性布局)
- linux SElinux防护 加密解密 gpg签名与认证
- 工程师的URL大全
- [Swift]LeetCode519. 随机翻转矩阵 | Random Flip Matrix
- SAS数据集
- zeromq学习笔记1——centos下安装 zeromq-4.1.2
- Ajax的简单介绍与使用
- 2017.11.6 - ant design table等组件的使用,以及 chrome 中 network 的使用
- BZOJ2612 : [Poi2003]Sums
- orcle查询记录的每天的第一条
- [Django学习]模板
热门文章
- 阿里P7面试官:请你简单说一下类加载机制的实现原理?
- Luogu P1850 [NOIp2016提高组]换教室 | 期望dp
- hdu 2199 Can you solve this equation?(二分法求多项式解)
- 黑客是如何利用DNS域传送漏洞进行渗透与攻击的?
- [啃书] 第3篇 - 结构体及其操作/浮点数&圆周率/复杂度/测试
- Handler处理器&&使用代理服务器urllib.request.ProxyHandler
- HMS Core Insights第八期直播预告--创新能力解读
- C代码
- [hdu6978]New Equipments II
- vue 3 学习笔记 (八)——provide 和 inject 用法及原理