TCTrack
TCTrack
TCTrack: Temporal Contexts for Aerial Tracking,空中追踪的时间上下文
贡献:
- 提出了一种时间自适应卷积TAdaCNN。
- 提出了一种相似图细化的编解码器AT-Trans。
网络结构
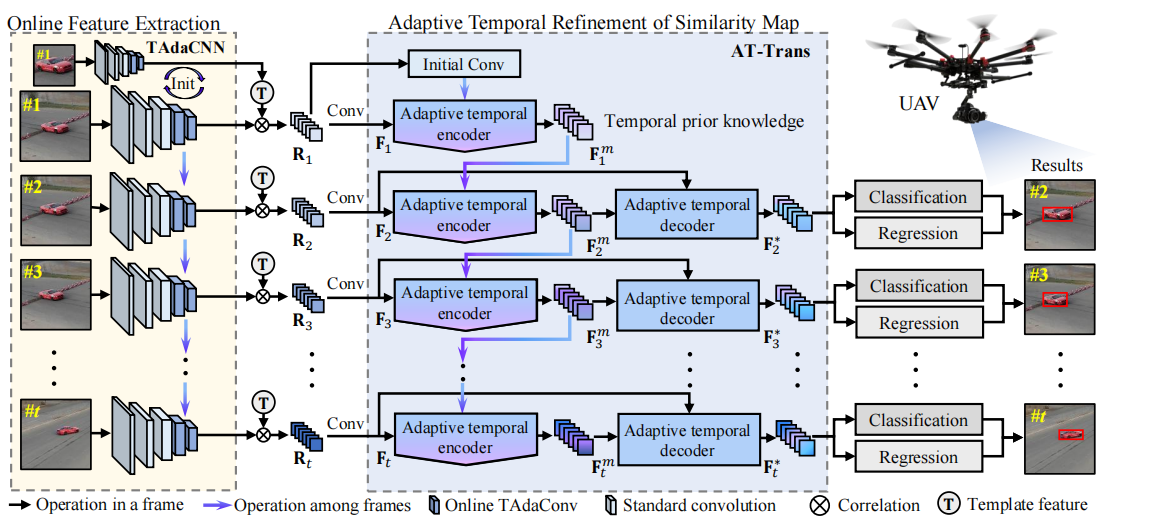
框架概述。主要由三个部分组成,如图所示的在线特征提取的TAdaCNN,图4所示的相似图细化的AT-Trans,最终预测的分类回归。此图说明了当跟踪序列为t帧时,我们的TCTrack的工作流程。通过相关性之前和之后的时间上下文,在我们的框架中引入了全面的时间知识。
原理公式
1 TAdaCNN时间自适应卷积
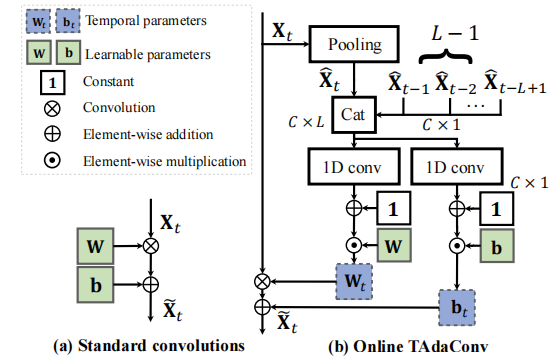
与普通卷积的区别:
- 普通卷积,只有权重和偏置
- 时间自适应卷积,在普通的权重和偏置之上(\(W_b,b_b\)),加入了**每一帧的校准因子( \(\alpha_t^{w},\alpha_t^{b}\) ) **,并有 \(W_t =W_b \times \alpha_t^w,b_t =b_b \times \alpha_t^b\)
只考虑过去时间上下文信息,典型的online目标追踪。
时间自适应卷积公式:
\]
其中,\(\tilde{X_t}\)为第\(t\)帧的输出,\(W_t,b_t\)为TadaCNN的时间权重和偏置项,\(X_t\)为TadaCNN的输入,\(t\)为一个图片序列的第\(t\)帧,\(*\)表示卷积操作。
时间上下文队列(temporal context queue):
\hat X \in R^{LC} \\
\hat X_t \in R^C
\]
其中,\(\hat X\)为时间上下文队列,\(Cat\)为拼接操作concatenation,$\hat X_t $ 称为帧描述符 frame descriptor,通过对每一个即将到来的帧进行全局平均池化得来的,即\(\hat X_t = GAP(X_t)\),表示第t帧的帧描述符。时间上下文队列就是L个帧描述符拼接而成的。
对于\(t <= L-1\)的情况,满足不了时间上下文队列\(\hat X\)的长度\(L\),此时,使用第一帧的时间描述符\(\hat X_1\)填充队列至满足长度\(L\)。即
\]
校准因子的计算:
\alpha_t^b = \digamma_b(\hat X) + 1 \\
\]
其中,\(\digamma_i\)表示卷积操作,其他符号与上文相同。\(\digamma_i\)的权值初始化为0,所以,在初始化时,\(\alpha_t^w = \alpha_t^b = 1\),进一步有\(W_t=W_b,b_t=b_b\).
相似度图:
\(R_t = \varphi_{data}(Z) \star \varphi_{data}(X_t)\)
其中,\(R_t\) 表示第 \(t\) 帧输出的相似图,\(Z\) 表示模板图片,\(\star\) 表示深度相关depthwise correlationSiamRPN++,\(\varphi_{data}\) 表示主干网络.
然后,通过一个卷积层,可以得到\(F_t = \digamma(R_t)\).
Remark1:据我们所知,我们的在线TAdaCNN是第一个在跟踪任务的特征提取过程中集成时间上下文的网络。
2 AT-Trans编解码器
使用AT-Trans进行相似性细化:
AT-Trans是一个编码器-解码器结构encoder-decoder structure,其中编码器的目的是集成时间知识,而解码器侧重于相似性细化。
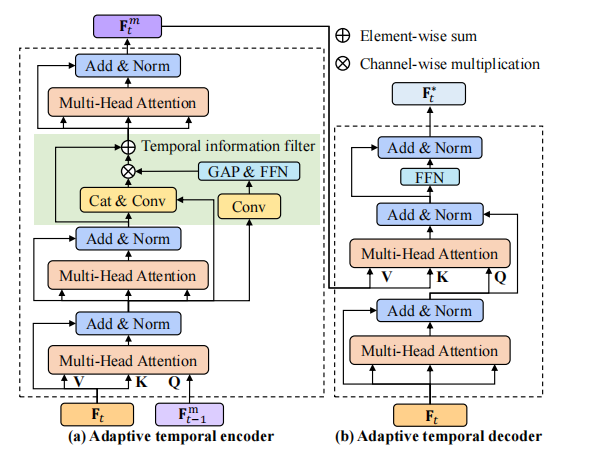
2.1 编码器
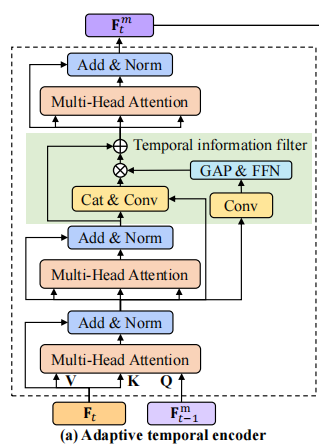
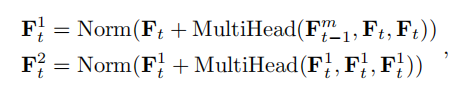
其中,\(F_t^1\)表示第一个多注意力层的输出,\(F_t^2\)表示第二个多注意力层的输出,\(F_{t-1}^m\)表示第\(t-1\)帧编码器的输出,\(Norm\)表示层标准化。
原文: Generally, we stack two multi-head attention layers before a temporal information fifilter is applied.
通常,在应用时间信息滤波器之前,我们会堆叠两个多层注意层。
文中说为了处理运动模糊或遮挡引起的上下文无用信息,加入了时间信息过滤器模块(Temporal information filter),如图中绿色方框所示,公式如下:
F_t^f = F_t^2 + \digamma(Cat(F_t^2, F_t^1)) * \alpha
\]
其中,\(\digamma\)表示一个卷积层,\(F_t^f\)表示过滤器的输出,
第t帧的时间先验信息\(F_t^m\)可以表示为:
\]
跟踪序列中第一帧\(F_0^m\)的初始化:
因为不同目标的特征是不同的,所以使用统一的初始化是不合理的。
因为\(F_0^m\) 表示的是第1帧的前一帧,即第0帧的时间先验知识,而时间先验知识本质上是相似图经过编码器形成的,相似图本质上有效的表示了目标对象的语义特征。所以,通过对初始相似图映射\(F_0\)的卷积来设置时间先验,即\(F_m^0=\digamma(R_1)\).
编码器的作用:
使得在整个跟踪过程中,使用的时间先验知识是固定的,只保存上一帧的时间先验知识即可。与需要保存所有中间时间信息的方法相比,TCTrack的记忆更加有效。AT-Trans以一种记忆高效的方式自适应地编码时间先验。
多头注意力机制Multi-head attention:
Transformer的基础组件
H_{att}^{n} = Attention(QW_{q}^{n},KW_{k}^{n},VW_{v}^{n}) \\
Attention(Q,K,V) = Softmax(\frac{QK^{T}}{\sqrt{d}})V
\]
其中,\(\sqrt{d}\) 为比例因子,
\(W \in R^{C_{i} \times C_i},W_q^n \in R^{C_i \times C_h}, W_k^n \in R^{C_i \times C_h},W_v^n \in R^{C_i \times C_h}\) 为可学习的权重.
在本文中的AT-trans中,有6个heads,即\(N=6\)且\(C_h = \frac{C_i}{6}\).
2.2 解码器
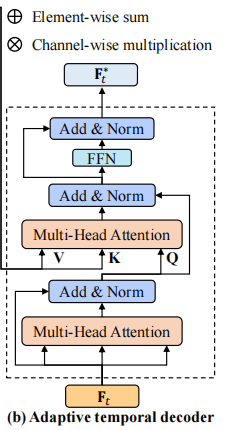
解码器的目的是细化相似度映射,更好的建立相似度图\(F_t\)与时间知识\(F_{t}^m\)之间的关系。
解码器表示如下:

其中,\(F_t^*\)表示解码器的输出,\(F_t\)表示相似度图,即第一阶段的输出,\(F_t^3,F_t^4\)分别表示第三个和第四个多注意力层的输出,\(FFN()\)表示前馈网络。
基于AT-Trans的编码器-解码器结构,可以有效地利用时间上下文来细化相似度图,以提高鲁棒性和准确性。
实验
详细的论述,看论文。
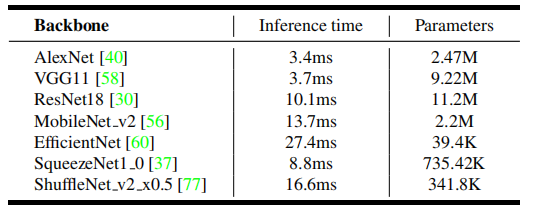
在NVIDIA Jetson AGX Xavier上的推理时间和参数的比较。在这里,我们使用287×287×3作为输入图像,并且只评估CNN的推理时间。
用AlexNet作为主干网络,因为空中追踪对速度要求高。
初始化:
对于初始化,我们为AlaxNet使用ImageNet预训练模型,并使用与[55 Imagenet Large Scale Visual Recognition Challenge.]中相同的在线TAdaConv的初始化。我们的TCTrack中的AT-Trans是随机初始化的。
实验细节
- 数据集:VID、Lasot、GOT-10k的视频训练,长度为4,即\(L=4\)
- 硬件设备:两个NVIDIA TITAN RTX gpu
- epoch:100
- 在前10个epoch中,主干的参数被冻结,遵循[41]
- 其余部分,学习率采用从log空间0.005下降到0.0005
- 优化器:SGD,动量0.9,mini-batch size124对
- 输入大小:模板\(127^2\),搜索\(287^2\)
- 提出的TAdaConv被用于替换AlexNet的最后两个卷积层
结果
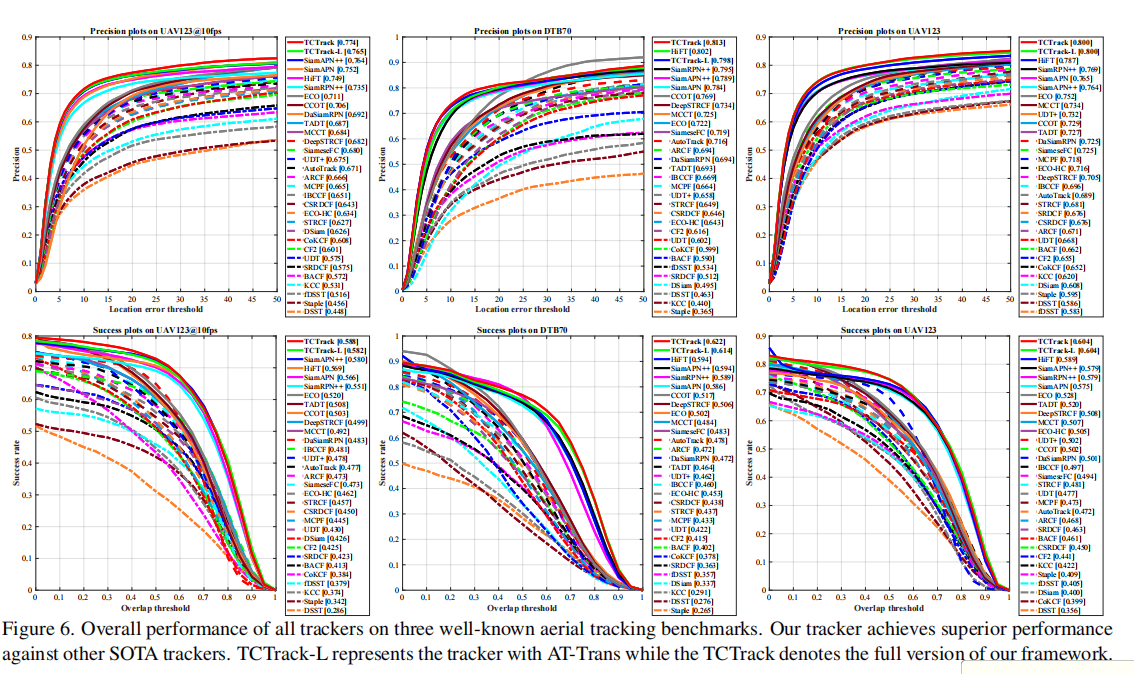
消融实验
在无时间信息滤波器情况下,分析了由不同的模型、训练方法、初始化和查询选择所造成的影响。
AT-Trans分析
证明了时间过滤器的作用是有益的
证明了用第一帧的卷积比随机初始化效果好
不同查询的对比
TAda-Conv中L的取值
- L=3
代码
TODO 日后补充
分组卷积实现深度互相关 depthwise cross correlation
def xcorr_depthwise(self,x, kernel):
"""depthwise cross correlation
"""
batch = kernel.size(0)
channel = kernel.size(1)
x = x.view(1, batch*channel, x.size(2), x.size(3))
kernel = kernel.view(batch*channel, 1, kernel.size(2), kernel.size(3))
out = F.conv2d(x, kernel, groups=batch*channel) # 分组卷积,kernel是模板的,x是搜索帧的
out = out.view(batch, channel, out.size(2), out.size(3))
return out
model输出的是什么
损失函数的weight在model输出中有
标签是什么
损失函数是什么
参考
最新文章
- PHP 开发API接口签名验证
- java并发控制:lock
- codeforces Round #347 (Div. 2) C - International Olympiad
- 前端project师的修真秘籍(css、javascript和其他)
- OpenCV 4 Python高级配置—安装setuptools,matplotlib,six,dateutil,pyparsing 完整过程
- mysql8.0.15二进制安装
- eclipse 界面开发--windowbuilder
- requests https 错误
- Java基础_0205: 程序逻辑结构
- Pains and Sickness 学习笔记
- ha环境下重新格式化hdfs报错
- build.gradle 中compileSdkVersion,minSdkVersion,targetSdkVersion,buildToolsVersion的意思
- dubbo学习(zz)
- length() 用法
- BZOJ.2134.[国家集训队]单选错位(概率 递推)
- Android论坛
- Kafka高可用实现
- [ IOS ] 视图控制对象ViewController的生命周期
- python模块之cx_Oracle
- apache Apache winnt_accept: Asynchronous AcceptEx failed 错误的解决