scrapy框架抓取表情包/(python爬虫学习)
2024-09-12 02:24:29
抓取网址:https://www.doutula.com/photo/list/?page=1
1.创建爬虫项目:scrapy startproject biaoqingbaoSpider
2.创建爬虫文件:scrapy genspider biaoqingbao doutula.com
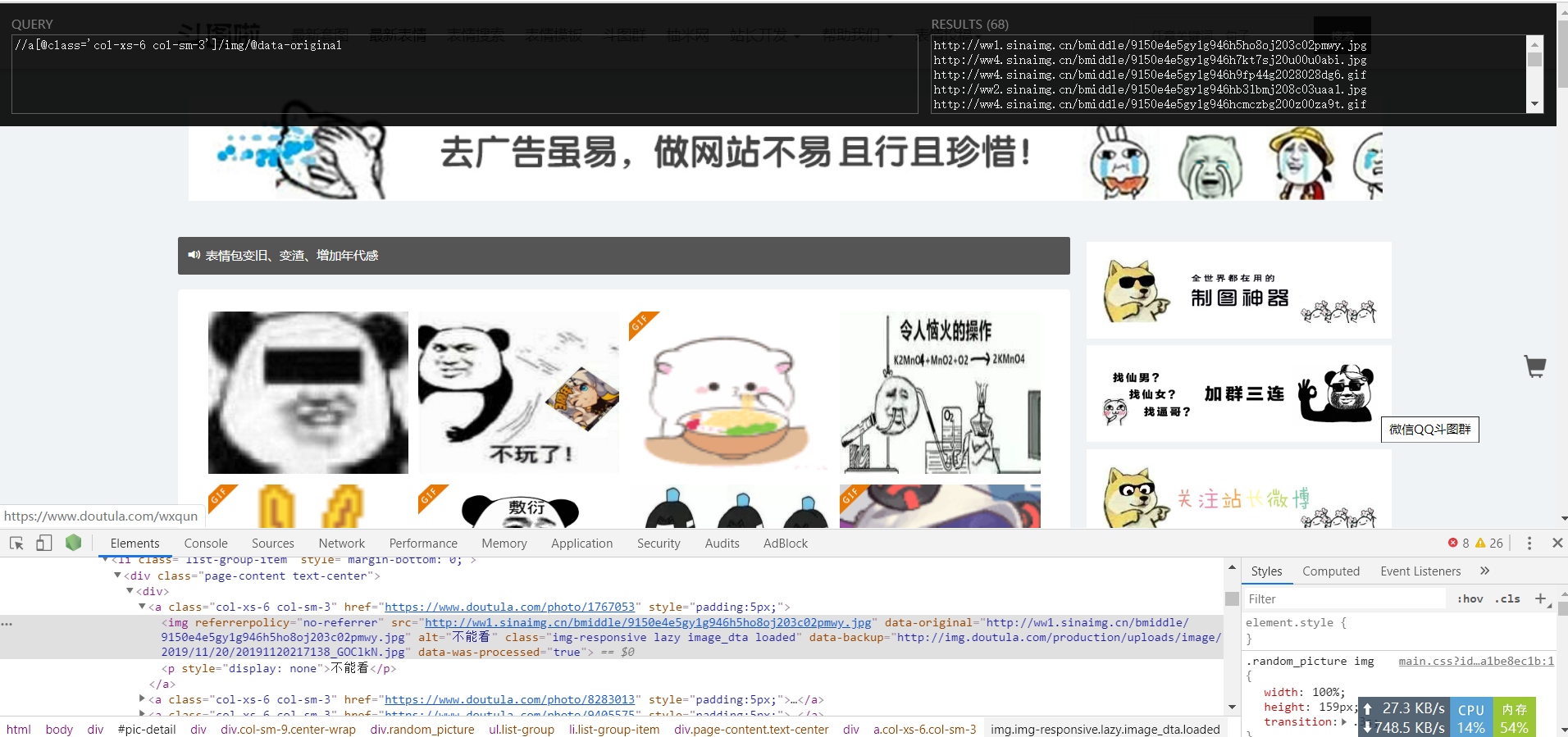
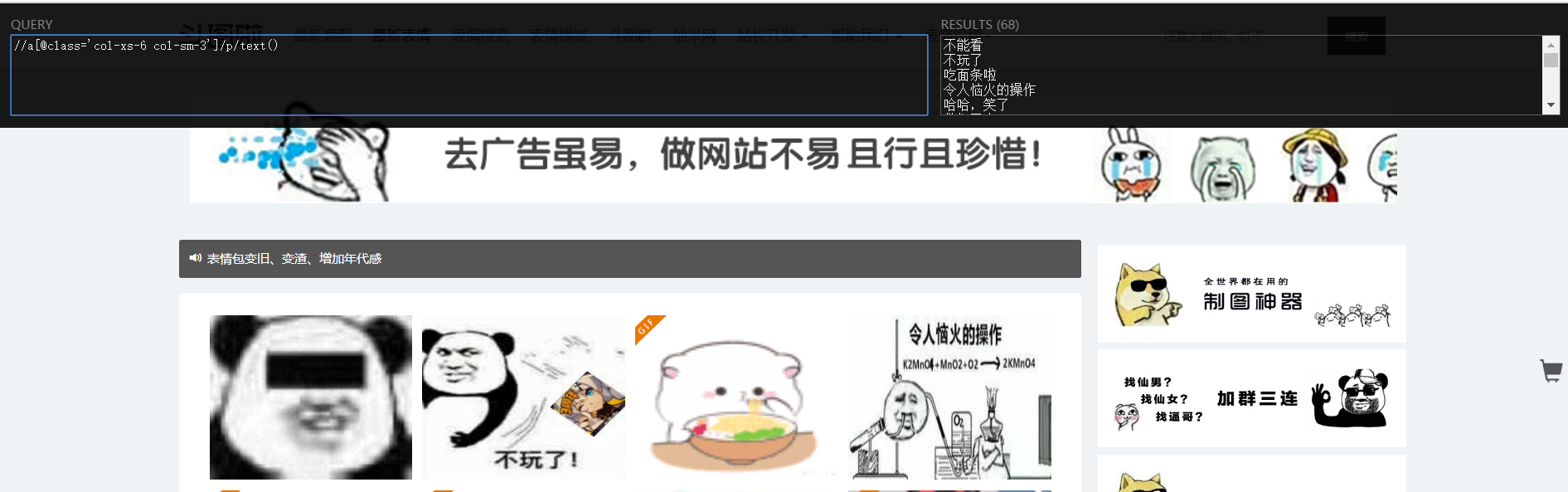
- xpath提取图片链接和名字:
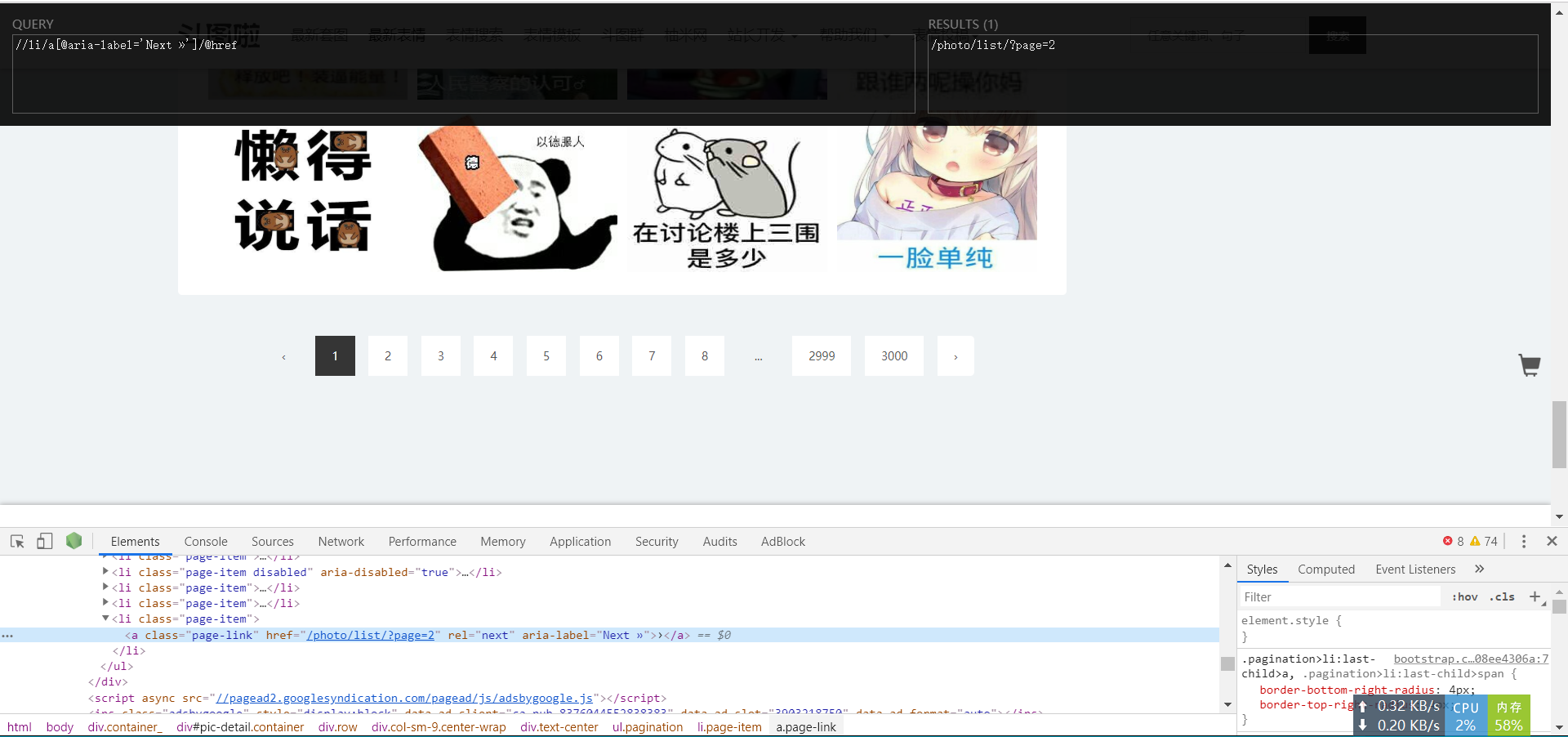
- 提取网址后缀,用于实现自动翻页
3.编写爬虫文件:
# -*- coding: utf-8 -*-
import scrapy
import requests class BiaoqingbaoSpider(scrapy.Spider):
name = 'biaoqingbao'
allowed_domains = ['doutula.com']
start_urls = ['http://www.doutula.com/photo/list/?page=1'] def parse(self, response):
#提取地址和图片名称
pictureUrls = response.xpath("//a[@class='col-xs-6 col-sm-3']/img/@data-original").extract()
pictureName = response.xpath("//a[@class='col-xs-6 col-sm-3']/p/text()").extract() #提取网址后缀,用于实现自动翻页
next_page = response.xpath("//li/a[@aria-label='Next »']/@href").extract_first() for i in range(len(pictureUrls)):
url = pictureUrls[i]
name = pictureName[i]
self.getPicture(url=url, name=name) #对每个图片调用getPicture下载图片并命名 #自动翻页
if next_page:
next_url = response.urljoin(next_page) #返回新的网址
yield scrapy.Request(next_url, callback=self.parse) #回调函数 #自定义函数,用于下载图片,因为刚学太菜,就只有先用requests下载了
def getPicture(self, url, name):
response = requests.get(url)
suffix = url.split(".")[-1] #提取图片链接地址的后缀,因为有jpg和gif图片格式
#二进制格式写入图片
with open("biaoqingbaoSpider/spiders/images/"+name+ "." + suffix, "wb") as fp:
fp.write(response.content)
4.执行爬虫文件:scrapy crawl biaoqingbao
- 切记:觉得爬差不多ctrl + c中止,不中止它会自动爬取到最后一页(3000页),当然也可以自己在代码里设置爬取多少页
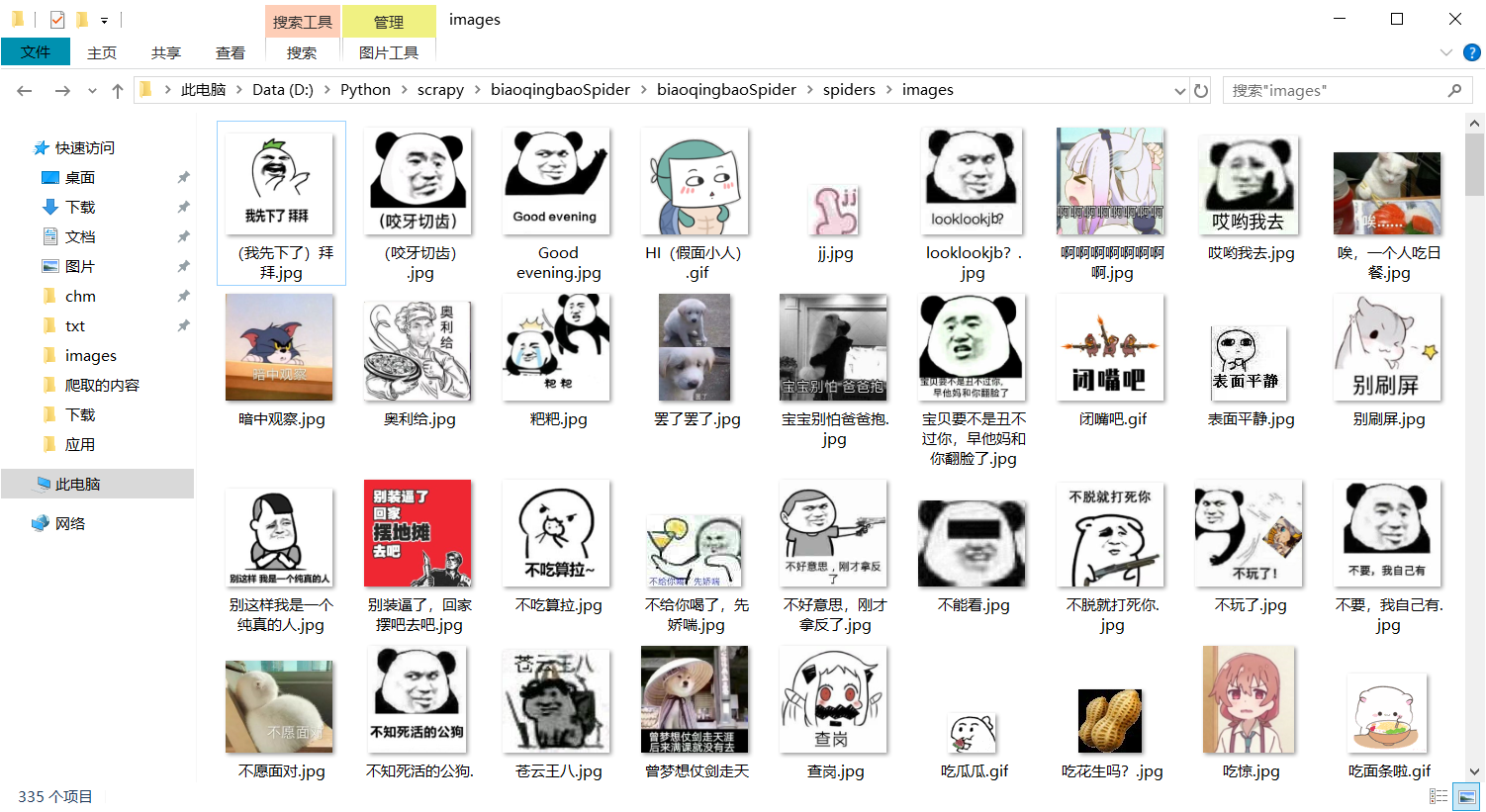
5.结果:
最新文章
- iOS-使用Xcode拉伸图片
- SQL事务回滚样例
- php PDO链接SQL SERVER
- [转载]Magento 店铺多语言设置
- OC错误
- 通过网络方式安装linux的五种方法
- shell find and rm
- 【Unity入门】场景编辑与场景漫游快捷键
- Spring对Hibernate事务管理【转】
- mkdir、whoami、touch
- 目前常用AD/DA芯片简介
- celery最佳实践
- [转载]expect spawn、linux expect 用法小记
- 洛谷 [P2701] 巨大的牛棚
- JSON Patch
- BZOJ_2956_模积和_数学
- my goal
- js运用6
- Ocelot中文文档-Not Supported
- Java集合-----Set详解