namenode磁盘满引发recover edits文件报错
前段时间公司hadoop集群宕机,发现是namenode磁盘满了, 清理出部分空间后,重启集群时,重启失败。
又发现集群Secondary namenode 服务也恰恰坏掉,导致所有的操作log持续写入edits.new 文件,等集群宕机的时候文件大小已经达到了丧心病狂的70G+..重启集群报错 加载edits文件失败。分析加载文件报错原因是磁盘不足导致最后写入的log只写入一半就宕机了。由于log不完整,hadoop再次启动加载edits文件时读取文件报错。由于edits.new 文件过大,存储了好多操作log,所以必须要对其进行修复。
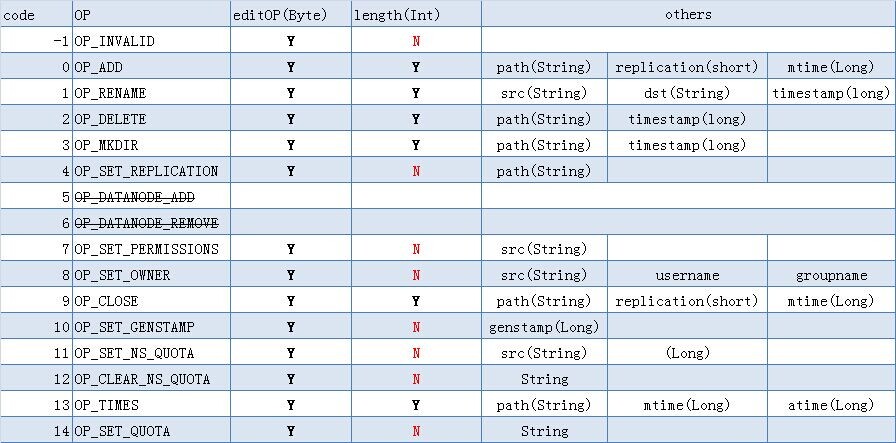
尝试删除文件的最后几行,结果还是报错。于是查看源码对edits 文件结构进行分析发现是二进制格式,首行为版本号,然后是hadoop运行过程中的log记录内容,由操作码 +长度(非必须)+其他项组成。
edits文件格式分析图
解决办法
报错位置在源码中的方法为org.apache.hadoop.hdfs.server.namenode.FSEditLog.loadFSEdits(EditLogInputStream edits)方法中读取文件最后位置时因为缺少部分数据报错, 所以把这部分代码单独拿出来,去掉业务操作部分,只留读取过程,记录异常之前的文件长度len,然后将0到len 这部分的内容复制出来成新的edits文件。启动hadoop集群,成功!
NameNode启动加载元数据流程
NameNode函数里调用FSNamesystemm读取dfs.namenode.name.dir和dfs.namenode.edits.dir构建FSDirectory。
FSImage类recoverTransitionRead和saveNameSpace分别实现了元数据的检查、加载、内存合并和元数据的持久化存储。
saveNameSpace将元数据写入到磁盘,具体操作步骤:首先将current目录重命名为lastcheckpoint.tmp;然后在创建新的current目录,并保存文件;最后将lastcheckpoint.tmp重命名为privios.checkpoint.
checkPoint的过程:Secondary NameNode会通知nameNode产生一个edit log文件edits.new,之后所有的日志操作写入到edits.new文件中。接下来Secondary NameNode会从namenode下载fsimage和edits文件,进行合并产生新的fsimage.ckpt;然后Secondary会将fsimage.ckpt文件上传到namenode。最后namenode会重命名fsimage.ckpt为fsimage,edtis.new为edits;
最新文章
- EntityFramework 7.0之初探【基于VS 2015】(十)
- 实现简单sed替换功能的python脚本
- height和line-height有什么区别?
- [zt]矩阵求导公式
- ORACLE查看并修改最大连接数
- Selenium Grid Configuration
- Leetcode#97 Interleaving String
- Protected Functions 是理解OO的难点和关键
- CMD命令窗口复制与粘贴
- [原创].NET 分布式架构开发实战之三 数据访问深入一点的思考
- java-JProfiler(一)-安装以及简介
- 最简单的基于FFmpeg的libswscale的示例附件:测试图片生成工具
- 将本地时间转换成 UTC 时间,0时区时间
- MySQL processlist中需要关注的状态
- .net core 获取不到session 和cookies的值
- CentOS 7 安装SVN并整合HTTP访问
- Mysql 利用拷贝data目录文件的方式迁移mysql数据库
- PS制作纸质复古野外露营插画分享
- 理解JVM之Java内存区域
- SQLite中的增删改查