seaweedfs安装配置使用
Saeweedfs是一个由golang语言开发的分布式对象存储系统,很适合做图片服务器,性能很好,安装操作都很简单,并且可兼容挂载提供路径访问的方式,可以较为便捷的将nginx+nfs此类的文件服务器转换成nginx+seweedfs并提供api接口并不影响原有访问url的模式
参考链接
https://github.com/chrislusf/seaweedfs/wiki/Getting-Started 官网
http://www.importnew.com/3292.html 论文
https://www.jianshu.com/p/2ff61b56f37b 安装
https://blog.csdn.net/u012618915/article/details/83415955 参数
https://www.jianshu.com/p/51d6d444303d 问题
首先我们下载weed
在https://github.com/chrislusf/seaweedfs/releases/我们可以看到已有版本及历史,写此文档时最新的长期支持版本为1.34,我们下载解压后可以看见一个可执行文件weed,因为是golang编译好的,我们可以直接使用它
[root@seaweedfs-bj-zw-vm1~]# wget https://github.com/chrislusf/seaweedfs/releases/download/1.34/linux_amd64.tar.gz
[root@seaweedfs-bj-zw-vm1~]# tar -zxf linux_amd64.tar.gz
[root@seaweedfs-bj-zw-vm1 ~]# ll
-rwxr-xr-x. root root 5月 : weed
[root@seaweedfs-bj-zw-vm1 ~]# ./weed -h # 查看帮助
master节点
master的作用仅仅是管理文件卷与服务器磁盘的映射,连文件的元数据也不管理,因此不需要额外的磁盘存储,性能上也是极好的
[root@seaweedfs-bj-zw-vm1 ~]# tail - master.out
I0604 :: node.go:] topo:zw:openstack-bj-zw-bgp6 adds child 172.16.100.138:
I0604 :: master_grpc_server.go:] added volume server 172.16.100.138:
I0604 :: master_grpc_server.go:] master see new volume from 172.16.100.136:
I0604 :: master_grpc_server.go:] master send to filer172.16.100.:: url:"172.16.100.136:8081" public_url:"172.16.100.136:8081" new_vids:
I0604 :: master_grpc_server.go:] master send to filer172.16.100.:: url:"172.16.100.136:8081" public_url:"172.16.100.136:8081" new_vids:
I0604 :: master_grpc_server.go:] master send to filer172.16.100.:: url:"172.16.100.136:8081" public_url:"172.16.100.136:8081" new_vids:
I0604 :: node.go:] topo:zw:openstack-bj-zw-bgp6 adds child 172.16.100.138:
I0604 :: master_grpc_server.go:] added volume server 172.16.100.138:
I0604 :: master_grpc_server.go:] master see new volume from 172.16.100.138:
I0604 :: master_grpc_server.go:] master send to filer172.16.100.:: url:"172.16.100.138:8081" public_url:"172.16.100.138:8081" new_vids:
I0604 :: master_grpc_server.go:] master see new volume from 172.16.100.138:
I0604 :: master_grpc_server.go:] master see new volume from 172.16.100.138:
I0604 :: master_grpc_server.go:] master see new volume from 172.16.100.138:
I0604 :: master_grpc_server.go:] master send to filer172.16.100.:: url:"172.16.100.138:8082" public_url:"172.16.100.138:8082" new_vids: new_vids: new_vids:
I0604 :: master_grpc_server.go:] master send to filer172.16.100.:: url:"172.16.100.138:8081" public_url:"172.16.100.138:8081" new_vids:
I0604 :: master_grpc_server.go:] master send to filer172.16.100.:: url:"172.16.100.138:8082" public_url:"172.16.100.138:8082" new_vids: new_vids: new_vids:
I0604 :: master_grpc_server.go:] master send to filer172.16.100.:: url:"172.16.100.138:8082" public_url:"172.16.100.138:8082" new_vids: new_vids: new_vids:
I0604 :: master_grpc_server.go:] master send to filer172.16.100.:: url:"172.16.100.138:8081" public_url:"172.16.100.138:8081" new_vids:
I0604 :: node.go:] topo:zw:openstack-bj-zw-bgp5 adds child 172.16.100.136:
这是我使用过产生的日志,在master的输出日志中我们可以直观看出master see new volume from 172.16.100.138:8082这类日志,这就是卷及其映射,代表22号卷在172.16.100.138的8082端口可访问
我们启动一个master,并设置一些参数,参数有很多都是默认的,可以不设置
# mdir 存储元数据的数据目录
# port 监听端口
# peers 主节点ip:端口
# defaultReplication 备份策略
# ip 服务器ip
# garbageThreshold 清空和回收空间的阈值
# maxCpu 最大cpu数量,0是所有
# pulseSeconds 心跳检测的时间间隔单位为秒
# ip.bind 绑定ip
# volumeSizeLimitMB volumes超载量,最大30G,即一个卷可以存多少数据,当然一个卷不代表一个磁盘,这点在下面的volume节点上再写
[root@seaweedfs-bj-zw-vm1 ~]# /root/weed master -mdir=/data/seaweedfs -port= -peers=172.16.100.107:,172.16.100.111:,172.16.100.106: -defaultReplication="" -ip="172.16.100.107" -garbageThreshold=0.3 -maxCpu= -pulseSeconds= -ip.bind=0.0.0.0 -volumeSizeLimitMB= >>/root/master.out &
[root@seaweedfs-bj-zw-vm1 ~]# tree /data/ # 这个目录里其实没啥东西
/data/
└── seaweedfs
├── conf
├── log
└── snapshot directories, files
[root@seaweedfs-bj-zw-vm1 ~]# netstat -tpln|grep
tcp6 ::: :::* LISTEN /weed
tcp6 ::: :::* LISTEN /weed
这样我们一个master节点就起来,当然如果你需要高可用的时候要将另外的master节点也起来,master节点是奇数,他们之间会选举leader,剩下的成为从节点以备不时之需,我们的参数-peers就是指定所有的master节点ip及port,如果是测试只是用单机那就不用加这个参数了
volume节点
volume很明显就是存储数据的真实节点了,它保留了文件的元数据及文件,通过卷的模式将磁盘分割,每个卷都有一个索引文件,每个元数据只有40字节,读取时间O(1),效率极高,速度极快
首先我们先将底层磁盘挂载上,我是2个1T的磁盘
[root@seaweedfs-bj-zw-vm5 ~]# mkdir -p /data/seaweedfs/volume{..}
[root@seaweedfs-bj-zw-vm5 ~]# mount /dev/vdb /data/seaweedfs/volume1
[root@seaweedfs-bj-zw-vm5 ~]# mount /dev/vdc /data/seaweedfs/volume2
[root@seaweedfs-bj-zw-vm5 ~]# df -h
文件系统 容量 已用 可用 已用% 挂载点
/dev/vda1 40G .3G 38G % /
devtmpfs .9G .9G % /dev
tmpfs .9G 12K .9G % /dev/shm
tmpfs .9G 17M .9G % /run
tmpfs .9G .9G % /sys/fs/cgroup
tmpfs 379M 379M % /run/user/
/dev/vdb .0T 369G 656G % /data/seaweedfs/volume1
/dev/vdc .0T 185G 840G % /data/seaweedfs/volume2
# dir 存储数据文件的目录,刚才的挂载点
# mserver master服务器列表
# port 监听端口
# ip 服务器ip
# max 本机volumes的最大值,在master上我们定义的每个卷为30G,可是我们的磁盘不可能就这么点,而max的作用就是表示这个磁盘上可以分多少个卷,默认是7,也就是30G * = 210G,很明显磁盘被浪费了很多空间,因此我们需要指定一个大max值,保证volumeSizeLimitMB * max >= 磁盘容量,当然你可以直接100,简单粗暴
# dataCenter 机房
# rack 机架
# idleTimeout 连接空闲时间秒数
# images.fix.orientation 上传时调整jpg方向
# ip.bind 监听ip
# maxCpu 最大cpu数量
# read.redirect 重新定向转移非本地volumes /root/weed volume -dir=/data/seaweedfs/volume1 -mserver=172.16.100.107:,172.16.100.111:,172.16.100.106: -ip="172.16.100.136" -max= -dataCenter=zw -rack=openstack-bj-zw-bgp5 -idleTimeout= -images.fix.orientation=true -ip.bind=0.0.0.0 -maxCpu= -port= -read.redirect=true >>/root/volume1.out &
/root/weed volume -dir=/data/seaweedfs/volume2 -mserver=172.16.100.107:,172.16.100.111:,172.16.100.106: -ip="172.16.100.136" -max= -dataCenter=zw -rack=openstack-bj-zw-bgp5 -idleTimeout= -images.fix.orientation=true -ip.bind=0.0.0.0 -maxCpu= -port= -read.redirect=true >>/root/volume2.out &
[root@seaweedfs-bj-zw-vm5 ~]# tail - volume1.out
I0605 :: store.go:] In dir /data/seaweedfs/volume1 adds volume: collection: replicaPlacement: ttl:
I0605 :: volume_loading.go:] loading index /data/seaweedfs/volume1/.idx to memory readonly false
I0605 :: store.go:] add volume
I0605 :: store.go:] In dir /data/seaweedfs/volume1 adds volume: collection: replicaPlacement: ttl:
I0605 :: volume_loading.go:] loading index /data/seaweedfs/volume1/.idx to memory readonly false
I0605 :: store.go:] add volume
I0605 :: store.go:] In dir /data/seaweedfs/volume1 adds volume: collection: replicaPlacement: ttl:
I0605 :: volume_loading.go:] loading index /data/seaweedfs/volume1/.idx to memory readonly false
I0605 :: store.go:] add volume
I0605 :: store.go:] In dir /data/seaweedfs/volume1 adds volume: collection: replicaPlacement: ttl:
I0605 :: volume_loading.go:] loading index /data/seaweedfs/volume1/.idx to memory readonly false
I0605 :: store.go:] add volume
I0606 :: store.go:] In dir /data/seaweedfs/volume1 adds volume: collection: replicaPlacement: ttl:
I0606 :: volume_loading.go:] loading index /data/seaweedfs/volume1/.idx to memory readonly false
I0606 :: store.go:] add volume
I0606 :: store.go:] In dir /data/seaweedfs/volume1 adds volume: collection: replicaPlacement: ttl:
I0606 :: volume_loading.go:] loading index /data/seaweedfs/volume1/.idx to memory readonly false
I0606 :: store.go:] add volume
I0606 :: store.go:] In dir /data/seaweedfs/volume1 adds volume: collection: replicaPlacement: ttl:
I0606 :: volume_loading.go:] loading index /data/seaweedfs/volume1/.idx to memory readonly false
I0606 :: store.go:] add volume
I0606 :: store.go:] In dir /data/seaweedfs/volume1 adds volume: collection: replicaPlacement: ttl:
I0606 :: volume_loading.go:] loading index /data/seaweedfs/volume1/.idx to memory readonly false
I0606 :: store.go:] add volume
I0606 :: store.go:] In dir /data/seaweedfs/volume1 adds volume: collection: replicaPlacement: ttl:
I0606 :: volume_loading.go:] loading index /data/seaweedfs/volume1/.idx to memory readonly false
I0606 :: store.go:] add volume
I0606 :: store.go:] In dir /data/seaweedfs/volume1 adds volume: collection: replicaPlacement: ttl:
I0606 :: volume_loading.go:] loading index /data/seaweedfs/volume1/.idx to memory readonly false
I0606 :: store.go:] add volume
[root@seaweedfs-bj-zw-vm5 ~]# du -sh /data/seaweedfs/volume1/*
30G /data/seaweedfs/volume1/23.dat
4.9M /data/seaweedfs/volume1/23.idx
30G /data/seaweedfs/volume1/29.dat
5.5M /data/seaweedfs/volume1/29.idx
30G /data/seaweedfs/volume1/33.dat
5.5M /data/seaweedfs/volume1/33.idx
30G /data/seaweedfs/volume1/34.dat
5.5M /data/seaweedfs/volume1/34.idx
30G /data/seaweedfs/volume1/35.dat
5.5M /data/seaweedfs/volume1/35.idx
30G /data/seaweedfs/volume1/36.dat
4.8M /data/seaweedfs/volume1/36.idx
30G /data/seaweedfs/volume1/41.dat
4.9M /data/seaweedfs/volume1/41.idx
30G /data/seaweedfs/volume1/42.dat
4.9M /data/seaweedfs/volume1/42.idx
30G /data/seaweedfs/volume1/43.dat
3.0M /data/seaweedfs/volume1/43.idx
30G /data/seaweedfs/volume1/50.dat
3.5M /data/seaweedfs/volume1/50.idx
30G /data/seaweedfs/volume1/51.dat
3.5M /data/seaweedfs/volume1/51.idx
30G /data/seaweedfs/volume1/53.dat
3.5M /data/seaweedfs/volume1/53.idx
8.1G /data/seaweedfs/volume1/58.dat
2.0M /data/seaweedfs/volume1/58.idx
7.9G /data/seaweedfs/volume1/62.dat
2.0M /data/seaweedfs/volume1/62.idx
我们可以看错,每个索引文件最大5M,数据文件30G,磁盘被分割成了很多的卷(idx+dat)
简单测试
现在的模式是master+ volume这种标准模式
[root@seaweedfs-bj-zw-vm5 ~]# curl http://172.16.100.107:9333/dir/assign
{"fid":"3,57f4e1898d66","url":"172.16.100.136:8082","publicUrl":"172.16. 100.136:8082","count":}
[root@seaweedfs-bj-zw-vm5 ~]# curl -F file=@/root/9ee6c1c5d88b0468af1a3280865a6b7a.png http://172.16.100.136:8082/3,57f4e1898d66
[root@seaweedfs-bj-zw-vm5 ~]# wget 172.16.100.136:/,57f4e1898d66
[root@seaweedfs-bj-zw-vm5 ~]# ls # 新下载下来的资源会被命名为fid
,57f4e1898d66
[root@seaweedfs-bj-zw-vm5 ~]# curl -X DELETE 172.16.100.136:/,57f4e1898d66
我们可以看出流程是,找master节点申请ip:port及fid,自己拼接ip:port/fid,然后post上传,此时该资源到服务器上了,我们可以对ip:port/fid进行get等请求
这里面有2点比较麻烦
. 要先申请,再拼接,再上传
. 要记录返回的ip:port/fid才能对该资源进行以后的操作,也就是3个信息
相对应的解决方式也是有的
. curl -F file=@/root/9ee6c1c5d88b0468af1a3280865a6b7a.png http://172.16.100.107:9333/submit这样会直接上传(申请fid+上传)
. wget 172.16.100.107:/,57f4e1898d66我们就直接访问master节点ip:port/fid,这样也是可以操作资源的,因为内部默认是开启了内部代理功能,我们只需要记录fid就可以了
现实问题
在大部分中小企业中,大家一开始使用的都是nginx+nfs提供静态资源访问的模式,也就是nginx管理root路径,而root路径是外部挂载的大磁盘,然后我们访问的时候就是url/资源路径模式。
它的优点在于
- 简单、简单、简单,重要的事情说三遍
- 成本低,不论是硬件成本还是管理成本
- 访问模式很直观,从url就可以看出文件路径
它的缺点主要还是来源于规模带来的一些问题
- 不是接口形式,所以项目需要直接操作磁盘,本身只支持get请求,其他请求需要代码来协助完成
- 权限问题,因为项目必须能操作磁盘,那么该目录的权限需要管理以及相关的安全问题
- 容量问题,随着时间的推移,我们的大磁盘需要扩容,可是每次扩容前我们需要备份(以防万一),而这个磁盘已经几个T了,备份时间过长
- 高可用问题,nfs的底层磁盘应该是某台机器组成的raid,那么这台机器挂了怎么办,当然有人说有备机,但是nfs挂载自动切换还有有点慢
- 所有需要落盘操作的机器都必须要挂载nfs,nfs的挂载连接数,磁盘io及网络开销随着挂载机器增多也在增大
- Nfs是文件存储,随着文件的增多,文件的索引层级也会越来越深影响速度
- 逼格不够,哈哈哈哈
解决方式
我们自然是使用本次的seaweedfs作为图片服务器了,这样就可以对应解决我们上述的问题
- 默认提供restful api,不需要代码层级再度实现
- 有了接口走的是http协议,只需要网络通就可以,不需要到处挂载文件系统了
- 容量不足了我们加机器、加磁盘进集群即可
- 本身实现了多种备份方式,可根据实际情况来选择
- 同2
- 本质还是对象存储,索引文件5M,操作速度极快
引出的问题
- 现有阶段的代码都是以url/文件路径,这种模式进行操作的,而seaweedfs是url/fid,改动量太大,不好实现
- 因为是restful api,所以大家都能直接delete,很危险…..
解决方式
- 使用filer功能
- 对内网提供不同的域名,对外域名在Nginx上只允许get请求
filer节点
filer节点是可以在任何地方执行的,它再次打开了一个http服务,并且也对外提供restful api,只是我们可以使用url/文件路径的模式进行访问了(之前的url/fid依然生效),filer节点提供的http服务可以如同一个文件系统一样被挂载,在挂载点,我们可以直观的看见目录层级(也是对象),及操作各个文件
[root@seaweedfs-bj-zw-vm1 ~]# /root/weed filer -master=172.16.100.111:,172.16.100.107:,172.16.100.106: -ip=172.16.100.107 -defaultReplicaPlacement='' -disableDirListing >>/root/filer.out &
[root@seaweedfs-bj-zw-vm1 ~]# /root/weed mount -filer=172.16.100.107: -dir=/mnt >>/dev/null &
[root@seaweedfs-bj-zw-vm1 ~]# netstat -tpln|grep
tcp 172.16.100.107: 0.0.0.0:* LISTEN /weed
tcp6 ::: :::* LISTEN /weed
[root@seaweedfs-bj-zw-vm1 ~]# df -h|grep mnt
SeaweedFS .3T .2T 48G % /mnt
访问的流程其实还是,以路径模式操作---根据路径获取fid---以fid模式操作----seaweedfs,也就是路径跟fid之间filer节点帮你做了一次转换
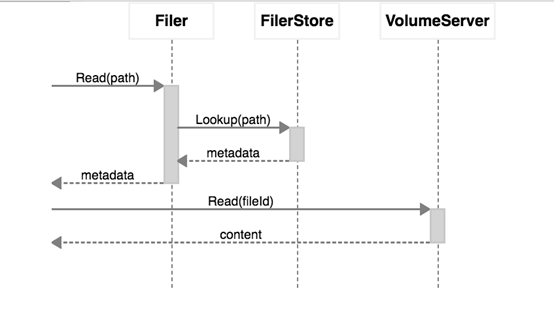
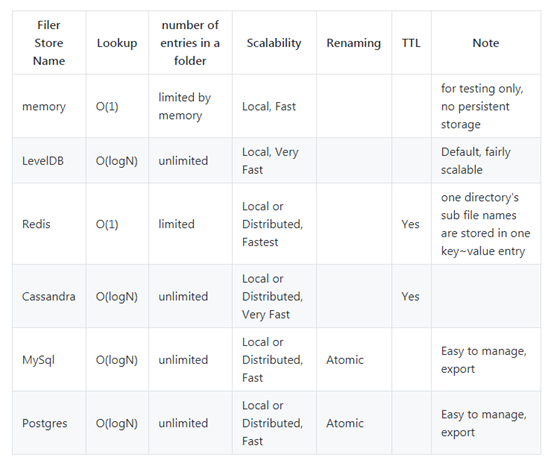
在默认情况下这种对应关系是存放在内存当中,实际情况下,我们需要安装一个记录关系的服务,以下是官方推荐的服务及其功能,我们果断使用了熟悉的redis,redis的记录也很简单,就是最简单的string的kv对应关系,key是路径,value是fid(转义过的),当然其他存储的关系大概也能想来,数据库类的自然就是有一个表(这个表的sql在配置文件里都有),然后就是两个记录的字段即可
[root@seaweedfs-bj-zw-vm1 ~]# mkdir -p /etc/seaweedfs
[root@seaweedfs-bj-zw-vm1 ~]# cd /etc/seaweedfs
[root@seaweedfs-bj-zw-vm1 seaweedfs]# /root/weed scaffold filer -output=" filer.toml "
[root@seaweedfs-bj-zw-vm1 ~]# vim /etc/seaweedfs/filer.toml # 把redis的信息填好,如果使用其他后端,将其enabled改成true并填写相关信息即可
[redis]
enabled = true
address = "xxx:6379"
password = ""
db =
我们重启filer服务后再次挂载,此时对应关系就会存在redis里了,个人已经放入1.T数据,大概1.5亿个key,在性能上完全没问题
后期我们不论是使用restful api,还是在mount的目录直接进行操作,还是在redis的库里直接操作,这三者操作都是一致的。例如我们在redis上删除了某个路径的key,那么这个文件就会直接消失,因此保存关系的后端也要维护好哦,当然,如果redis挂了,那么filer功能就会崩溃,只能直接使用url/fid的模式
因此,使用filer来兼容之前nfs,我们需要额外保证后端存储的可用性!
最新文章
- 昆仑游戏[JS加密修改]
- 有关于psExec的使用
- 题目一:一张纸的厚度大约是0.08mm,对折多少次之后能达到珠穆朗玛峰的高度(8848.13米)?
- java--实现将文字生成二维码图片,并在中间附上logo,下方附上文字
- Cocos2dx-lua开发之c++绑定到lua
- oracle ORA-00913: 值过多
- JS全选
- PHP常用的三种设计模式
- 芝麻HTTP:在无GUI的CentOS上使用Selenium+Chrome
- 【Bzoj 1835 基站选址】
- Java:配置环境(Mac)——MySQL
- Hi3519v101-uboot-start.S分析
- 纯CSS3冒泡动画按钮实现教程
- 【2017-03-21】HTML表单及标记
- 怎样从外网访问内网WebLogic?
- 【java】JDK、JRE、JVM的关系
- CentOS 7.2 下 PXE+kickstart 自动安装系统
- 机器学习(4): KNN 算法
- SVN回滚至某个版本
- sql替换数据库字段中的字符