ELK安装配置简单使用
ELK是三款软件的总称,包括了elasticsearch、logstash、kibana,其实在生产使用中,我们还需要使用到其他的更多辅助软件来更好更合理的收集展示数据。
Elasticsearch:一个分布式的搜索查询服务器,提供了rest接口
Logstash:收集处理并传出日志,他安装在需要被收集日志的服务器上(暂时)
Kibana:一个web展示操作页面,从Elasticsearch提供的接口获取数据并做一些常用操作
使用ELK解决的问题:
- 开发人员可以完全不登录服务器也可以拿到需要的日志了
- 各个系统、集群日志分散,不统一,需要一台台去专门查询
- 日志量过大,常规查询分析方法太慢
那么我们现在来规划下,三台节点,node1、node2、node3。其中node1、node2作为Elasticsearch的分布式集群节点,并且都安装Kibana来提供web页面,而node3则为我们需要收集日志的目标机器,他只需要安装Logstash即可
首先我们要先去获取安装包,我们三种软件全部都下载同一版本(5.6.5)的rpm包,下载网址https://www.elastic.co/downloads/past-releases,然后分别上传到对应服务器上
然后回到node1上
[root@linux-node1 ~]# yum install java elasticsearch-5.6..rpm kibana-5.6.-x86_64.rpm –y
[root@linux-node1 ~]# grep "^[a-Z]" /etc/elasticsearch/elasticsearch.yml
cluster.name: elk-cluster- # 集群名称,用来区分不同elk集群
node.name: node- # 集群内该节点名称,不可重复
path.data: /elk/data # 数据目录,即分散着被检索的日志
path.logs: /elk/logs # 日志目录
network.host: 192.168.56.11 # 自己的ip
http.port: # 对外访问端口。集群内部进行选举、通讯用的是9300端口
discovery.zen.ping.unicast.hosts: ["192.168.56.11", "192.168.56.12"] # 自动广播的目标,因为是广播,如果广播的机器过多,可能会影响到网络质量,所以规定好只向某些机器广播即可
[root@linux-node1]# mkdir /elk
[root@linux-node1]# systemctl start elasticsearch.service
[root@linux-node1]# ls /elk/ # 发现神马都木有
这是因为我们的elasticsearch默认的启动用户是elasticsearch,此时的/elk目录权限不够
[root@linux-node1]# chown elasticsearch:elasticsearch -R /elk
[root@linux-node1]# systemctl restart elasticsearch.service
[root@linux-node1 ~]# ls /elk/
data logs
[root@linux-node1 ~]# grep "^[a-Z]" /etc/kibana/kibana.yml
server.port: # 打开的端口,默认就是5601
server.host: "192.168.56.11" # 监听的ip地址,默认是localhost
elasticsearch.url: http://192.168.56.11:9200 # 从该elasticsearch的获取数据来展示
[root@linux-node1 ~]# systemctl start kibana.service
[root@linux-node1 ~]# ss –tln # 发现9200、、5601都有啦
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN *: *:*
LISTEN *: *:*
LISTEN *: *:*
LISTEN *: *:*
LISTEN *: *:*
LISTEN *: *:*
LISTEN 192.168.56.11: *:*
LISTEN ::: :::*
LISTEN ::ffff:192.168.56.11: :::*
LISTEN ::ffff:192.168.56.11: :::*
LISTEN ::: :::*
LISTEN ::ffff:127.0.0.1: :::*
此时node1上的操作就完成了,但是现在elasticsearch里并没有数据供我们检索查询,所以我们要去配置node3收集点日志,不过在此之前我们先去配置node2
[root@linux-node2 ~]# yum install java elasticsearch-5.6..rpm kibana-5.6.-x86_64.rpm -y
[root@linux-node2 ~]# grep "^[a-Z]" /etc/elasticsearch/elasticsearch.yml
cluster.name: elk-cluster- # 让他们处于统一elk集群里
node.name: node- # 这个要变
path.data: /elk/data
path.logs: /elk/logs
network.host: 192.168.56.12 # 这个要变
http.port:
discovery.zen.ping.unicast.hosts: ["192.168.56.11", "192.168.56.12"]
[root@linux-node2]# mkdir /elk
[root@linux-node1]# chown elasticsearch:elasticsearch -R /elk
[root@linux-node2]# systemctl start elasticsearch.service
[root@linux-node2 ~]# ls /elk/
data logs
[root@linux-node2 ~]# grep "^[a-Z]" /etc/kibana/kibana.yml
server.port: # 打开的端口,默认就是5601
server.host: "192.168.56.12" # 监听的ip地址,默认是localhost
elasticsearch.url: http://192.168.56.12:9200 # 从该elasticsearch的获取数据来展示
[root@linux-node2 ~]# systemctl start kibana.service
现在的情况很明显了,node1与node2组成了一个elasticsearch集群,我们向他们两个任意一个的9200端口传输获取数据都可以,而他们也都同时提供了kibana页面供我们访问,熟悉高可用负载均衡的朋友就可以一眼看出,我提供一个vip给kibana与elasticsearch做负载就可以保证生产时的环境了,没错就是酱,但是这点小事我们就不执行了,其实很简单啊,就几分钟的事情。
[root@linux-node3 ~]# yum install java logstash-5.6..rpm –y
[root@linux-node3 ~]# cd /etc/logstash/conf.d/ # 以后所有的配置规则都在这里哦
[root@linux-node3 conf.d]# cat systemlog.conf
input { # 数据来源定义,可定义多个
file { # 从文件中获取
path => "/var/log/messages" # 文件路径
start_position => "beginning" # 从文件开头获取还是从现在开始,默认从现在
type => "systemlog-5613" # 类别名自定义,最好具有良好的辨认性
stat_interval => "" # 获取时间间隔,默认1秒,太频繁了
}
} output { # 数据输出定义,可定义多个
elasticsearch { # 向elasticsearch输出
hosts => ["192.168.56.11:9200"] # elasticsearch的url
index => "system-log-5613-%{+YYYY.MM.dd}" # 自定义,最好具有良好的辨认性,最后的%{+YYYY.MM.dd}是取当前的时间戳
}
file { # 向文件输出
path => "/tmp/systemlog.txt" # 输出路径
}
}
[root@linux-node3 tmp]# chmod /var/log/messages # messages的权限特殊是600
[root@linux-node3 ~]# systemctl start logstash
[root@linux-node3 ~]# tail - /tmp/systemlog.txt
{"@version":"","host":"linux-node3.example.com","path":"/var/log/messages","@timestamp":"2017-12-15T10:30:02.990Z","message":"Dec 15 18:30:01 linux-node3 systemd: Starting Session 62 of user root.","type":"systemlog-5613"}
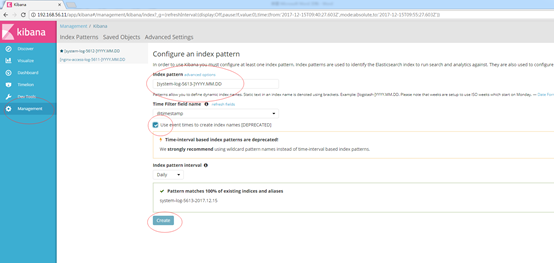
[system-log-5613-]YYYY.MM.DD,这个就是我们刚才的index,不同的是最后时间戳的表示是DD,然后我们勾选使用时间戳创建,确认到了匹配的数据索引后创建
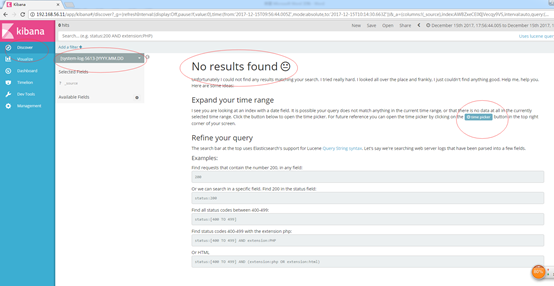
发现没有数据,wtf,劳资费了这么大劲就给我看这个? 我们点击蓝色按钮调整下查找的时间轴
我们点击蓝色按钮调整下查找的时间轴
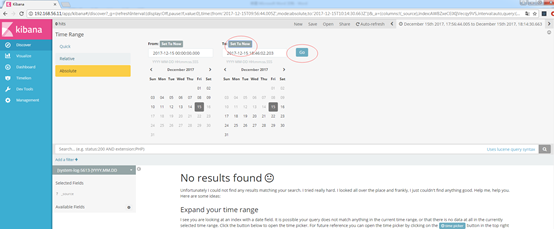
设置成起始时间今天,截至时间为当前再次查询
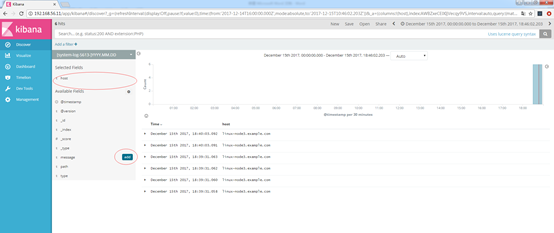
有点信心了,我们选择排列host跟message,这样就可以直观的对比数据了
最新文章
- 使用Unity Container
- [Head First设计模式]生活中学设计模式——组合模式
- 由反汇编C程序来理解计算机是如何工作的
- SQL[连载3]sql的一些高级用法
- (hdu)1257 最少拦截系统
- 引用JS表单验证大全 以后方便查看用
- 【LSGDOJ 1408】邮局
- Python 魔术方法笔记
- U-Boot Makefile分析(4)具体子Makefile的分析
- 一次完整的HTTP事务是怎样一个过程?(转)
- 要是VISUAL STUDIO 2015带这些功能就好了
- 今天设置apache二级域名ssl证书后出现问题
- 分布式事务实现-Percolator
- Linux od命令(以指定进制显示文件)
- Codeforces Round #441 (Div. 2, by Moscow Team Olympiad) F. High Cry(思维 统计)
- Android studio的调试方法
- Python20-Day01
- Android应用自动更新功能的代码实现(转)
- ? 初识Webx 3
- Python web前端 06 运算符 循环
热门文章
- 进程间通信(IPC)+进程加锁解锁
- Ubuntu 14.04下单节点Ceph安装(by quqi99)
- 【BZOJ1776】[Usaco2010 Hol]cowpol 奶牛政坛 树的直径
- 【百度之星复赛】T5 Valley Numer
- RTSP Windows专用播放器EasyPlayer : 稳定、兼容、高效、超低延时
- 流畅python学习笔记:第十六章:协程
- Pentaho BIServer Community Edtion 6.1 使用教程 第四篇 安装和使用Saiku 插件 进行 OLAP
- MySql索引建立规则
- 添加@ControllerAdvice后报错 Failed to invoke @ExceptionHandler method
- Javascript代码收集