Linux DRBD 主节点(Primary) 故障恢复测试
2024-10-16 12:34:06
测试当主节点发生故障后,如何切换到备节点,当主节点恢复后,又是如何恢复双机数据同步的?
环境
- DRBD
- linux
- VMware Workstation 9
步骤
- 1
模拟生产环境配置
1)环境
实验环境:两台linux CentOS 6.4 32bit 虚拟机
计算机名: n101 和 n102
IP地址:192.168.118.101(n101) 192.168.118.102 (n102)
2) DRBD配置(n101与n102配置一致)
# cat /etc/drbd.d/r1.re resource r1
{
startup {
wfc-timeout 30;
outdated-wfc-timeout 20;
degr-wfc-timeout 30;
}
net {
cram-hmac-alg sha1;
shared-secret sync_disk;
}
syncer {
rate 100M;
verify-alg sha1;
}
on n101 {
device /dev/drbd0;
disk /dev/sdb1;
address 192.168.118.101:7789;
meta-disk internal;
}
on n102 {
device /dev/drbd0;
disk /dev/sdb1;
address 192.168.118.102:7789;
meta-disk internal;
}
}
#end3) 当前DRBD状态
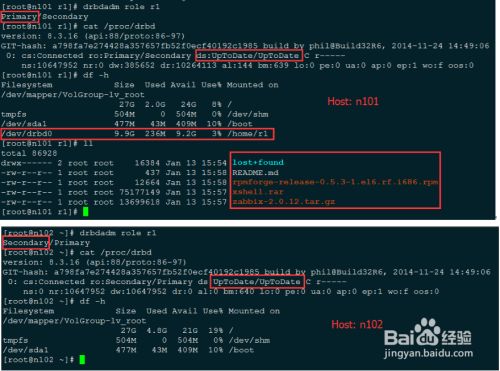
- 2
模拟n101系统损坏
需要重新安装linux操作系统,重新配置DRBD(这里我直接还原n101到刚安装好系统时的状态)
第一步:模拟n101系统损坏(这里重启系统并还原系统)
1)还原系统
- 3
2 ) 查看n102 drbd状态
PS:下图显示n101,即Primary已经不可识别

- 4
将n102设置为Primary,并挂载到/home/r1
如下图,n102的数据正常、完整
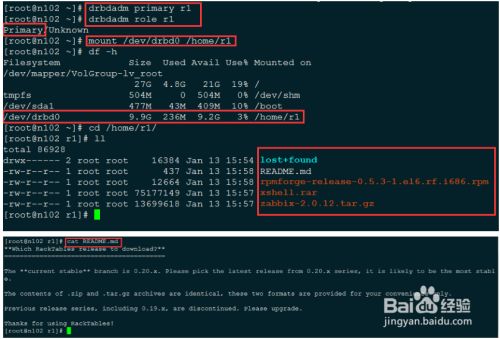
- 5
恢复n101,并配置drbd
1) 将n102的drbd相关配置拷贝至n101
2) 同步n102数据,直至同步完成
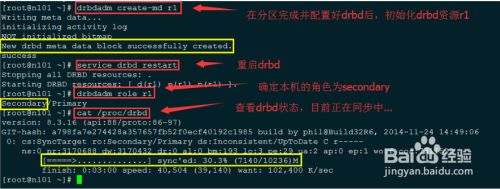
- 6
验证n101数据完整
1) 查看是否同步完成
如下图,数据同步已经完成

- 7
停止n102对/home/r1 进行写操作,并将n102设置为Secondary
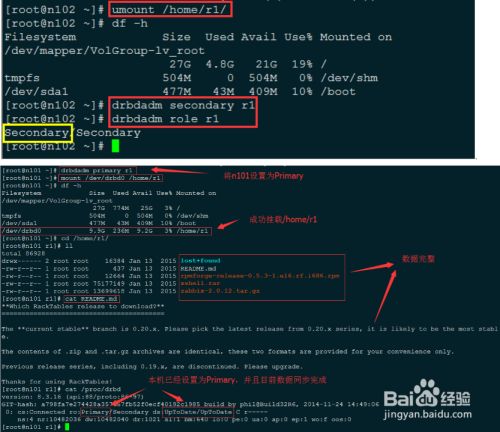 END
END
备注
- 当DRBD的Primary(n101)发生故障(系统损坏),变为不可用状态时,需要将Secondary主机设置为Primary,并挂载到相 应目录继续工作,原Secondary(n102)数据不会丢失。恢复n101时,只需要将n101重新配置DRBD 与n102相同的资源(如r1)并作 为n102的Secondary,将n102的数据同步过来即可完成恢复。
最新文章
- Open CV缩放图像
- ean13码的生成,python读取csv中数据并处理返回并写入到另一个csv文件中
- oracle 11g在安装过程中出现监听程序未启动或数据库服务未注册到该监听程序
- Round Numbers (排列组合)
- 在ASP.NET MVC4中配置Castle
- NYOJ--241--字母统计
- 手机浏览网页或打开App时莫名弹出支付宝领红包界面的原因及应对措施
- 【转载】解决nginx负载均衡的session共享问题
- 英语-TOEFL和GRE复习计划与资料
- check failed status == cudnn_status_success (4 vs. 0) cudnn_status_internal_error
- SpringCloud系列九:SpringCloudConfig 基础配置(SpringCloudConfig 的基本概念、配置 SpringCloudConfig 服务端、抓取配置文件信息、客户端使用 SpringCloudConfig 进行配置、单仓库目录匹配、应用仓库自动选择、仓库匹配模式)
- git 的学习使用记录
- 类型,对象,线程栈,托管堆在运行时的关系,以及clr如何调用静态方法,实例方法,和虚方法(第二次修改)
- Oracle存储过程的调试
- SQL Server 数据库基础笔记分享(下)
- TOJ5398: 签到大富翁(简单模拟) and TOJ 5395: 大于中值的边界元素(数组的应用)
- django中url,静态文件,POST请求的配置 分类: Python 2015-06-01 17:00 789人阅读 评论(0) 收藏
- cloudera项目源代码
- cubieboard安装小记
- oss上传文件夹-cloud2-泽优软件