Adaboost算法的一个简单实现——基于《统计学习方法(李航)》第八章
最近阅读了李航的《统计学习方法(第二版)》,对AdaBoost算法进行了学习。
在第八章的8.1.3小节中,举了一个具体的算法计算实例。美中不足的是书上只给出了数值解,这里用代码将它实现一下,算作一个课后作业。
一、算法简述
Adaboost算法最终输出一个全局分类模型,由多个基本分类模型组成,每个分类模型有一定的权重,用于表示该基本分类模型的可信度。最终根据各基本分类模型的预测结果乘以其权重,通过表决来生成最终的预测(分类)结果。
AdaBoost算法的训练流程图如下:
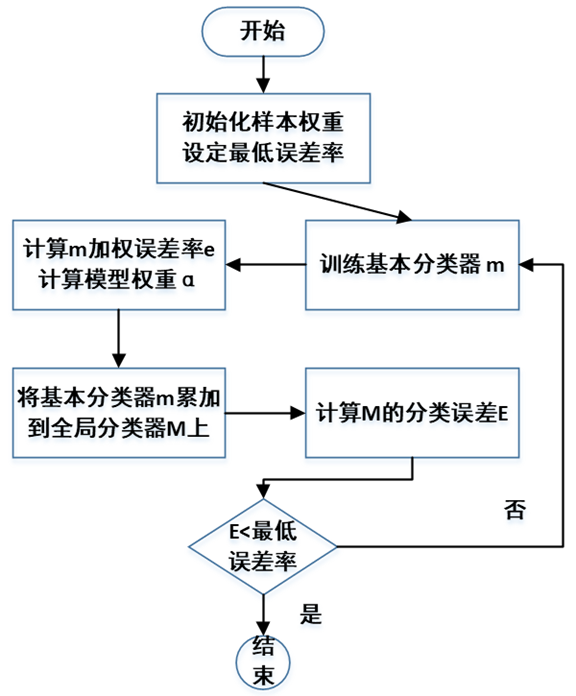 AdaBoost在训练过程中,每一轮循环生成一个基本分类器,并计算其权重,并将其加权累加到全局分类器中,最终在全局分类器的分类误差小于预设值时,结束训练,输出全局分类器。
AdaBoost在训练过程中,每一轮循环生成一个基本分类器,并计算其权重,并将其加权累加到全局分类器中,最终在全局分类器的分类误差小于预设值时,结束训练,输出全局分类器。
流程图中几个符合的含义和计算公式说明如下:
训练样本:共计10组数值,输入(X),输出(Y)如下:
1 data_X = [0,1,2,3,4,5,6,7,8,9]
2 data_Y = [1,1,1,-1,-1,-1,1,1,1,-1]
m:即基本分类器,这里用的是一个决策树桩,即在X<v时,分类为-1或1,当X>v时,分类为1或-1。
e:基本分类器的加权误差率,权重为10个样本各自对应的权重。即统计预测错的样本其权重之和。书中公式如下:
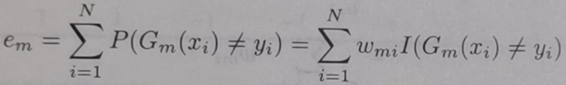
α:基本分类器的权重,就是其预测结果的可信度。书中公式如下:

M:全局分类器,由多个基本分类器与其可信度的乘积加和后得到。
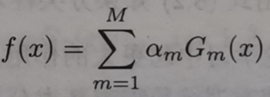
全局分类器在上述公式中即 f(x)。
另外还需要样本权值更新的公式,其中w即各个样本对应的权重,共N个样本,本例中N=10:
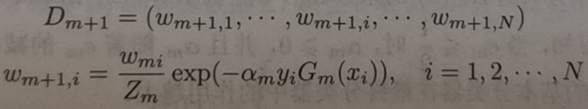
这里简单的引用公式讲解算法,具体可以看书中第八章的描述。不知道粘太多书中的内容会不会侵权=,=
二、代码讲解
下面讲一下代码。
考虑到后续有可能会将其他机器学习算法应用到AdaBoost中,为保证其有一定的拓展性,定义AdaBoost类。
1 class Adaboost(object):
2 def __init__(self,minist_error_rate):
3 self.minist_error_rate = minist_error_rate # 临界误差值,小于该误差即停止训练
4 self.model_list = [] # 记录模型,每一个模型包括[权重,v,方向]三个参数
这里仅初始了两个变量,一个是最低误差率,用来决定什么时候结束训练;另一个是全局分类器对象,list类型;而基本分类器也是list,格式为[权重,v,方向],其中,v就是决策树桩m的分界值。
定义权重初始化函数:
1 def ini_weight(self,sample_x,sample_y): # 初始化样本权重 D ,即D1
2 self.D = [float(1)/len(sample_y)]
3 self.D = self.D*len(sample_y)
使用均值法来进行初始化,10个样本,每个样本的初始权重设为0.1。
之后,再定义单样本预测函数及基本分类器的训练函数。其中,基本分类器训练函数将初始的v值设为0.5,每循环自增1来遍历所有可能性,寻找加权错误率(e)最低的v值。
1 def prediction(self,v_num,direct,input_num):
2 if(input_num<v_num):
3 return direct
4 else:
5 return -direct
6
7 def train_op(self,sample_x,sample_y): # 获取在样本权重下的训练结果
8 error_temp = 9999.9
9 v_record = 0.0
10 direct = 0 # 预测方向,即输入小于v_record时, 样本的预测值为 1 还是 -1 ,
11 for i in range(len(sample_x)-1):
12 v_num = float(i)+0.5
13 # 正向计算一次,即小于v_num 为-1,否则1
14 error_1 = 0.0
15 for j in range(len(sample_x)):
16 pred = self.prediction(v_num,-1,sample_x[j])
17 if(pred!=sample_y[j]):
18 error_1 += self.D[j]*1
19 if(error_1<error_temp):
20 v_record = v_num
21 direct = -1
22 error_temp = error_1
23 # 相反方向再计算一次,即小于v_num 为1,否则-1
24 error_1 = 0.0
25 for j in range(len(sample_x)):
26 pred = self.prediction(v_num,1,sample_x[j])
27 if(pred!=sample_y[j]):
28 error_1 += self.D[j]*1
29 if(error_1<error_temp):
30 v_record = v_num
31 direct = 1
32 error_temp = error_1
33 return error_temp,v_record,direct
有了单个基本训练器的计算函数,下面就需要构建AdaBoost算法的主循环,即计算该基本训练器的权重α并将其纳入全局分类器M。主要依靠update函数实现。
1 def update(self,sample_x,sample_y):
2 error_now,v_record,direct = self.train_op(sample_x,sample_y)
3 print(error_now,v_record,direct)
4 alpha = 0.5*math.log((1-error_now)/error_now)
5 print(alpha)
6 self.model_list.append([alpha,v_record,direct])
7 err_rate = self.error_rate(sample_x,sample_y)
8 while(err_rate>self.minist_error_rate):
9 Zm = 0.0
10 for i in range(len(sample_x)):
11 Zm += self.D[i]*math.exp(-alpha*self.prediction(v_record,direct,sample_x[i])*sample_y[i])
12 # 更新 样本权重向量self.D
13 for i in range(len(sample_y)):
14 self.D[i] = self.D[i] * math.exp(-alpha*self.prediction(v_record,direct,sample_x[i])*sample_y[i]) / Zm
15 error_now,v_record,direct = self.train_op(sample_x,sample_y)
16 alpha = 0.5*math.log((1-error_now)/error_now)
17 self.model_list.append([alpha,v_record,direct])
18 err_rate = self.error_rate(sample_x,sample_y)
主循环靠while循环来实现,全局模型分类误差率小于设定的最低误差率时,停止循环,输出全局分类器。
最终在main函数中,调用该类,按顺序执行初始化样本权重、执行主循环、打印模型结构。
1 if __name__ == "__main__":
2 ada_obj = Adaboost(0.005)
3 ada_obj.ini_weight(data_X,data_Y)
4 ada_obj.update(data_X,data_Y)
5 ada_obj.print_model()
其中,最低误差率设为0.005,在本例中即要求10个样本全部分类正确。最终程序输出:

可以看出全局分类器由3个基本分类器组成,权重即为基本分类器的可信度,临界值则为v值,方向则设定为输入小于v值时,分类的结果。即第一个模型(0 layer)为当输入小于2.5时,分类结果为1;否则为-1。解得的答案也与书中结果相同。
下面是全部代码,感兴趣同学可以在python环境中试一试。
1 # coding:utf-8
2
3 import math
4 import numpy as np
5
6 data_X = [0,1,2,3,4,5,6,7,8,9]
7 data_Y = [1,1,1,-1,-1,-1,1,1,1,-1]
8
9 # data_X = [0,1,2,3,4,5,6,7,8,9,10,11,12,13]
10 # data_Y = [1,1,1,-1,-1,-1,1,1,1,-1,1,1,-1,-1]
11
12 print(len(data_X),len(data_Y))
13
14 class Adaboost(object):
15 def __init__(self,minist_error_rate):
16 self.minist_error_rate = minist_error_rate # 临界误差值,小于该误差即停止训练
17 self.model_list = [] # 记录模型,每一个模型包括[权重,v,方向]三个参数
18
19 def ini_weight(self,sample_x,sample_y): # 初始化样本权重 D ,即D1
20 self.D = [float(1)/len(sample_y)]
21 self.D = self.D*len(sample_y)
22
23 def prediction(self,v_num,direct,input_num):
24 if(input_num<v_num):
25 return direct
26 else:
27 return -direct
28
29 def train_op(self,sample_x,sample_y): # 获取在样本权重下的训练结果
30 error_temp = 9999.9
31 v_record = 0.0
32 direct = 0 # 预测方向,即输入小于v_record时, 样本的预测值为 1 还是 -1 ,
33 for i in range(len(sample_x)-1):
34 v_num = float(i)+0.5
35 # 正向计算一次,即小于v_num 为-1,否则1
36 error_1 = 0.0
37 for j in range(len(sample_x)):
38 pred = self.prediction(v_num,-1,sample_x[j])
39 if(pred!=sample_y[j]):
40 error_1 += self.D[j]*1
41 if(error_1<error_temp):
42 v_record = v_num
43 direct = -1
44 error_temp = error_1
45 # 相反方向再计算一次,即小于v_num 为1,否则-1
46 error_1 = 0.0
47 for j in range(len(sample_x)):
48 pred = self.prediction(v_num,1,sample_x[j])
49 if(pred!=sample_y[j]):
50 error_1 += self.D[j]*1
51 if(error_1<error_temp):
52 v_record = v_num
53 direct = 1
54 error_temp = error_1
55 return error_temp,v_record,direct
56
57 def one_model_pred(self,input_num,model_num): # 计算单个子模型的预测结果
58 m = self.model_list[model_num]
59 return self.prediction(m[1],m[2],input_num)
60
61 def error_rate(self,sample_x,sample_y): # 计算各子模型投票表决的错误率
62 wrong_num = 0
63 for i in range(len(sample_y)):
64 out = 0.0
65 for j in range(len(self.model_list)):
66 out_temp = self.model_list[j][0]*self.one_model_pred(sample_x[i],j)
67 out += out_temp
68 if(out>=0):
69 out = 1
70 else:
71 out = -1
72 if(out==sample_y[i]):
73 pass
74 else:
75 wrong_num += 1
76 return float(wrong_num)/len(sample_y)
77
78 def update(self,sample_x,sample_y):
79 error_now,v_record,direct = self.train_op(sample_x,sample_y)
80 # print(error_now,v_record,direct)
81 alpha = 0.5*math.log((1-error_now)/error_now)
82 # print(alpha)
83 self.model_list.append([alpha,v_record,direct])
84 err_rate = self.error_rate(sample_x,sample_y)
85 while(err_rate>self.minist_error_rate):
86 Zm = 0.0
87 for i in range(len(sample_x)):
88 Zm += self.D[i]*math.exp(-alpha*self.prediction(v_record,direct,sample_x[i])*sample_y[i])
89 # 更新 样本权重向量self.D
90 for i in range(len(sample_y)):
91 self.D[i] = self.D[i] * math.exp(-alpha*self.prediction(v_record,direct,sample_x[i])*sample_y[i]) / Zm
92 error_now,v_record,direct = self.train_op(sample_x,sample_y)
93 alpha = 0.5*math.log((1-error_now)/error_now)
94 self.model_list.append([alpha,v_record,direct])
95 err_rate = self.error_rate(sample_x,sample_y)
96
97 def print_model(self):
98 print('模型打印: 权重 临界值 方向')
99 for i in range(len(self.model_list)):
100 print(str(i)+' layer :'+str(self.model_list[i][0])+' '+str(self.model_list[i][1])+' '+str(self.model_list[i][2]))
101
102 if __name__ == "__main__":
103 ada_obj = Adaboost(0.005)
104 ada_obj.ini_weight(data_X,data_Y)
105 ada_obj.update(data_X,data_Y)
106 ada_obj.print_model()
参考:
最新文章
- 使用XHR2或Jsonp实现跨域以及实现原理
- xsd.exe的使用
- Android学习系列(42)--Android Studio实战技巧
- 加载form表单
- LINQ To SQL 语法及实例大全
- 源码-hadoop1.1.0-core-org.apache.hadoop
- eclipse+tomcat+httpServlet初学
- JSTL解析——007——fmt标签库02
- java程序的10个调试技巧
- 【Tomcat】本地域名访问设置
- Nginx负载均衡:分布式/热备Web Server的搭建
- Jedis实现发布订阅功能
- BMP文件格式详解
- (转)Spring Boot 2 (六):使用 Docker 部署 Spring Boot 开源软件云收藏
- Django 学习第五天——自定义过滤器及标签
- jenkins checkstyle:local variable hides a field
- win server 2008添加磁盘-脱机转换为联机状态方法
- LeetCode——pow(x, n)
- vim 末行模式简单练习
- 12 TCP服务器 进程 线程 非阻塞