debug补充、员工管理系统、字符编码、文件操作
2024-09-08 19:10:50
一、debug补充
在当前行的代码左侧点击一下,会出现一个红点(打断点)
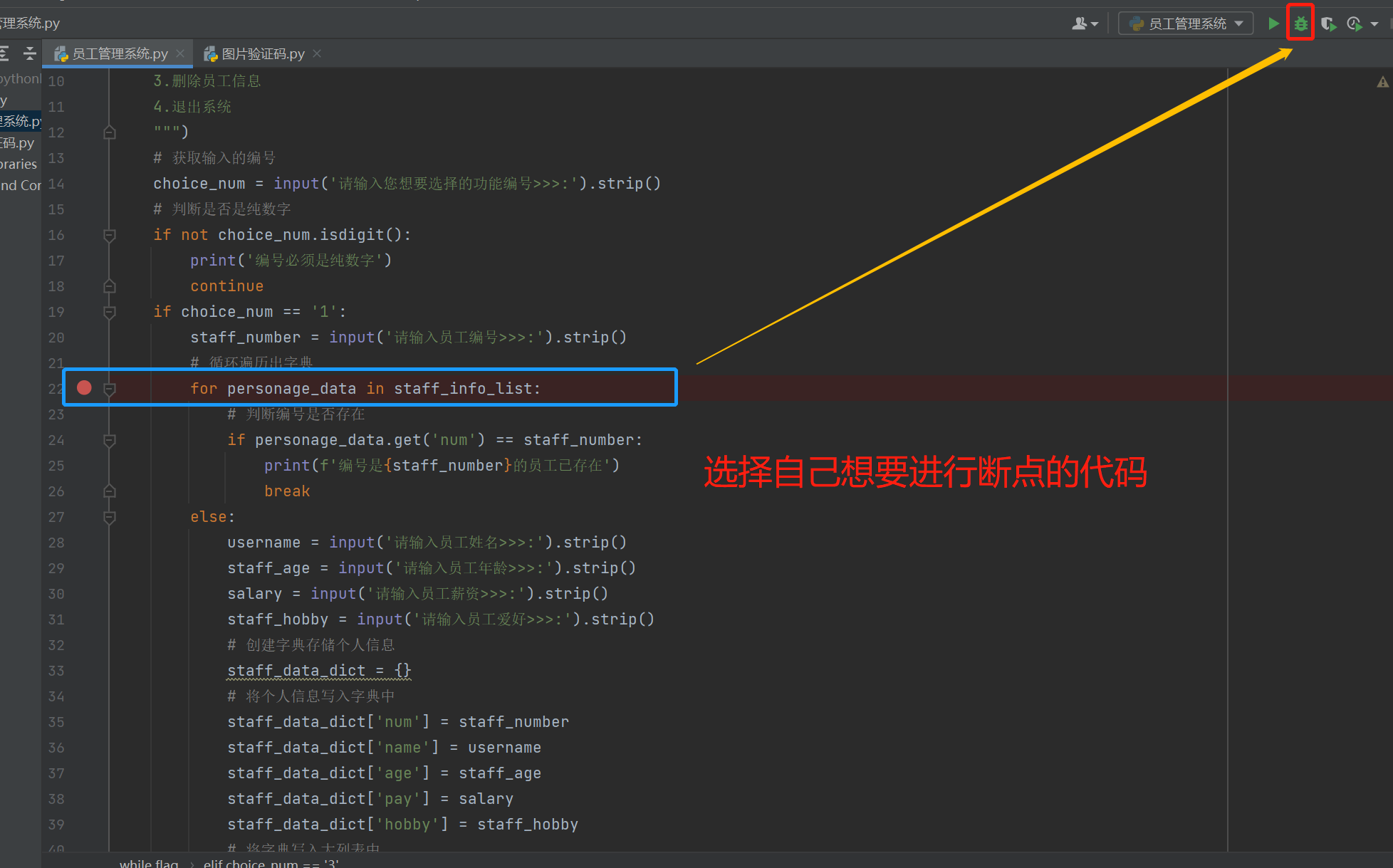
在代码编辑区域右键选择debug,不要在选择run
二、员工管理系统
# 创建大列表
staff_info_list = []
# 定义全局标志位
flag = True
# 循环打印信息
while flag:
print("""
1.添加员工信息
2.查看员工信息
3.删除员工信息
4.退出系统
""")
# 获取输入的编号
choice_num = input('请输入您想要选择的功能编号>>>:').strip()
# 判断是否是纯数字
if not choice_num.isdigit():
print('编号必须是纯数字')
continue
if choice_num == '1':
staff_number = input('请输入员工编号>>>:').strip()
# 循环遍历出字典
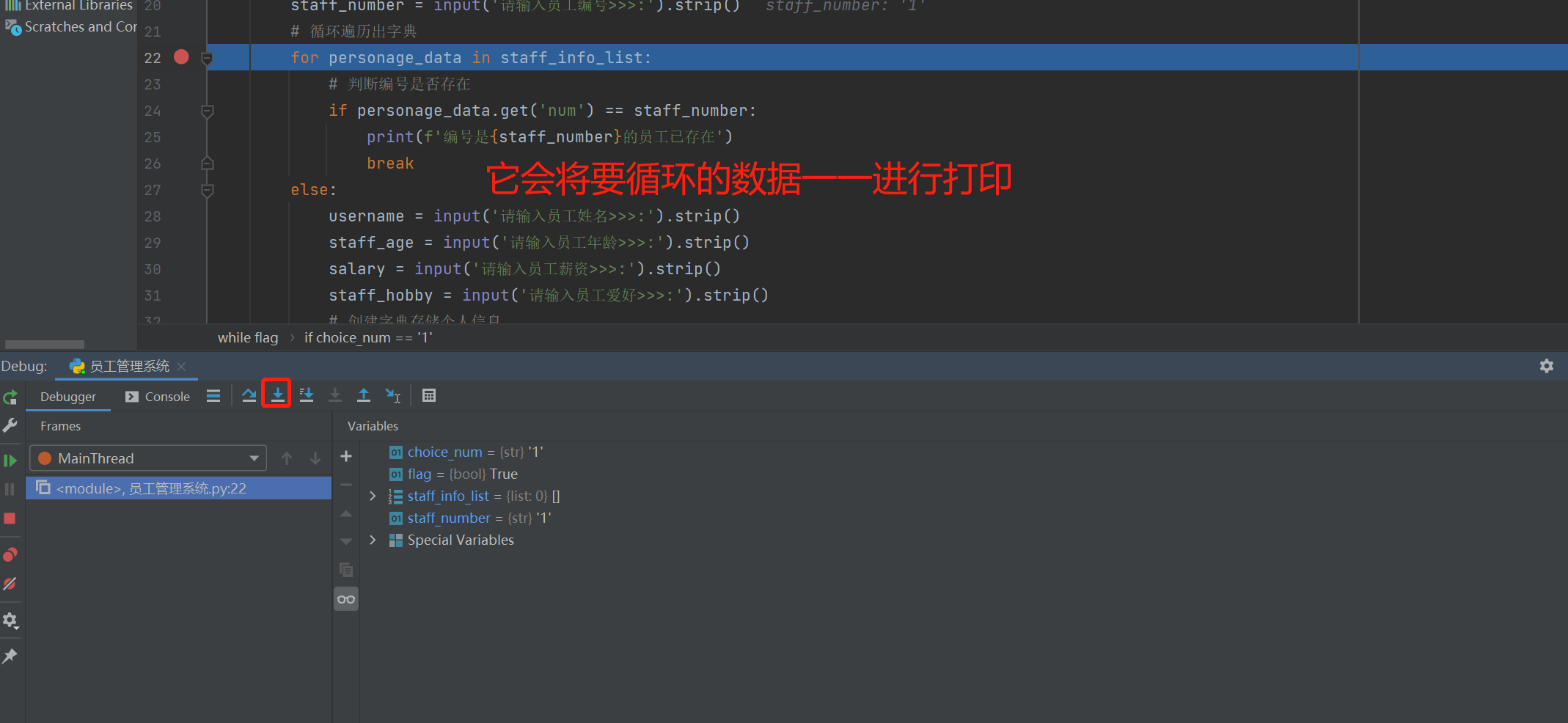
for personage_data in staff_info_list:
# 判断编号是否存在
if personage_data.get('num') == staff_number:
print(f'编号是{staff_number}的员工已存在')
break
else:
username = input('请输入员工姓名>>>:').strip()
staff_age = input('请输入员工年龄>>>:').strip()
salary = input('请输入员工薪资>>>:').strip()
staff_hobby = input('请输入员工爱好>>>:').strip()
# 创建字典存储个人信息
staff_data_dict = {}
# 将个人信息写入字典中
staff_data_dict['num'] = staff_number
staff_data_dict['name'] = username
staff_data_dict['age'] = staff_age
staff_data_dict['pay'] = salary
staff_data_dict['hobby'] = staff_hobby
# 将字典写入大列表中
staff_info_list.append(staff_data_dict)
print(f'当前员工{username}添加成功')
elif choice_num == '2':
print('查看员工信息')
# 循环打印列表中的字典用格式化输出展示出来
for data in staff_info_list:
print(f"""
~~~~~~~~user info {data.get('name')}~~~~~~~~~
编号:{data.get('num')}
姓名:{data.get('name')}
年龄:{data.get('age')}
薪资:{data.get('pay')}
爱好:{data.get('hobby')}
~~~~~~~~~~~~~~~~~~~~~~~~~~~~
""")
elif choice_num == '3':
print('删除员工信息')
# 获取员工编号
number = input('请输入您想要删除的员工编号>>>:').strip()
# 定义计数器(索引)
indexes = 0
# 循环大列表中的字典
for data in staff_info_list:
# 用字典中的编号和输入的编号做比较
if data.get('num') == number:
# 索引删除员工信息
del staff_info_list[indexes]
print(f'编号{number}的员工删除成功')
break
# 索引加一
else:
indexes += 1
else:
print('编号不存在')
elif choice_num == '4':
print('退出系统')
# 修改全局标志位
flag = False
else:
print('暂无该功能编号')
三、字符编码
(1)、概念
- 我们在计算机中经常见到的文字、数字、英文字母、图片、视频、音频等,这些信息在计算机中都是以二进制的形式存储的,因为内存条是电子元器件组成的,它们只有高电平低电平两种状态,即0和1两个值,这个翻译本叫做字符编码表。
(2)、字符编码的发展史
# 1.一家独大
计算机是由美国人发明的 为了能够让计算机识别英文
需要发明一个数字跟英文字母的对应关系
ASCII码:记录了英文字母跟数字的对应关系
用8bit(1字节)来表示一个英文字符
# 2.群雄割据
中国人
GBK码:记录了英文、中文与数字的对应关系
用至少16bit(2字节)来表示一个中文字符
很多生僻字还需要使用更多的字节
英文还是用8bit(1字节)来表示
日本人
shift_JIS码:记录了英文、日文与数字的对应关系
韩国人
Euc_kr码:记录了英文、韩文与数字的对应关系
"""
每个国家的计算机使用的都是自己定制的编码本
不同国家的文本数据无法直接交互 会出现"乱码"
"""
# 3.天下一统
unicode万国码
兼容所有国家语言字符
起步就是两个字节来表示字符
# utf系列:utf8 utf16 ...
专门用于优化unocide存储问题
英文还是采用一个字节 中文三个字节
| 表示字符 | 十六进制形式 | 十进制形式 |
|---|---|---|
| 0~9 | 0x30~0x39 | 48~57 |
| A~Z | 0x41~0x5A | 65~90 |
| a~z | 0x61~0x7A | 97~122 |
(3)、字符编码的使用
# 1. 如何解决乱码问题?
文本文件使用什么字符编码保存,打开的时候就要使用对应的字符编码
# 2. python解释器版本不同带来的差异
# python2 解释器使用的字符编码还是ASCII表
# python3 使用的是utf8编码
# 3. 添加文件模板
settings
Editor
File and code template
python script
# 4. 编码与解码(核心)
# 编码:
将人类能够读懂的语言转为计算机能够读懂的语言
# bytes 字节,看成是二进制
s1 = ss.encode('utf8')
print(s1, type(s1)) # b'\xb3\xc3\xc4\xea\xc7\xe1\xa3\xac\xd1\xa7\xbc\xbc\xc4\xdc\xa3\xac\xd1\xf8\xbb\xee\xd7\xd4\xbc\xba'
# 解码:
将计算机能够读懂的语言转为人类能够读懂的语言
print(s1.decode('utf8'))
s = b'kevin123' # 只有英文字符和数字,要想编码的话,直接使用前缀b
print(s.encode('utf8'))
四、文件操作
(1)、概念讲解
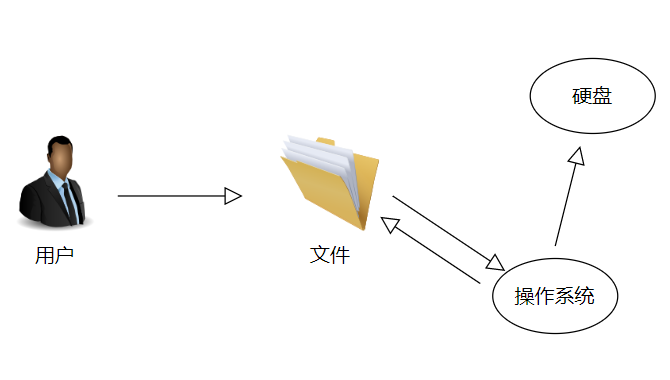
- 首先我们要知道文件是操作系统暴露给用户的快捷方式,当我们使用的时候只需要双击就能将文件读取到内存中运行,使用ctrl+s就可以将文件保存到硬盘中,这些对文件进行修改或使用的动作就是文件操作,除了借助操作系统,我们可以使用python代码进行这一系列的操作
(2)、通过代码打开文件的两种方式
# 方式一:
f=open(文件路径,文件读写模式,encoding='文件编码类型(默认情况下为utf8)')
f.close()
"""
特点:一次只能打开一个文件,使用完文件后需要输入f.close关闭文件,但是如果忘记关闭文件并不会有提示
"""
# 方法二:
with open(文件路径,文件读写模式,encoding='文件编码类型(默认情况下为utf8)') as f1,open(文件路径,文件读写模式,encoding='文件编码类型(默认情况下为utf8)') as f2:
with条件下的操作代码
"""
特点:当我们使用with方法打开文件的时候,可以一次性打开多个文件并且不需要输入close方法,会自动运行close方法
"""
# 文件的类型:txt word excel py
# 1. 打开文件
# open('文件路径', 'r', '字符编码')
f=open('a.txt', 'r', encoding='utf-8')
# print(f) # <_io.TextIOWrapper name='a.txt' mode='r' encoding='utf8'> 文件句柄
print(f.read())
f.close() # 关闭文件
"""
语法格式:
open('文件路径', '读写模式', '字符编码')
"""
# r的作用
'''当路径中可能存在有转移的字符时,字符串前面加上r来解决转义的问题'''
r'D:\python25\day09\a.txt'
(3)、文件的读写模式
1. r >>> read: 只读 # 只能读,不能写
2. w >>> write:只写 # 只能写,不能读
3. a >>> append: 追加
# 读写模式
# 1. r
# 路径不存在,直接报错
# with open(r'a.txt', 'r', encoding='utf-8') as f:
# print(f.read())
# 2. w
# 如果路径不存在,会新建一个文件出来
# with open('b.txt', 'w', encoding='utf-8') as f:
# pass
# 1. 会先清空文件中得内容 2. 在进行写内容
'''写文件的是一定要小心,它会清空文件的'''
with open('a.txt', 'w', encoding='utf-8') as f:
f.write('oldboy\n')
f.write('oldboy\n')
f.write('oldboy\n')
f.write('oldboy\n')
f.write('oldboy\n')
# a:追加模式
# 路径不存在的时候,也会新建一个文件出来
# with open('a.txt', 'a', encoding='utf-8') as f:
# f.write('oldgirl\n')
最新文章
- JavaScript面向对象编程学习笔记
- SRS文档 软件需求说明书
- SpringMVC学习总结(二)——DispatcherServlet详解
- BootStrap入门教程 (一) :手脚架Scaffolding(全局样式(Global Style),格网系统(Grid System),流式格网(Fluid grid System),自定义(Customing),布局(Layouts))
- Using GUID to generate the unique file name in C#
- HBase经常使用操作之namespace
- vm10虚拟机安装Mac OS X10.10教程
- ContextMenu控件引用以及不用v4包的方法
- C++primer学习——左值和右值
- Apache代理转发http到https
- KVM虚拟机配置笔记
- Windows 下配置 Apache 支持 https
- strcat、num2str
- 2017-2018-2 1723《程序设计与数据结构》第九周作业 & 第二周结对编程 总结
- CF 681
- happens-before俗解
- 全网最详细的Sublime Text 3的设置字体及字体大小(图文详解)
- C#加密解密DES字符串<转>
- tomcat6-servlet规范对接 与 ClassLoader隔离
- Qt学习--初学注意事项