PyTorch复现AlexNet学习笔记
PyTorch复现AlexNet学习笔记
一篇简单的学习笔记,实现五类花分类
这里只介绍复现的工作,如果想了解更多有关网络的细节,请去看论文《ImageNet Classification with Deep Convolutional Neural Networks》
简单说明下数据集,下载链接

下载解压数据集
一、环境准备
可以去看上一篇博客,里面写的很详细了,并且推荐了一篇炮哥的环境搭建环境
二、模型搭建、训练
1.整体框图
AlexNet整体框图,padding,stride,需要根据论文计算,前后卷积大小没变,一般padding=2

2.net.py
网络整体结构代码


1 import torch
2 from torch import nn
3 import torch.nn.functional as F
4
5 class MyAlexNet(nn.Module):
6 def __init__(self,num_classes):
7 super(MyAlexNet, self).__init__()
8 self.c1 = nn.Conv2d(in_channels=3,out_channels=48,kernel_size=11,stride=4,padding=2)
9 self.ReLu = nn.ReLU()
10 self.c2 = nn.Conv2d(in_channels=48,out_channels=128,kernel_size=5,stride=1,padding=2)
11 self.s2 = nn.MaxPool2d(2)
12 self.c3 = nn.Conv2d(in_channels=128,out_channels=192,kernel_size=3,stride=1,padding=2)
13 self.s3 = nn.MaxPool2d(2)
14 self.c4 = nn.Conv2d(in_channels=192,out_channels=192,kernel_size=3,stride=1,padding=1)
15 self.c5 = nn.Conv2d(in_channels=192,out_channels=128,kernel_size=3,stride=1,padding=1)
16 self.s5 = nn.MaxPool2d(kernel_size=3,stride=2)
17 self.flatten = nn.Flatten()
18 self.f6 = nn.Linear(4608,2048)#经过池化后的神经元个数(13-3)/2+1=6,6*6*128=4608
19 self.f7 = nn.Linear(2048,2048)
20 self.f8 = nn.Linear(2048,1000)
21 self.f9 = nn.Linear(1000,num_classes)#分类类别数
22
23 def forward(self,x):
24 x = self.ReLu(self.c1(x))
25 x = self.ReLu(self.c2(x))
26 x = self.s2(x)
27 x = self.ReLu(self.c3(x))
28 x = self.s3(x)
29 x = self.ReLu(self.c4(x))
30 x = self.ReLu(self.c5(x))
31 x = self.s5(x)
32 x = self.flatten(x)
33 x = self.f6(x)
34 x = F.dropout(x,0.5)
35 x = self.f7(x)
36 x = F.dropout(x,0.5)
37 x = self.f8(x)
38 x = F.dropout(x,0.5)
39 x = self.f9(x)
40
41 return x
42
43 if __name__ =="__main__":
44 x = torch.rand([1, 3, 224, 224])
45 model = MyAlexNet(num_classes=5)
46 y = model(x)
47 print(y)
48 # 统计模型参数 total param num 16632442
49 # sum = 0
50 # for name, param in model.named_parameters():
51 # num = 1
52 # for size in param.shape:
53 # num *= size
54 # sum += num
55 # # print("{:30s} : {}".format(name, param.shape))
56 # print("total param num {}".format(sum)) # total param num 134,281,029
net.py
写完后保存,运行可以检查是否报错
3.数据划分
分好后的数据集

运行下面代码将数据按一定比例,划分为训练集和验证集
1 import os
2 from shutil import copy
3 import random
4
5
6 def mkfile(file):
7 if not os.path.exists(file):
8 os.makedirs(file)
9
10
11 # 获取data文件夹下所有文件夹名(即需要分类的类名)
12 file_path = 'data' #需要划分数据集的路径
13 flower_class = [cla for cla in os.listdir(file_path)]
14
15 # 创建 训练集train 文件夹,并由类名在其目录下创建5个子目录
16 mkfile('data/train')
17 for cla in flower_class:
18 mkfile('data/train/' + cla)
19
20 # 创建 验证集val 文件夹,并由类名在其目录下创建子目录
21 mkfile('data/val')
22 for cla in flower_class:
23 mkfile('data/val/' + cla)
24
25 # 划分比例
26 split_rate = 0.2 #20%为验证集
27
28 # 遍历所有类别的全部图像并按比例分成训练集和验证集
29 for cla in flower_class:
30 cla_path = file_path + '/' + cla + '/' # 某一类别的子目录
31 images = os.listdir(cla_path) # iamges 列表存储了该目录下所有图像的名称
32 num = len(images)
33 eval_index = random.sample(images, k=int(num * split_rate)) # 从images列表中随机抽取 k 个图像名称
34 for index, image in enumerate(images):
35 # eval_index 中保存验证集val的图像名称
36 if image in eval_index:
37 image_path = cla_path + image
38 new_path = 'data/val/' + cla
39 copy(image_path, new_path) # 将选中的图像复制到新路径
40
41 # 其余的图像保存在训练集train中
42 else:
43 image_path = cla_path + image
44 new_path = 'data/train/' + cla
45 copy(image_path, new_path)
46 print("\r[{}] processing [{}/{}]".format(cla, index + 1, num), end="") # processing bar
47 print()
48
49 print("processing done!")
数据划分的代码
4.train.py
训练的代码,训练结束后画出训练集和验证集的loss,准确度,60轮,batch-size=16,SGD优化算法,学习率0.01,10轮变为原来的0.5。
1 #修改后加进度条的代码
2 import json
3 import torch
4 from torch import nn
5 from NET import MyAlexNet
6 import numpy as np
7
8 from tqdm import tqdm#用于画进度条
9
10 from torch.optim import lr_scheduler
11
12 import os
13 import sys
14
15 from torchvision import transforms
16 from torchvision.datasets import ImageFolder
17 from torch.utils.data import DataLoader
18
19 import matplotlib.pyplot as plt
20
21 # 解决中文显示问题
22 plt.rcParams['font.sans-serif'] = ['SimHei']
23 plt.rcParams['axes.unicode_minus'] = False
24
25 # 如果显卡可用,则用显卡进行训练
26 device = 'cuda' if torch.cuda.is_available() else 'cpu'
27 print("using {} device".format(device))
28
29
30 # 将图像RGB三个通道的像素值分别减去0.5,再除以0.5.从而将所有的像素值固定在[-1,1]范围内
31 #normalize = transforms.Normalize(std=[0.5,0.5,0.5],mean=[0.5,0.5,0.5])#image=(image-mean)/std
32 data_transform = {
33 "train":transforms.Compose([
34 transforms.Resize((224,224)),#裁剪为224*224
35 transforms.RandomVerticalFlip(),#随机垂直旋转
36 transforms.ToTensor(),#将0-255范围内的像素转为0-1范围内的tensor
37 transforms.Normalize(std=[0.5,0.5,0.5],mean=[0.5,0.5,0.5])#归一化
38 ]),
39 "val":transforms.Compose([
40 transforms.Resize((224,224)),#裁剪为224*224
41 transforms.ToTensor(),#将0-255范围内的像素转为0-1范围内的tensor
42 transforms.Normalize(std=[0.5,0.5,0.5],mean=[0.5,0.5,0.5])#归一化
43 ])}
44
45 #数据集路径
46 ROOT_TRAIN = 'data/train'
47 ROOT_TEST = 'data/val'
48
49 batch_size = 16
50
51 train_dataset = ImageFolder(ROOT_TRAIN,transform=data_transform["train"])#ImageFolder()根据文件夹名来对图像添加标签
52 val_dataset = ImageFolder(ROOT_TEST,transform=data_transform["val"])#可以利用print(val_dataset.imgs)对象查看,返回列表形式('data/val\\cat\\110.jpg', 0)
53 #print(val_dataset.imgs)
54
55 # nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
56 # print('Using {} dataloader workers every process'.format(nw))
57
58 train_dataloader = DataLoader(train_dataset,batch_size=batch_size,shuffle=True)
59 val_dataloader = DataLoader(val_dataset,batch_size=batch_size,shuffle=True)
60
61 flow_list = train_dataset.class_to_idx#转换维字典,train_dataset里有这个对象
62 # {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
63 cla_dict = dict((val,key) for key,val in flow_list.items())#键值对转换
64 #{0: 'daisy', 1: 'dandelion', 2: 'roses', 3: 'sunflowers', 4: 'tulips'}
65 # write dict into json file
66 json_str = json.dumps(cla_dict, indent=4)
67 with open('class_indices.json', 'w') as json_file:
68 json_file.write(json_str) # 保存json文件(好处,方便转换为其它类型数据)用于预测用
69
70 train_num = len(train_dataset)
71 val_num = len(val_dataset)
72 print("using {} images for training, {} images for validation.".format(train_num,val_num))
73
74 # 调用net里面的定义的网络模型, 如果GPU可用则将模型转到GPU
75 model = MyAlexNet(num_classes=5).to(device)
76
77 #加载预训练模型
78 # weights_path = "save_model/best_model.pth"
79 # assert os.path.exists(weights_path), "file: '{}' dose not exist.".format(weights_path)
80 # missing_keys, unexpected_keys = net.load_state_dict(torch.load(weights_path,),strict=False)
81
82 #定义损失函数
83 loss_fn = nn.CrossEntropyLoss()
84
85 #定义优化器
86 optimizer = torch.optim.SGD(model.parameters(),lr=0.01,momentum=0.9)#googlenet用的是adam
87 # 学习率每隔10epoch变为原来的0.5
88 lr_scheduler = lr_scheduler.StepLR(optimizer,step_size=10,gamma=0.5)
89
90 #定义训练函数
91 def train(dataloader,model,loss_fn,optimizer,i,epoch):
92 model.train()
93 loss,current,n = 0.0,0.0,0
94 train_bar = tqdm(dataloader,file=sys.stdout)#输出方式,默认为sys.stderr
95 for batch,(x,y) in enumerate(train_bar):#enumerate()默认两个参数,第一个用于记录序号,默认0开始,第二个参数(x,y)才是需要遍历元素(dataloder)的值
96 #前向传播
97 image,y = x.to(device),y.to(device)
98 output = model(image)
99 cur_loss = loss_fn(output,y)
100 _,pred = torch.max(output,axis=-1)
101 cur_acc = torch.sum(y==pred)/output.shape[0]
102 #反向传播
103 optimizer.zero_grad()#梯度归零
104 cur_loss.backward()
105 optimizer.step()
106 loss += cur_loss
107 current += cur_acc
108 n += 1
109 train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(i + 1, epoch, cur_loss)
110 train_loss = loss / n
111 train_acc = current / n
112 print(f'train_loss:{train_loss}')
113 print(f'train_acc:{train_acc}')
114 return train_loss,train_acc
115
116 #定义验证函数
117 def val(dataloader,model,loss_fn,i,epcho):
118 #转换为验证模型
119 model.eval()
120 loss, current, n = 0.0, 0.0, 0
121 with torch.no_grad():
122 val_bar = tqdm(dataloader,file=sys.stdout)
123 for batch, (x, y) in enumerate(val_bar): # enumerate()默认两个参数,第一个用于记录序号,默认0开始,第二个参数(x,y)才是需要遍历元素(dataloder)的值
124 # 前向传播
125 image, y = x.to(device), y.to(device)
126 output = model(image)
127 cur_loss = loss_fn(output, y)
128 _, pred = torch.max(output, axis=-1)
129 cur_acc = torch.sum(y == pred) / output.shape[0]
130 loss += cur_loss
131 current += cur_acc
132 n += 1
133 val_bar.desc = "val epoch[{}/{}] loss:{:.3f}".format(i + 1, epoch, cur_loss)
134 val_loss = loss / n
135 val_acc = current / n
136 print(f'val_loss:{val_loss}')
137 print(f'val_acc:{val_acc}')
138 return val_loss, val_acc
139
140 #画图函数
141 def matplot_loss(train_loss,val_loss):
142 plt.figure() # 声明一个新画布,这样两张图像的结果就不会出现重叠
143 plt.plot(train_loss,label='train_loss')#画图
144 plt.plot(val_loss, label='val_loss')
145 plt.legend(loc='best')#图例
146 plt.ylabel('loss',fontsize=12)
147 plt.xlabel('epoch',fontsize=12)
148 plt.title("训练集和验证集loss对比图")
149 plt.savefig('result/loss.jpg')
150
151 def matplot_acc(train_acc,val_acc):
152 plt.figure() # 声明一个新画布,这样两张图像的结果就不会出现重叠
153 plt.plot(train_acc, label='train_acc') # 画图
154 plt.plot(val_acc, label='val_acc')
155 plt.legend(loc='best') # 图例
156 plt.ylabel('acc', fontsize=12)
157 plt.xlabel('epoch', fontsize=12)
158 plt.title("训练集和验证集acc对比图")
159 plt.savefig('result/acc.jpg')
160
161 #开始训练
162 train_loss_list = []
163 val_loss_list = []
164 train_acc_list = []
165 val_acc_list = []
166
167 epoch = 60
168 max_acc = 0
169
170 for i in range(epoch):
171 lr_scheduler.step()#学习率迭代,10epoch变为原来的0.5
172 train_loss,train_acc = train(train_dataloader,model,loss_fn,optimizer,i,epoch)
173 val_loss,val_acc = val(val_dataloader,model,loss_fn,i,epoch)
174
175 train_loss_list.append(train_loss)
176 train_acc_list.append(train_acc)
177 val_loss_list.append(val_loss)
178 val_acc_list.append(val_acc)
179 #保存最好的模型权重
180 if val_acc >max_acc:
181 folder = 'save_model'
182 if not os.path.exists(folder):
183 os.mkdir('save_model')
184 max_acc = val_acc
185 print(f'save best model,第{i+1}轮')
186 torch.save(model.state_dict(),'save_model/best_model.pth')#保存
187 #保存最后一轮
188 if i == epoch - 1:
189 torch.save(model.state_dict(), 'save_model/last_model.pth') # 保存
190 print("done")
191
192 #画图
193 matplot_loss(train_loss_list,val_loss_list)
194 matplot_acc(train_acc_list,val_acc_list)
train.py
最后一轮的结果
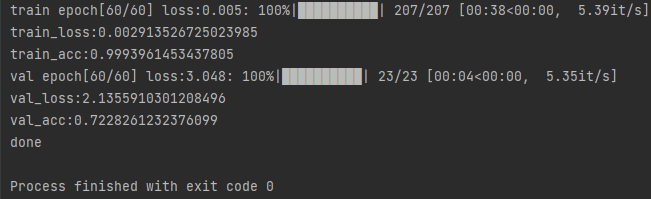
训练结束后可以得到训练集和验证集的loss,acc对比图:
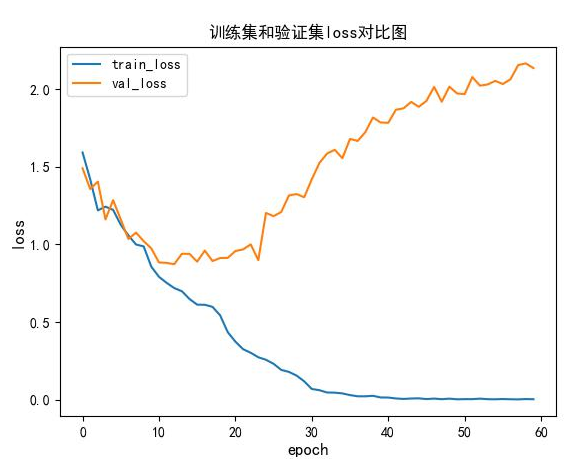
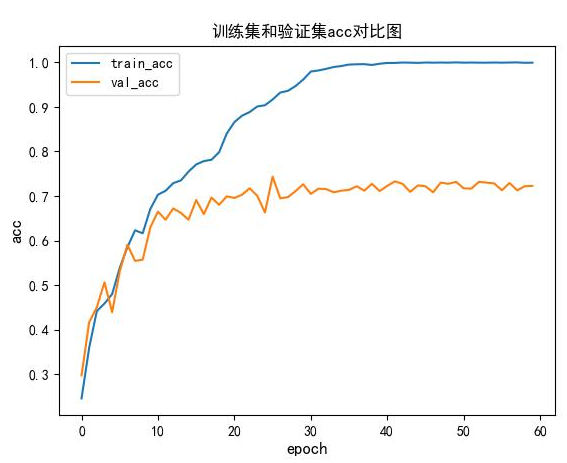
简单的评估下:模型在25轮左右,模型对训练集过拟合了。
如果想提高测试集准确度,需要去采用些手段来防止模型过拟合,比如正则化,数据增强等
三、模型测试
测试代码,这里用的测试集其实是之前训练验证集,本来是要另外创建一个的
1 import os
2 import json
3 import torch
4 from PIL import Image
5 from torchvision import transforms
6 import matplotlib.pyplot as plt
7 from NET import MyAlexNet
8
9 def main():
10 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
11
12 data_transform = transforms.Compose([
13 transforms.Resize((224,224)),
14 transforms.ToTensor(),
15 transforms.Normalize((0.5, 0.5, 0.5),(0.5, 0.5, 0.5))
16 ])
17 #load image
18 img_path = "data/val/tulips/8677713853_1312f65e71.jpg"
19 assert os.path.exists(img_path),"file:'{}' dose not exist. ".format(img_path)
20 img = Image.open(img_path)
21 plt.imshow(img)
22
23 #[N, C, H, W]归一化
24 img = data_transform(img)
25 # expand batch dimension
26 img = torch.unsqueeze(img,dim=0)
27
28 # read class_indict
29 json_path = './class_indices.json'
30 assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
31
32 with open(json_path,"r") as f:
33 class_indict = json.load(f)
34
35 #实例化模型
36 model = MyAlexNet(num_classes=5).to(device)
37
38 #加载权重
39 weights_path = "save_model/best_model.pth"
40 assert os.path.exists(weights_path), "file: '{}' dose not exist.".format(weights_path)
41 missing_keys,unexpected_keys = model.load_state_dict(torch.load(weights_path,map_location=device),
42 strict=False)
43 model.eval()
44 with torch.no_grad():
45 #预测
46 output = torch.squeeze(model(img.to(device))).cpu()
47 predict = torch.softmax(output, dim=0)
48 predict_cla = torch.argmax(predict).numpy()
49 #最大概率结果
50 print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)],
51 predict[predict_cla].numpy())
52 #前10个类别
53 plt.title(print_res)
54 for i in range(len(predict)):
55 print("class: {:10} prob: {:.3}".format(class_indict[str(i)],
56 predict[i].numpy()))
57 plt.show()
58 if __name__=="__main__":
59 os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
60 main()
test.py
运行代码后,对模型进行推理,去网上找几张图片
下面是一张蒲公英照片,以及5类花预测的概率显示(右边)
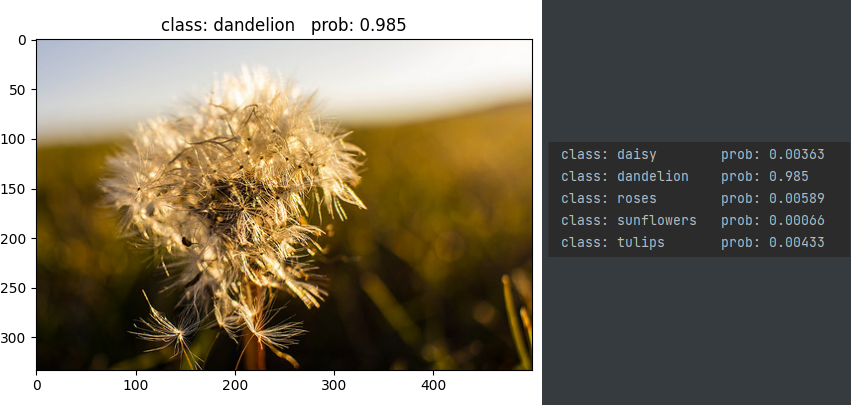
总结
流程还是很顺利的,就是最后模型对训练集过拟合了,但精度还是很高的。
自己敲一下代码,会学到很多不懂的东西
比如ImageFolder()这个函数,是按照文件夹名字,来给文件夹里的数据打上标签
可以利用print(val_dataset.imgs)对象查看,返回列表形式('data/val\\cat\\110.jpg', 0)
最后,多看,多学,多试,总有一天你会称为大佬!
最新文章
- 查看mysqll账号信息
- 未能加载文件或程序集“Enyim.Caching”或它的某一个依赖项。未能验证强名称签名
- 年前辞职-WCF入门学习(3)
- Linux - full name of command
- WinForm Control - DataGridView
- DevExpress控件使用小结 z
- TCP三次握手和http过程
- AutoPostBack通过现象看本质
- c# in deep 之LINQ读取xml(2)
- attach
- C#学习笔记-状态模式
- Java并发编程阅读笔记-锁和活跃性问题
- Linux官方源、镜像源汇总
- es6学习笔记一:迭代器和for-of循环
- PHP伪造referer突破网盘禁止外链(附115源码)
- [No0000117]visual studio 调试WebForm 显示 HTTP Error 403.14 - Forbidden Web 服务器被配置为不列出此目录的内容。
- day 71-72 cookie 和session
- 在CentOS7.4上手动编译安装Mysql-5.7.20
- spring mvc项目中导出excel表格简单实现
- AMR格式语音采集/编码/转码/解码/播放