Error response:/usr/bin/tf_serving_entrypoint.sh: line 3: 6 Illegal instruction (core dumped) ...
用docker部署tensorflow-serving:gpu时,参照官方文档:https://tensorflow.google.cn/tfx/serving/docker
本应该是很简单的部署,没想到会一直出现这个错误:

经过github和网上的一个朋友了解到,关键问题可能是服务器机器的cpu比较弱(原来是我的cpu确实比较弱:我是在服务器分出来的一个虚拟机上部署的,本质是一个虚拟机,不是一个实体机。)
我的解决方式:将虚拟机更换为实体机,从服务器上直接分出一块CPU供部署使用,然后就解决了这个问题。

疑问:从github中的那位朋友下面的描述看出,即使不更换cpu,似乎也能从别的方法来解决这个问题:我们上面的部署是直接pull 镜像: docker pull tensorflow/serving:latest-gpu
我是通过github文档中获取的方法:https://github.com/tensorflow/serving/blob/master/tensorflow_serving/tools/docker/Dockerfile.gpu
不是直接拉取 tensorflow/serving:latest-gpu这个镜像文件,而是通过Dockerfile.gpu,自己"做"一个镜像文件,然后拉取
1.Clone the TensorFlow Serving project
git clone https://github.com/tensorflow/serving
cd serving
2.Build an image with an optimized ModelServer
For CPU: docker build --pull -t $USER/tensorflow-serving-devel \
-f tensorflow_serving/tools/docker/Dockerfile.devel .
For GPU: docker build --pull -t $USER/tensorflow-serving-devel-gpu \
-f tensorflow_serving/tools/docker/Dockerfile.devel-gpu .
3.Build a serving image with the development image as a base
For CPU: docker build -t $USER/tensorflow-serving \
--build-arg TF_SERVING_BUILD_IMAGE=$USER/tensorflow-serving-devel \
-f tensorflow_serving/tools/docker/Dockerfile .
For GPU: docker build -t $USER/tensorflow-serving-gpu \
--build-arg TF_SERVING_BUILD_IMAGE=$USER/tensorflow-serving-devel-gpu \
-f tensorflow_serving/tools/docker/Dockerfile.gpu . # Your new optimized Docker image is now$USER/tensorflow-serving-gpu, which you can use just as you would the standardtensorflow/serving:latest-gpuimage.
注意:Dockerfile.gpu这个文件里:要注意里面的CUDA,cuDNN,tensorRT,MODEL_NAME,BASE_PATH_MODEL等这些参数要一一对应好(在服务器上安装好)
第2步和第3步的时间比较长,需要耐心等待一下。
然后执行:
sudo docker image ls
就可以查看到新拉取的镜像信息:$USER/tensorflow/serving-gpu:latest 大小为2.4G左右吧(我用的是这个)
然后打开容器:
docker run --runtime=nvidia -p 8501:8501 \
--mount type=bind,\
source=/tmp/tfserving/serving/tensorflow_serving/servables/tensorflow/testdata/saved_model_half_plus_two_gpu,\
target=/models/half_plus_two \
-e MODEL_NAME=half_plus_two -t tensorflow/serving:latest-gpu & 注意:我标红的镜像要修改了,改为:$USER/tensorflow/serving-gpu:latest(每个人不一样)
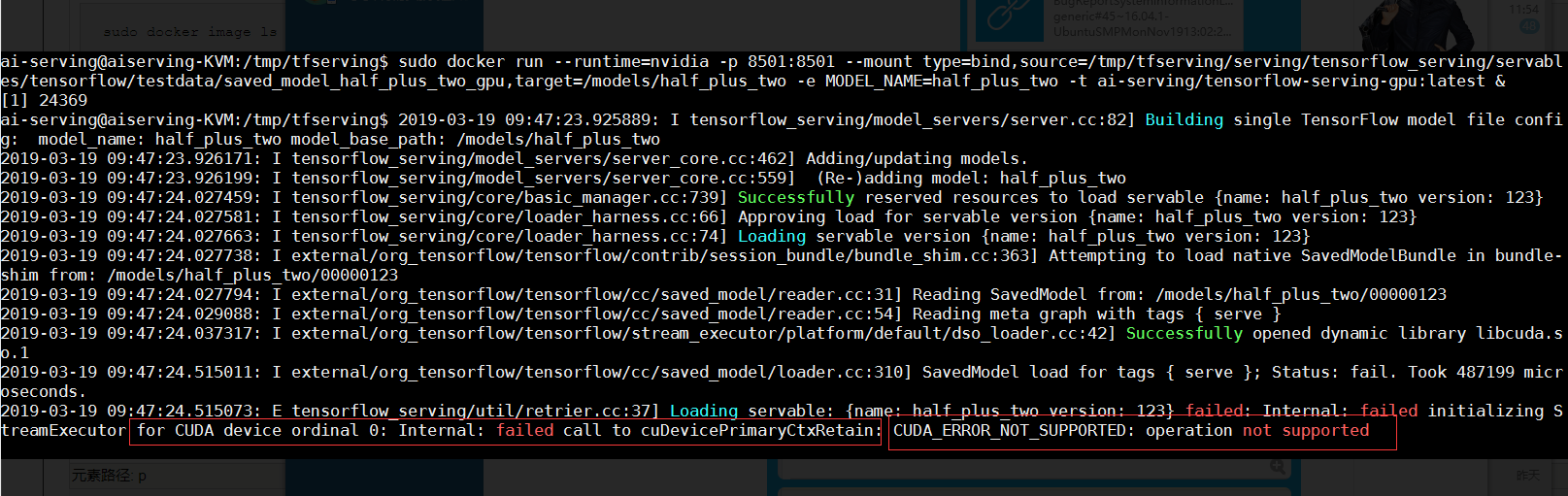
然后执行之后,显示模型获取成功了,但是出现了关于CUDA的一些问题,其实这个问题我到现在还没有解决,然后哪位朋友知道了这个如何解决,能不能告诉我一下,在下方留言和我说说呗。
最新文章
- Azure File Storage 基本用法 -- Azure Storage 之 File
- wf(五)
- 【Cocos2d-x 3.x】 精灵帧缓存和纹理缓存
- [译] OpenStack Kilo 版本中 Neutron 的新变化
- Javascript:常用函数封装
- php对提交数据的验证
- USB模式安装CentOS6.4_minimal
- A simple test
- applet部署,无需修改客户端设置。
- iOS runtime的应用实例
- axis2 和 xfire 接口调用问题排查
- 大话Python中*args和**kargs的使用
- php怎么返回json格式的数据
- (WCF初体验)WCF的认证和消息保护
- C. Queen Codeforces Round #549 (Div. 2) dfs
- python列表的常用方法
- ViewPager防止Fragment销毁以及取消Fragment的预加载
- pandas数据操作
- JS实现获取当前URL和来源URL的方法
- Miller_Rabin(米勒拉宾)素数测试算法