kmp--考研写法
首先是模式串匹配:
#include<iostream>
#include<stdlib.h>
using namespace std;
#define maxn 1000000
struct str
{
char *ch;
int length;
}a,b;
int lower(str a, str b)
{ int i=1,j=1;
int k=0; while(i<=a.length&&j<=b.length)
{
if(a.ch[i]==b.ch[j])
{
i++;
j++;
}
else
{
i=++k;
j=1;
}
}
if(j>b.length)
return k;
else
return 0; }
int main()
{ cin>>a.length;
a.ch=(char*)malloc((a.length+1)*sizeof(char));
for(int i=1;i<=a.length;i++)
cin>>a.ch[i];
cin>>b.length;
b.ch=(char*)malloc((b.length+1)*sizeof(char));
for(int i=1;i<=5;i++)
cin>>b.ch[i];
if(lower(a,b)!=0)
cout<< lower(a, b)<<endl;
else
cout<<"no match"<<endl;
free(a.ch);
free(b.ch); return 0;
}
malloc :
数组=(类型*)malloc(数组大小*sizeof(类型));
free(数组);
例如:
a.ch=(char*)malloc((a.length+1)*sizeof(char));
free(b.ch);
为什么不用2个for。然后不匹配break呢?
因为更好改kmp,而且更防止老师眼睛一累以为你瞎搞,批错了了。
然后 这个算法的复杂度是o(m^n);
我们需要一个更快的算法——kmp
我们来看一个例子:例子别的博主那里偷一下吧。
abcaabababaa和abab
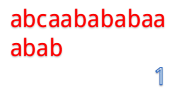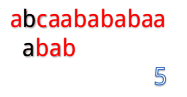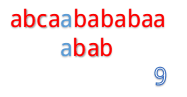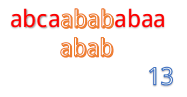
但是我们发现这样匹配很浪费!
为什么这么说呢,我们看到第4步: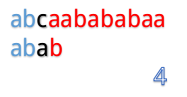
在第4步的时候,我们发现第3位上c与a不匹配,然后第五步的时候我们把B串向后移一位,再从第一个开始匹配。
这里就有一个对已知信息很大的浪费,因为根据前面的匹配结果,我们知道B串的前两位是ab,所以不管怎么移,都是不能和b匹配的,所以应该直接跳过对A串第二位的匹配,对于A串的第三位也是同理
许这这个例子还不够经典,我们再举一个。
A=”abbaabbbabaa”
B=”abbaaba”
在这个例子中,我们依然从第1位开始匹配,直到匹配失败:
abbaabbbabba
abbaaba
我们发现第7位不匹配
那么我们若按照原来的方式继续匹配,则是把B串向后移一位,重新从第一个字符开始匹配
abbaabbbabba
_abbaaba
依然不匹配,那我们就要继续往后移咯。
且住!
既然我们已经匹配了前面的6位,那么我们也就知道了A串这6位和B串的前6位是匹配的,我们能否利用这个信息来优化我们的匹配呢?
也就是说,我们能不能在上面匹配失败后直接跳到:
abbaabbbabba
____abbaaba
这样就可以省去很多不必要的匹配
我们把这个状态叫做s状态跳转到 s1 状态;
怎么跳呢。这时候我们需要一个f数组;
f数组
在模式串j处发生了不匹配,只需将f前移使fL和fR重合即可;
1 f为模式串中j之前的子串
2fL和fR
fL 为f左端的一个子串 fR为右端的一个子串

另外要取最长的fL和fR;
下一个状态是这个
abababab
abababab
如果不取最长的会造成
abababab
abababab
直接冲s状态跳到了s2,漏掉了s1状态。
好了怎么求f呢。暴力。开个玩笑。那怎么能叫kmp呢。了解kmp的同学都知道kmp有个next数组。

这是手工求发适用于:考研选择题
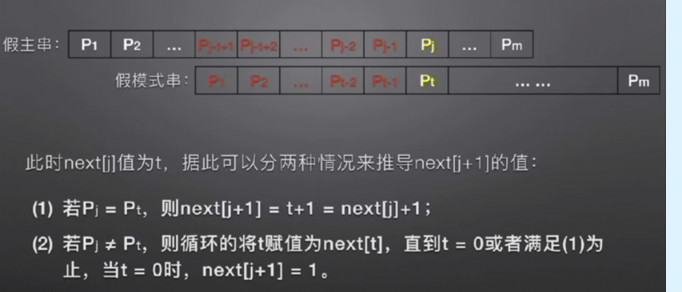
我们是不是一次一次遍历下去的呢,每一次求next[j]都已经把next[j]以前的都处理好了呢。
之前说了 暴力那想写很容易改。那么我们怎么改呢:
int kmp(str a, str b)
{ int i=1,j=1;
//int k=0; while(i<=a.length&&j<=b.length)
{
if(a.ch[i]==b.ch[j]&&j==0)//j==0加进来
{
i++;
j++;
}
else
{
//i=++k;我们都知道kmpn不需要i回溯。
j=next[j];//j=1;跳转到next,用next转移;
}
}
if(j>b.length)
return i-b.length; //return k;
else
return 0; }
那么我们还差一个next
void getnext()
{
int i=1;
nxt[1]=0;
int j=0; while(i<b.length)
{
if(j==0||b.ch[i]==b.ch[j])
{
++i;
++j;
nxt[i]=j;
}
else
j=nxt[j];
} }
合起来就是
#include<iostream>
#include<stdlib.h>
#include <cstdio>
#include <fstream>
using namespace std;
#define maxn 1000000
struct str
{
char *ch;
int length;
}a,b;
int nxt[maxn];
void getnext()
{
int i=1;
nxt[1]=0;
int j=0; while(i<b.length)
{
if(j==0||b.ch[i]==b.ch[j])
{
++i;
++j;
nxt[i]=j;
}
else
j=nxt[j];
} }
int kmp(str a, str b)
{ int i=1,j=1;
//int k=0; while(i<=a.length&&j<=b.length)
{
if(a.ch[i]==b.ch[j]&&j==0)//j==0加进来
{
i++;
j++;
}
else
{
//i=++k;我们都知道kmpn不需要i回溯。
j=nxt[j];//j=1;
}
}
if(j>b.length)
return i-b.length; //return k;
else
return 0; }
int main()
{ cin>>a.length;
a.ch=(char*)malloc((a.length+1)*sizeof(char));
for(int i=1;i<=a.length;i++)
cin>>a.ch[i];
cin>>b.length;
b.ch=(char*)malloc((b.length+1)*sizeof(char));
getnext();
for(int i=1;i<=b.length;i++)
cin>>b.ch[i];
if(kmp(a,b)!=0)
cout<< kmp(a, b)<<endl;
else
cout<<"no match"<<endl;
free(a.ch);
free(b.ch); return 0;
}
最后我们看到这个
kmp的这里。

他需要不断的跳。其实,我们改进。跳的时候相同,必不可能是当前位子

#include<iostream>
#include<stdlib.h>
#include <cstdio>
#include <fstream>
using namespace std;
#define maxn 1000000
struct str
{
char *ch;
int length;
}a,b;
int nextval[maxn];
void getnextval()
{
int i=1;
nextval[1]=0;
int j=0; while(i<b.length)
{
if(j==0||b.ch[i]==b.ch[j])
{
++i;
++j;
if (b.ch[i]!=b.ch[j]){
nextval[i]=j;
}
else
{
nextval[i]=nextval[j];
}
}
else
j=nextval[j];
} }
int kmp(str a, str b)
{ int i=1,j=1;
//int k=0; while(i<=a.length&&j<=b.length)
{
if(a.ch[i]==b.ch[j]&&j==0)//j==0加进来
{
i++;
j++;
}
else
{
//i=++k;我们都知道kmpn不需要i回溯。
j=nextval[j];//j=1;
}
}
if(j>b.length)
return i-b.length; //return k;
else
return 0; }
int main()
{ cin>>a.length;
a.ch=(char*)malloc((a.length+1)*sizeof(char));
for(int i=1;i<=a.length;i++)
cin>>a.ch[i];
cin>>b.length;
b.ch=(char*)malloc((b.length+1)*sizeof(char));
getnextval();
for(int i=1;i<=b.length;i++)
cin>>b.ch[i];
if(kmp(a,b)!=0)
cout<< kmp(a, b)<<endl;
else
cout<<"no match"<<endl;
free(a.ch);
free(b.ch); return 0;
}
最新文章
- Automated Memory Analysis
- 一、OWIN初探
- js将json字符串转化成json对象的方法
- 浏览器中Javascript的加载和执行
- ArrayBlockingQueue-我们到底能走多远系列(42)
- Excel的一些常用设置
- Android多分辨率适配经验总结
- Zabbix的LLD功能--Low-level discovery
- 部署ASP.Net项目 遇到总是启用目录浏览或者报HTTP 错误 403.14 - Forbidden 的原因
- bzoj3129[Sdoi2013]方程 exlucas+容斥原理
- Java-获取年月日对应的天干地支
- Navicat Premium 12.1.12.0安装与激活
- Visual Studio 2013 突然不高亮,编译报错
- CentOS7下安装Python3并保留Python2
- ProtoBuf使用指南(C++)
- HTML5仿微信公众号界面
- Matlab Gauss quadrature
- ProtoBuf 常用序列化/反序列化API 转
- Linux文件系统命令 touch/rm
- 安装的Android SDK下无doc文件夹问题 以及关联Android帮助文档和查看文档 以及查看在线文档
热门文章
- salesforce零基础学习(一百)Mobile Device Tracking
- Sentry(v20.12.1) K8S 云原生架构探索,JavaScript Enriching Events(丰富事件信息)
- 请不要继续将数据库称为 CP 或 AP - 掘金 https://juejin.im/post/6844903878102614030
- 2.kafka架构深入——生产者
- 获取控制台的错误信息 onerror
- Privacy-Enhanced Mail (PEM) Privacy Enhancement for Internet Electronic Mail
- EF Code First 无法加载指定的元数据资源
- 配置《Orange's一个操作系统的实现》环境心得
- Centos7部署FytSoa项目至Docker——第一步:安装Docker
- Prometheus+Grafana监控SpringBoot