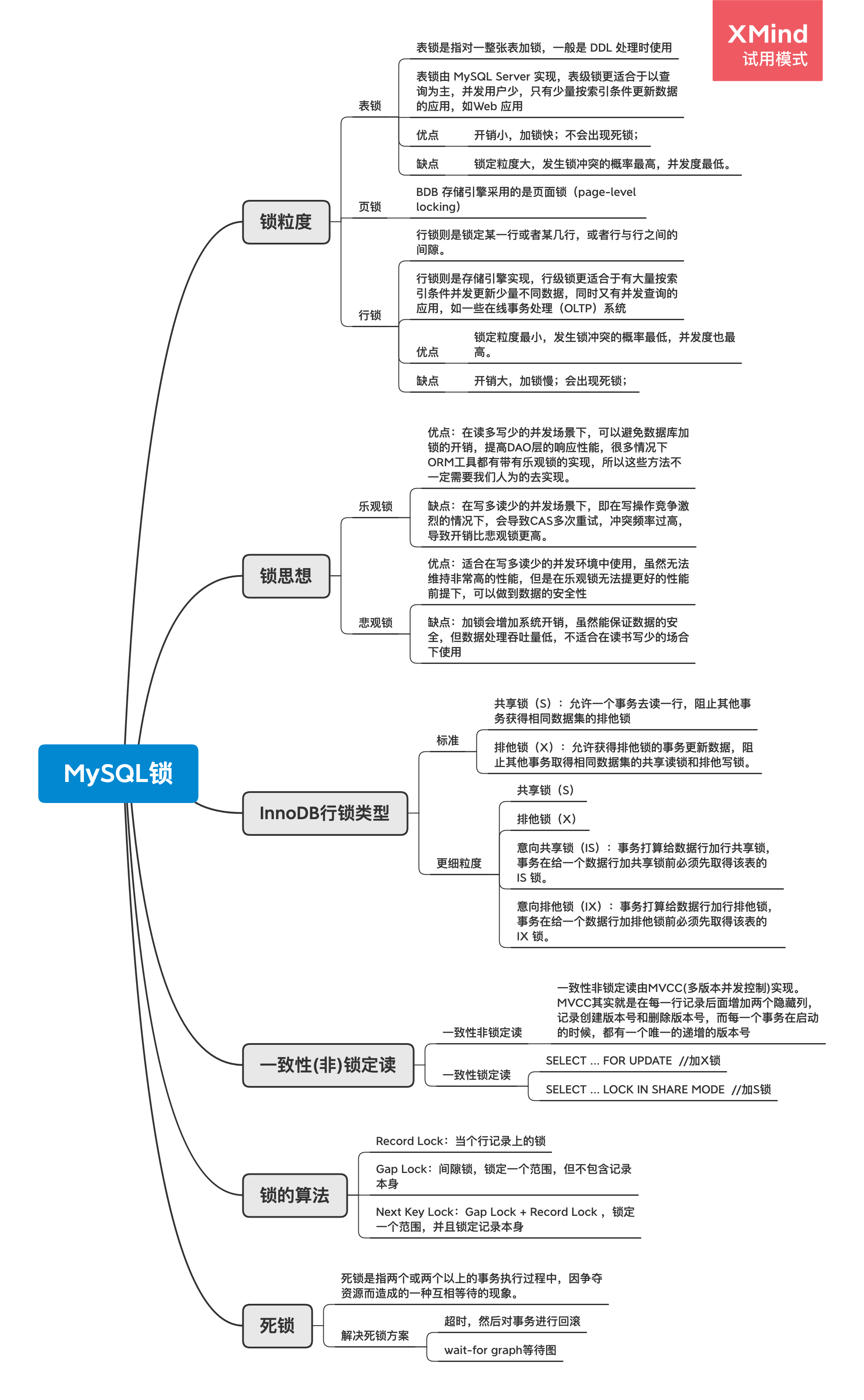
深入理解MySQL系列之锁
按锁思想分类
- 悲观锁
- 优点:适合在写多读少的并发环境中使用,虽然无法维持非常高的性能,但是在乐观锁无法提更好的性能前提下,可以做到数据的安全性
- 缺点:加锁会增加系统开销,虽然能保证数据的安全,但数据处理吞吐量低,不适合在读书写少的场合下使用
- 乐观锁
- 优点:在读多写少的并发场景下,可以避免数据库加锁的开销,提高DAO层的响应性能,很多情况下ORM工具都有带有乐观锁的实现,所以这些方法不一定需要我们人为的去实现。
- 缺点:在写多读少的并发场景下,即在写操作竞争激烈的情况下,会导致CAS多次重试,冲突频率过高,导致开销比悲观锁更高。
- 实现:数据库层面的乐观锁其实跟CAS思想类似, 通数据版本号或者时间戳也可以实现。
按锁粒度分类
- 表锁
表锁是指对一整张表加锁,一般是 DDL 处理时使用
表锁由 MySQL Server 实现,表级锁更适合于以查询为主,并发用户少,只有少量按索引条件更新数据的应用,如Web 应用
- 优点:开销小,加锁快;不会出现死锁;
- 缺点:锁定粒度大,发生锁冲突的概率最高,并发度最低。
页锁:介于表锁和行锁之间。BDB 存储引擎采用的是页面锁(page-level locking)
行锁
行锁则是锁定某一行或者某几行,或者行与行之间的间隙。
行锁则是存储引擎实现,行级锁更适合于有大量按索引条件并发更新少量不同数据,同时又有并发查询的应用,如一些在线事务处理(OLTP)系统
- 优点:锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
- 缺点:开销大,加锁慢;会出现死锁;
InnoDB行锁类型
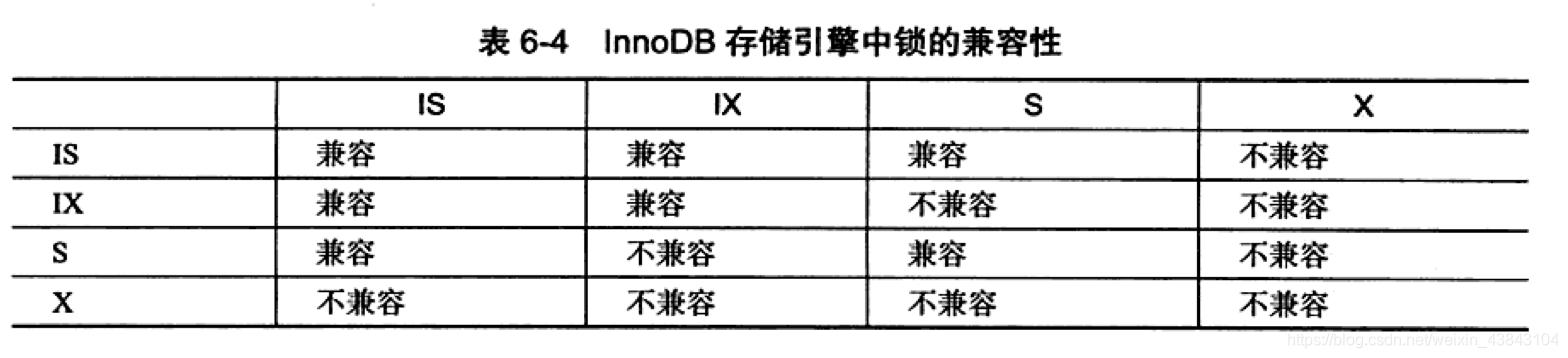
- 标准
- 共享锁(S):允许一个事务去读一行,阻止其他事务获得相同数据集的排他锁
- 排他锁(X):允许获得排他锁的事务更新数据,阻止其他事务取得相同数据集的共享读锁和排他写锁。

数据库并发场景主要有三种:
- 读-读:不存在任何问题,也不需要并发控制
- 读-写:有隔离性问题,可能遇到脏读,幻读,不可重复读
- 写-写:可能存更新丢失问题,比如第一类更新丢失,第二类更新丢失
- 更细粒度
- 共享锁(S)
- 排他锁(X)
- 意向共享锁(IS):事务打算给数据行加行共享锁,事务在给一个数据行加共享锁前必须先取得该表的 IS 锁。
- 意向排他锁(IX):事务打算给数据行加行排他锁,事务在给一个数据行加排他锁前必须先取得该表的 IX 锁。
一致性(非)锁定读
一致性非锁定读:
一致性非锁定读由MVCC(多版本并发控制)实现。MVCC其实就是在每一行记录后面增加两个隐藏列,记录创建版本号和删除版本号,而每一个事务在启动的时候,都有一个唯一的递增的版本号
详细可参考前文《深入理解MySQL系列之redo log、undo log和binlog》
一致性锁定读:
SELECT ... FOR UPDATE //加X锁
SELECT ... LOCK IN SHARE MODE //加S锁
锁的算法
行锁的三种算法:
- Record Lock:当个行记录上的锁
- Gap Lock:间隙锁,锁定一个范围,但不包含记录本身
- Next Key Lock:Gap Lock + Record Lock ,锁定一个范围,并且锁定记录本身(只有REPEATABLE READ隔离级别有)
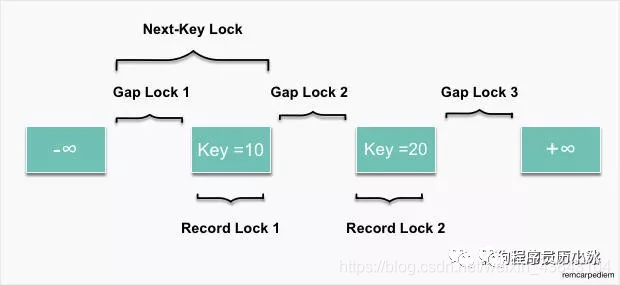
在默认事务隔离级别(REPEATABLE READ)下,InnoDB采用Next Key Lock解决幻读(Phantom Problem)。对一个范围加X锁,从而这个范围不允许插入,所以避免了幻读。
此外,还可以用Next key lock实现唯一性检查。如下,用户通过索引查询一个值,并对该行加一个S Lock;如果行不存在,锁定一个范围,新插入值也是唯一的。
SELECT * FROM TABLE WHERE COL = xxx LOCK IN SHARE MODE;
// 如果没有找到任何行
INSERT INTO TABLE VALUES(...)

间隙锁加锁原则:
- 1、加锁的基本单位是 NextKeyLock,是前开后闭区间。
- 2、查找过程中访问到的对象才会加锁。
- 3、索引上的等值查询,给唯一索引加锁的时候,NextKeyLock退化为行锁。
- 4、索引上的等值查询,向右遍历时且最后一个值不满足等值条件的时候,NextKeyLock退化为间隙锁。
- 5、唯一索引上的范围查询会访问到不满足条件的第一个值为止。
自增锁
AUTOINC 锁又叫自增锁(一般简写成 AI 锁),是一种表锁,当表中有自增列(AUTOINCREMENT)时出现。
当插入表中有自增列时,数据库需要自动生成自增值,它会先为该表加 AUTOINC 表锁,阻塞其他事务的插入操作,这样保证生成的自增值肯定是唯一的。AUTOINC 锁具有如下特点:
AUTO_INC 锁互不兼容,也就是说同一张表同时只允许有一个自增锁;
自增值一旦分配了就会 +1,如果事务回滚,自增值也不会减回去,所以自增值可能会出现中断的情况。
显然,AUTOINC 表锁会导致并发插入的效率降低,为了提高插入的并发性,MySQL 从 5.1.22 版本开始,引入了一种可选的轻量级锁(mutex)机制来代替 AUTOINC 锁,可以通过参数 innodbautoinclockmode 来灵活控制分配自增值时的并发策略。具体可以参考 MySQL 的 AUTOINCREMENT Handling in InnoDB 一文
死锁
概念:死锁是指两个或两个以上的事务执行过程中,因争夺资源而造成的一种互相等待的现象。
- 解决死锁第一种方法:超时,然后对事务回滚
缺点:若超时的事务所占权重比较大,如事务更新了很多行,占用了较多的undo log,这时采用FIFO方式就不合适了,因为回滚这个事务的时间相对另一个事务所占用的时间可能会多很多。
- wait-for graph等待图方式进行死锁检测
InnoDB采用的方式。
wait-for graph要求数据库保存两种信息,通过下面两个链表构造出一张图,如果这个图中存在回路,就代表存在死锁,因此资源间发生相互等待。
- 锁的信息链表
- 事务等待链表
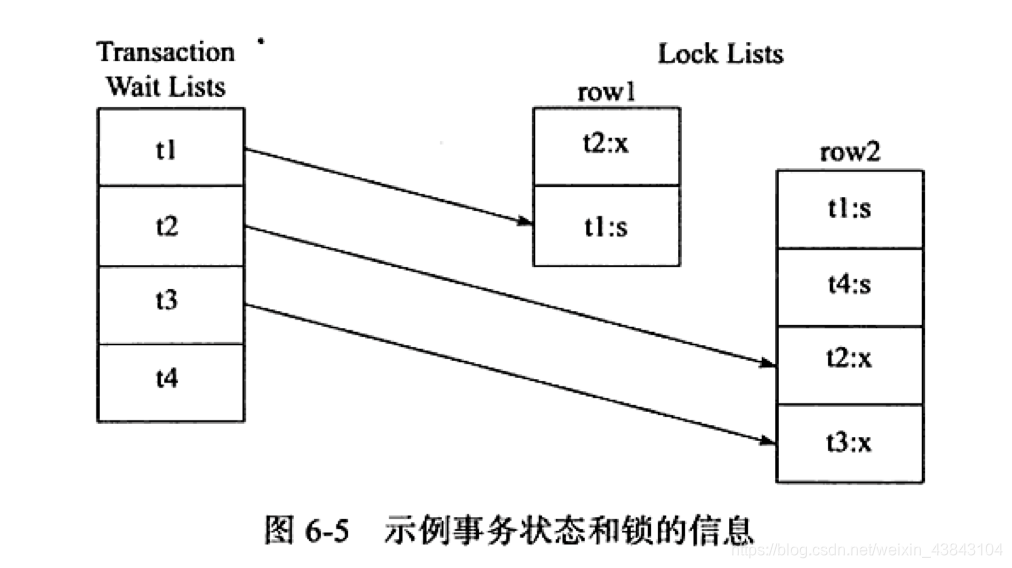
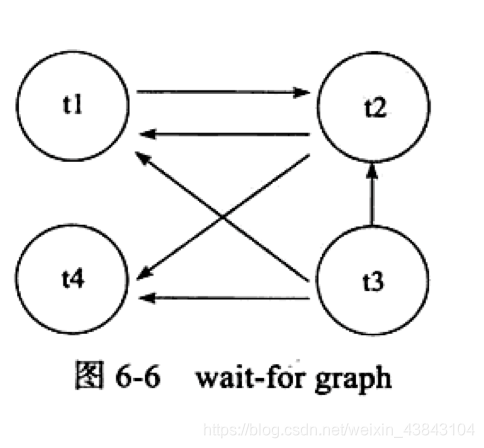
如下图示例,事务等待链表有4个事务,而右边锁信息链表中,row1中事务t1要等待事务t2资源,所以在下wait-for graph图中就有一条t1指向t2的箭头;而row2中tt2、t3需要等待t1中占用row2资源,故t2、t3各有个箭头指向t1(t1、t4两个S锁兼容)。依次最后得到下面的图。
可以发现(t1, t2)存在回路,因此存在死锁。
所以wait-for graph是一种主动的死锁检查机制,若存在死锁,选择回滚undo量最小的事务。(wait-for graph采用图的深度优先算法)
参考:
《MySQL技术内幕》
https://mp.weixin.qq.com/s/PPfXH9a3jlNyxXpwB_DZDg
https://zhuanlan.zhihu.com/p/29150809
最新文章
- Html5选择本地视频音频文件播放
- C++ 回调函数 实现 的测试代码
- xcodebuild
- 在ASP.NET中上传附件
- Flex xml编辑器(老外写的)
- Install ssdb-rocks on CentOS 6
- 2-sat(and,or,xor)poj3678
- QCon2013上海站总结 -- 整体印象和感悟
- Fedora 20下安装官方JDK替换OpenJDK并配置环境变量
- 分享一个数据库工具DTOOLS
- UEditor富文本简单使用
- WPF 格式化输出- IValueConverter接口的使用 datagrid列中的值转换显示
- 10.17小结:table.copy() 和 distinct 查询
- keepalived weight正负值问题(实现主服务器nginx故障后迅速切换到备服务器)
- django日志配置
- Java基本语法知识要点
- wmware 10 升级到11后,macos不能运行的问题
- 115个Java面试题和答案(上)
- The capacitive screen technology - tadpole
- win7 QT +opencv环境搭建