copy,集合
2024-09-06 07:06:54
一、基础数据类型补充:

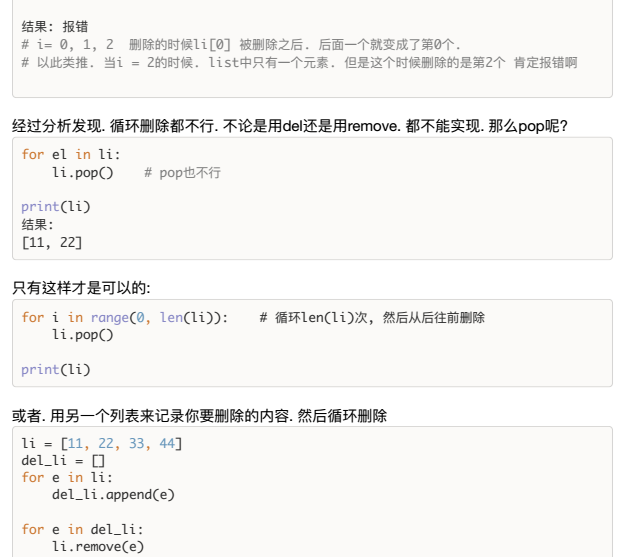


1种方法:删除列表里面的元素时,一定不能循环列表,会出错。可以循环索引,然后循环删除开头或结尾这个位置的元素(原开头结尾的元素被删除之后,会有新的元素顶上来)。
2种方法:把要删除的元素放在一个新列表中,然后循环新列表,删除老列表。(循环过称中元素索引并没有发生变化,所以不会出错)

二、集合:
集合是无序的,不重复的数据集合,它里面的元素是可哈希的(不可变类型),但是集合本身是不可哈希(所以集合做不了字典的键)的。以下是集合最重要的两点:
去重,把一个列表变成集合,就自动去重了。
关系测试,测试两组数据之前的交集、差集、并集等关系。
1,集合的创建。
set1 = set({1,2,'barry'})
set2 = {1,2,'barry'}
print(set1,set2) # {1, 2, 'barry'} {1, 2, 'barry'}
2,集合的增。

set1 = {'alex','wusir','ritian','egon','barry'}
set1.add('景女神')
print(set1)
#update:迭代着增加
set1.update('A')
print(set1)
set1.update('老师')
print(set1)
set1.update([1,2,3])
print(set1)
3,集合的删。
set1 = {'alex','wusir','ritian','egon','barry'}
set1.remove('alex') # 删除一个元素
print(set1)
set1.pop() # 随机删除一个元素
print(set1)
set1.clear() # 清空集合
print(set1)
del set1 # 删除集合
print(set1)
集合的改:先删后增 remove =》 add
集合的查: for循环 for i(变量) in set1(集合)
4,集合的其他操作:
4.1 交集。(& 或者 intersection)
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 & set2) # {4, 5}
print(set1.intersection(set2)) # {4, 5}
4.2 并集。(| 或者 union)
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 | set2) # {1, 2, 3, 4, 5, 6, 7}
print(set2.union(set1)) # {1, 2, 3, 4, 5, 6, 7}
4.3 差集。(- 或者 difference)
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 - set2) # {1, 2, 3}
print(set1.difference(set2)) # {1, 2, 3}
4.4反交集。 (^ 或者 symmetric_difference)
set1 = {1,2,3,4,5}
set2 = {4,5,6,7,8}
print(set1 ^ set2) # {1, 2, 3, 6, 7, 8}
print(set1.symmetric_difference(set2)) # {1, 2, 3, 6, 7, 8}
4.5子集与超集
set1 = {1,2,3}
set2 = {1,2,3,4,5,6}
print(set1 < set2)
print(set1.issubset(set2)) # 这两个相同,都是说明set1是set2子集。
print(set2 > set1)
print(set2.issuperset(set1)) # 这两个相同,都是说明set2是set1超集。
5,frozenset不可变集合,让集合变成不可变类型。
s = frozenset('barry')
print(s,type(s)) # frozenset({'a', 'y', 'b', 'r'}) <class 'frozenset'>
三、深浅copy
1,先看赋值运算。
l1 = [1,2,3,['barry','alex']]
l2 = l1 l1[0] = 111
print(l1) # [111, 2, 3, ['barry', 'alex']]
print(l2) # [111, 2, 3, ['barry', 'alex']] l1[3][0] = 'wusir'
print(l1) # [111, 2, 3, ['wusir', 'alex']]
print(l2) # [111, 2, 3, ['wusir', 'alex']]
对于赋值运算来说,l1与l2指向的是同一个内存地址,所以他们是完全一样的。
2,浅拷贝copy。
l1 = [1,2,3,['barry','alex']]
l2 = l1.copy()
print(l1,id(l1)) # [1, 2, 3, ['barry', 'alex']] 2380296895816
print(l2,id(l2)) # [1, 2, 3, ['barry', 'alex']] 2380296895048
l1[1] = 222
print(l1,id(l1)) # [1, 222, 3, ['barry', 'alex']] 2593038941128
print(l2,id(l2)) # [1, 2, 3, ['barry', 'alex']] 2593038941896
l1[3][0] = 'wusir'
print(l1,id(l1[3])) # [1, 2, 3, ['wusir', 'alex']] 1732315659016
print(l2,id(l2[3])) # [1, 2, 3, ['wusir', 'alex']] 1732315659016
对于浅copy来说,第一层创建的是新的内存地址,而从第二层开始,指向的都是同一个内存地址,所以,对于第二层以及更深的层数来说,保持一致性。
3,深拷贝deepcopy。
import copy
l1 = [1,2,3,['barry','alex']]
l2 = copy.deepcopy(l1) print(l1,id(l1)) # [1, 2, 3, ['barry', 'alex']] 2915377167816
print(l2,id(l2)) # [1, 2, 3, ['barry', 'alex']] 2915377167048 l1[1] = 222
print(l1,id(l1)) # [1, 222, 3, ['barry', 'alex']] 2915377167816
print(l2,id(l2)) # [1, 2, 3, ['barry', 'alex']] 2915377167048 l1[3][0] = 'wusir'
print(l1,id(l1[3])) # [1, 222, 3, ['wusir', 'alex']] 2915377167240
print(l2,id(l2[3])) # [1, 2, 3, ['barry', 'alex']] 2915377167304
对于深copy来说,两个是完全独立的,改变任意一个的任何元素(无论多少层),另一个绝对不改变。
最新文章
- 从零开始编写自己的C#框架(14)——T4模板在逻辑层中的应用(三)
- 用Kotlin改写PHP程序是什么样的体验
- Javascript中数组方法和方法的扩展
- linux 64位调用
- JVM的生命周期
- HtmlAgilityPack.dll的使用 获取HTMLid
- Android中表示尺寸的六种度量单位
- [USACO10MAR]伟大的奶牛聚集
- VMware设置虚拟机,并配置远程连接桌面
- Android用户界面概览
- springMVC之本地化和国际化
- js原生forEach、map与jquery的each、$.each的区别
- hdu3974(线段树+dfs)
- Linux生成动态库系统
- mysql 计算两点经纬度之间的直线距离(具体sql语句)
- Oracle18c Exadata 版本安装介质安装失败。
- ipv6地址管理
- 【最大连接数】Linux的文件最大连接数
- bzoj1704 / P2882 [USACO07MAR]面对正确的方式Face The Right Way
- ArcGIS按字段属性分割文件
热门文章
- 高端面试必备:一个Java对象占用多大内存
- ExecutionListener,TaskListener流程监听 和任务监听
- [LeetCode]547. Friend Circles朋友圈数量--不相邻子图问题
- Linux嵌入式学习-交叉编译openssl
- [Deep Learning] 神经网络编程基础 (Basics of Neural Network Programming) - 逻辑回归-梯度下降-计算图
- JavaDailyReports10_15
- 学习DOS,个人笔记
- Mysql大概1700W大表删除1000W左右数据,发现数据大小和索引大小并没有减少思考
- Spring Boot 2.x基础教程:实现文件上传
- 风炫安全web安全学习第三十节课 命令执行&代码执行基础