python_非阻塞套接字及I/O流
http://www.cnblogs.com/lixy-88428977/p/9638949.html
首先,我们要明确2个问题:
普通套接字实现的服务端有什么缺陷吗?
有,一次只能服务一个客户端!
这种缺陷是如何造成的?
accept阻塞:当没有套接字连接请求过来的时候会一直等待着
recv阻塞:当连接的这个客户端没有发数据过来的时候,也会一直等待着

import socket server = socket.socket()
server.bind(('127.0.0.1', 8888))
server.listen(5)
print("执行到这, 上面没问题了") while True: conn, addr = server.accept() # 阻塞 print(conn, addr)
print("{}连接".format(addr)) while True:
data = conn.recv(1024) # 阻塞
print(data) if not data:
break
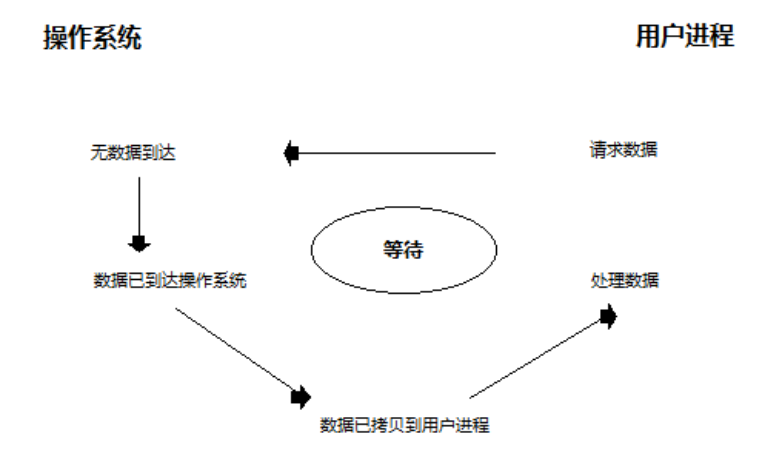
当前I/O流
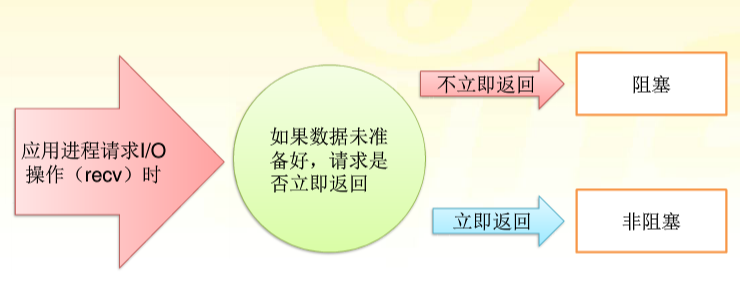
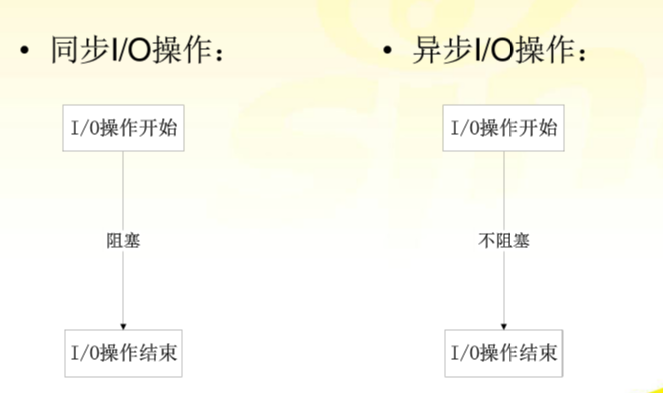
那么非阻塞套接字和普通套接字的区别?
非阻塞套接字在accept或recv的时候不会发生阻塞,要么成功,要么失败抛出BlockingIOError异常


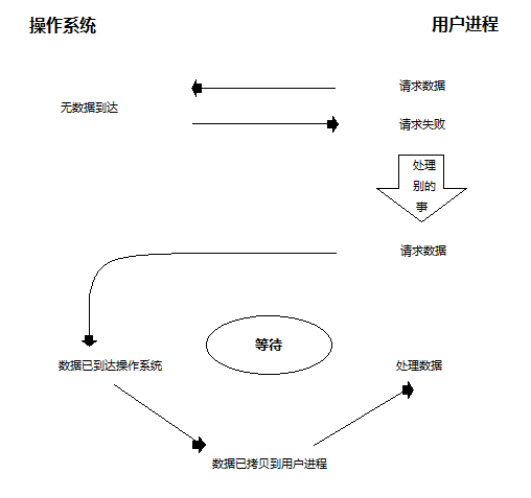
非阻塞IO模型
非阻塞套接字实现并发
并发是什么?
在一个时间段,完成某件事,就是并发
对立的概念,什么是并行?
同时发生,不管有几件事,同时进行,就是并行
非阻塞套接字如何实现并发服务端?
配合try语句,将代码顺序重排,避开阻塞
实现并发服务多个客户端 !
那么现在用非阻塞套接字完善上一章博客的代码:
服务端:
import socket
import time
# 并发操作 server = socket.socket() # 创建一个socket
server.setblocking(False) # 设置成非阻塞
server.bind(('0.0.0.0', 8888))
server.listen()
print("执行到这, 上面没问题了") all_connction = [] # 用来存放和连接客户端通信的套接字
while True:
# 处理用户的连接
try:
conn, addr = server.accept() # 阻塞
conn.setblocking(False) # 设置成非阻塞
print(conn, addr)
print("{}连接".format(addr))
all_connction.append(conn)
except BlockingIOError as e:
pass # 处理已经连接的客户的消息
time.sleep(1)
new_li = all_connction.copy()
for conn in new_li:
try:
data = conn.recv(1024) # 阻塞
if data == b'':
all_connction.remove(conn)
conn.close()
else:
print("接收到的数据: ", data.decode())
conn.send(data) except BlockingIOError as e:
pass server.close()
客户端:
#客户端Linux、window系统下:输入命令通过服务端返回
import socket #声明协议类型,同时生成socket连接对象
client = socket.socket() #链接地址和端口,元组(本地,端口)
client.connect(('127.0.0.1', 8888)) #使用input循环向服务端发送请求
while True: msg = input("-->>:").strip()
if len(msg) == 0:
continue #发送数据 b将字符串转为bys类型
client.send(msg.encode("utf-8")) #接收服务器端的返回,需要声明收多少,默认1024字节
id = 1024
data = client.recv(id).decode() #打印data是recv的data
print("recv: %s" % data) #关闭接口
client.close()
IO多路复用
IO多路复用也是阻塞IO, 只是阻塞的方法是select/poll/epoll, 好处就是单个进程可以处理多个socket
用select,poll,epoll监听多个io对象,当io对象有变化(有数据)的时候,则立即通知相应程序进行读或者写操作。
但select,poll,epoll本质上都是同步I/O,因为他们都需要在读写时间就绪后自己负责进行读写,也就是说这个读写过程是阻塞的
因为阻塞I/O只能阻塞一个I/O操作,而I/O复用模型能够阻塞多个I/O操作, 所以才叫做多路复用
非阻塞套接字实现的服务端还有什么不完美的地方吗?
关键一: 任何操作都是要花CPU资源的!
关键二: 如果数据还没有到达。那么accept, recv操作都是在做无用功!
关键三: 对异常BlockIOError的处理也是在做无用功!
总结:不完美的CPU利用率
I/O多路复用模型

epoll 目前Linux上效率最高的IO多路复用技术!
epoll 基于惰性的事件回调机制
惰性的事件回调是由用户自己调用的,操作系统只起到通知的作用
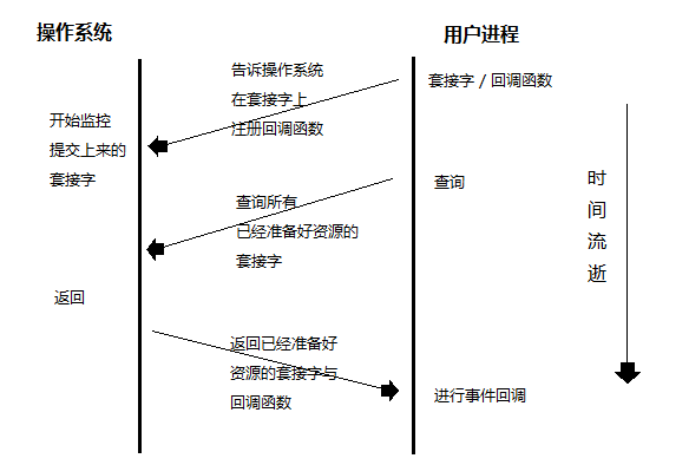
使用步骤
 导入IO多路复用选择器
导入IO多路复用选择器
 注册事件和回调
注册事件和回调
 查询
查询
 回调
回调
应用实例:
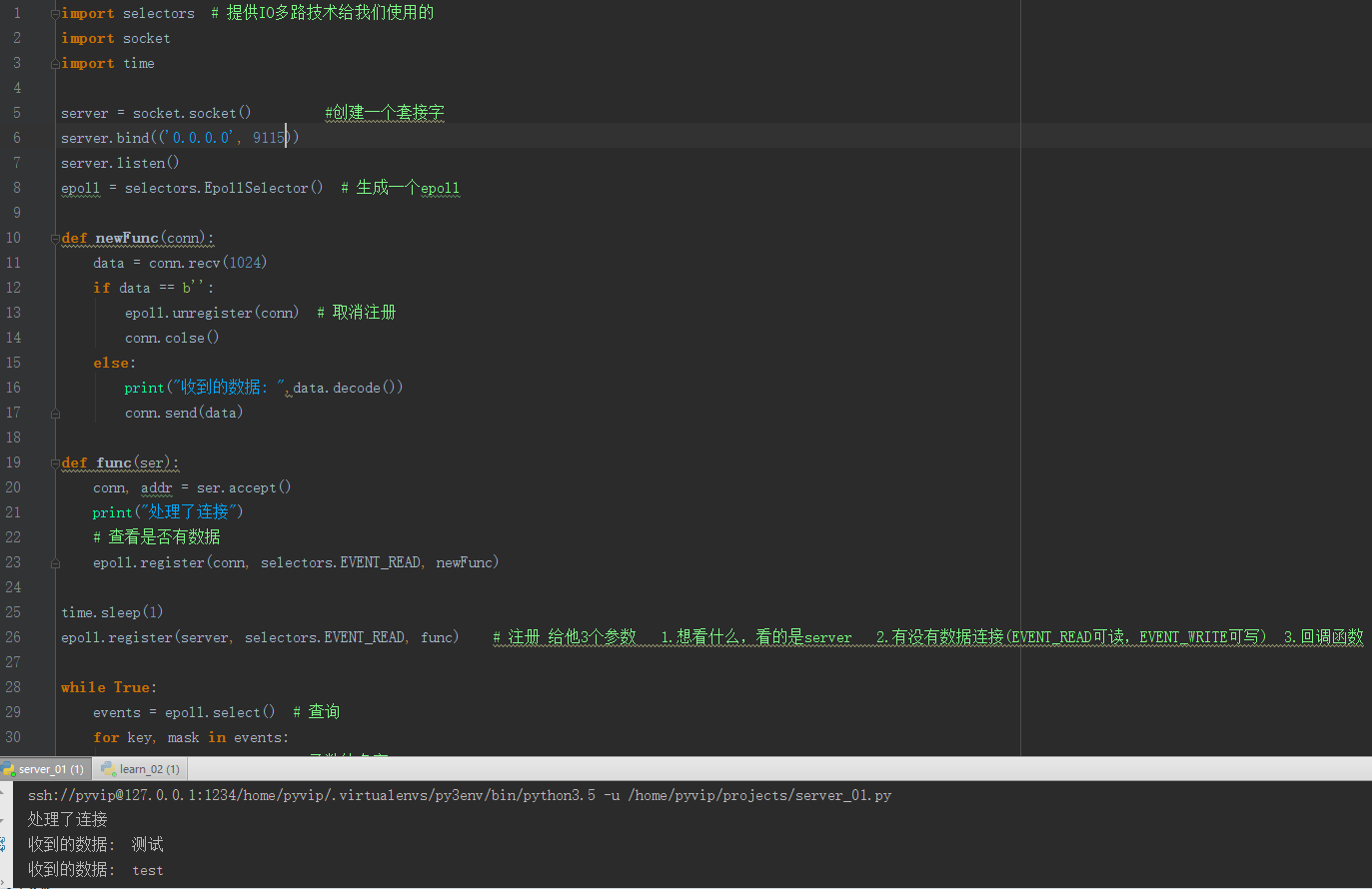
import selectors # 提供IO多路技术给我们使用的
import socket
import time server = socket.socket() #创建一个套接字
server.bind(('0.0.0.0', 8888))
server.listen()
epoll = selectors.EpollSelector() # 生成一个epoll def newFunc(conn):
data = conn.recv(1024)
if data == b'':
epoll.unregister(conn) # 取消注册
conn.colse()
else:
print("收到的数据: ",data.decode())
conn.send(data) def func(ser):
conn, addr = ser.accept()
print("处理了连接")
# 查看是否有数据
epoll.register(conn, selectors.EVENT_READ, newFunc) time.sleep(1)
epoll.register(server, selectors.EVENT_READ, func) # 注册 给他3个参数 1.想看什么,看的是server 2.有没有数据连接(EVENT_READ可读,EVENT_WRITE可写) 3.回调函数 while True:
events = epoll.select() # 查询
for key, mask in events:
callback = key.data # 函数的名字
sock = key.fileobj # 套接字 callback(sock) # 函数调用
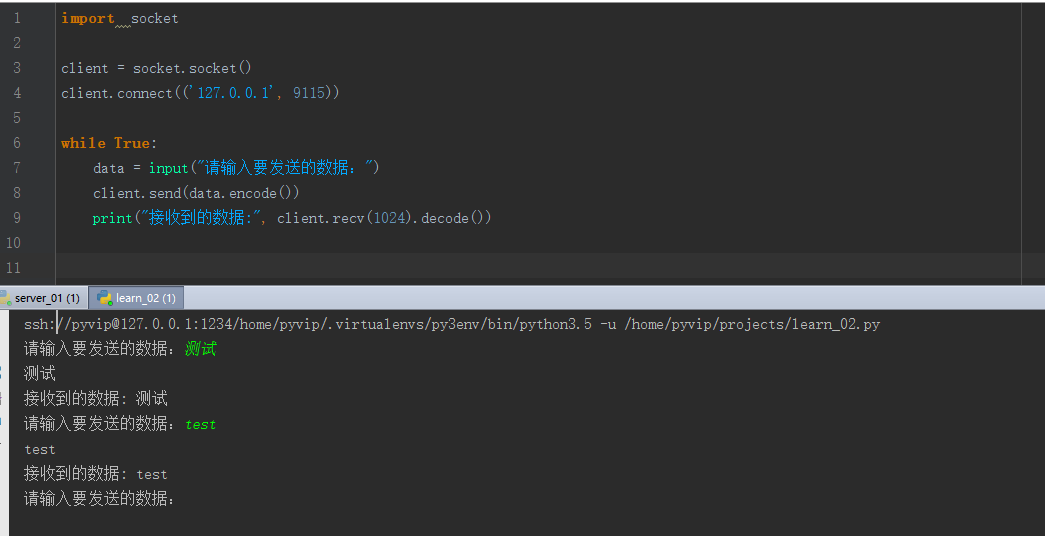
import socket client = socket.socket()
client.connect(('127.0.0.1', 8888)) while True:
data = input("请输入要发送的数据:")
client.send(data.encode())
print("接收到的数据:", client.recv(1024).decode())
下面是一些理论的东西,大家有时间可以读一遍。
## 什么是IO操作
IO在计算机中指Input/Output,也就是输入和输出 。由于程序和运行时数据是放在内存中的,由CPU来执行的,涉及到数据交换的地方,通常是磁盘、网络等,就需要IO接口。
比如你打开浏览器,访问百度,浏览器需要通过网络获取百度的网页数据。浏览器首先发送数据给百度的服务器,告诉它我要访问它,这个过程是往外发数据,就做Output。然后百度服务器在把网页数据发过来。这个过程是从外面接收数据,就做input
所以,通常,程序完成IO操作会有Input和Output 这两个过程, 但是也可能只有一个,比如打开一个文件。就只是从磁盘读取文件到内存,就只有Input操作 ,反过来,向文件中写入数据,就只是一个Output操作。
## 1 流的概念
IO编程中,Stream(流)是一个很重要的概念,可以把流想象成一个水管,数据就是水管里的水,但是只能单向流动。Input Stream就是数据从外面(磁盘、网络)流进内存,Output Stream就是数据从内存流到外面去。对于浏览网页来说,浏览器和百度服务器之间至少需要建立两根水管,才可以既能发数据,又能收数据。
由于CPU和内存的速度远远高于外设的速度,所以,在IO编程中,就存在速度严重不匹配的问题。 可能存在这样的情况:读取数据的时候,流中还没有数据;写入数据的时候,流中数据已经满了,没有空间写入了。
举个例子,socket通信, 通过recv读取另一方发过来的数据,但是对方还没把数据准备好发过来。此时有两种处理办法:
- 阻塞,等待数据准备好了,再读取出来返回;
- 非阻塞,通过轮询的方式,查询是否有数据可以读取,直到把数据读取返回。
## 2. 同步,异步,阻塞, 非阻塞的概念
在IO操作过程中,可能会涉及到同步(synchronous)、异步(asynchronous)、阻塞(blocking)、非阻塞(non-blocking)、IO多路复用(IO multiplexing)等概念。他们之间的区别是什么呢?
以socket为例子,在socket通信过程中,涉及到两个对象:
1. 调用这个IO的进程(process)或线程(thread)
2. 操作系统内核(kernel)
比如服务端调用recv来接收客户端的数据,会涉及两个过程:
1. 等待数据准备好(Waiting for the data to be ready),也就是客户端要通过网络把数据发给服务端;
2. 客户端把数据发送过来,首先会被操作系统内核接收到,程序里面需要使用这个数据,要将数据从内核中拷贝到进程中( Copying the data from the kernel to the process))
根据这两个阶段中,不同阶段是否发生阻塞,将产生不同的效果。
### 阻塞 VS 非阻塞
阻塞IO:
- 在1、2阶段都发生阻塞;
- 调用阻塞IO会一直block住进程,直到操作完成
非阻塞IO:
- 在第1阶段没有阻塞,在第2阶段发生阻塞;
- 当用户进程发出IO请求时, 如果内核中的数据还没由准备好,那么它并不会block用户进程,而是立即返回一个错误, 在程序看来,它发起一个请求后,并不需要等待,而是马上就得到一个结果。
- 非阻塞IO需要不断轮询,查看数据是否已经准备好了;
阻塞与非阻塞可以简单理解为调用一个IO操作能不能立即得到返回应答,如果不能立即获得返回,需要等待,那就阻塞了;否则就可以理解为非阻塞 。
### **同步VS异步**
同步与异步是针对应用程序与内核的交互而言的
同步:第二步数据从内核缓存写入用户缓存一定是由用户线程自行读取数据,处理数据。
异步:第二步数据是内核写入的,并放在了用户线程指定的缓存区,写入完毕后通知用户线程。
同步和异步针对应用程序来,关注的是程序中间的协作关系;阻塞与非阻塞更关注的是单个进程的执行状态。
同步有阻塞和非阻塞之分,异步没有,它一定是非阻塞的。
阻塞、非阻塞、多路IO复用,都是同步IO,异步必定是非阻塞的,所以不存在异步阻塞和异步非阻塞的说法。真正的异步IO需要CPU的深度参与。换句话说,只有用户线程在操作IO的时候根本不去考虑IO的执行全部都交给CPU去完成,而自己只等待一个完成信号的时候,才是真正的异步IO。所以,拉一个子线程去轮询、去死循环,或者使用select、poll、epool,都不是异步。
同步:执行一个操作之后,进程触发IO操作并等待(也就是我们说的阻塞)或者轮询的去查看IO操作(也就是我们说的非阻塞)是否完成,等待结果,然后才继续执行后续的操作。
异步:执行一个操作后,可以去执行其他的操作,然后等待通知再回来执行刚才没执行完的操作。
阻塞:进程给CPU传达一个任务之后,一直等待CPU处理完成,然后才执行后面的操作。
非阻塞:进程给CPU传达任务后,继续处理后续的操作,隔断时间再来询问之前的操作是否完成。这样的过程其实也叫轮询。
## 3. IO多路复用
I/O多路复用也是阻塞IO,只是阻塞的方法是select/poll/epoll ,好处就是单个进程可以处理多个socket
用select, poll, epoll监听多个io对象,当io对象有变化(有数据)的时候,则立即通知相应程序进行读或写操作。但select,poll,epoll本质上都是同步I/O,因为他们都需要在读写事件就绪后自己负责进行读写,也就是说这个读写过程是阻塞的
因为阻塞I/O只能阻塞一个I/O操作,而I/O复用模型能够阻塞多个I/O操作,所以才叫做多路复用。
到这里整理完毕。
最新文章
- swift变量和函数
- Deep Learning入门视频(上)_一层/两层神经网络code
- 绘制圆动画--重写view
- ASP.NET MVC怎样引用你的model
- TinyFrame升级之七:重构Repository和Unit Of Work
- php小算法总结一(数组重排,进制转换)
- EXTJS AJAX解析XML数据
- logstash gsub替换
- Java public, private, protected and default
- Byte、KB、MB、GB、TB、PB、EB是啥以及它们之间的进率
- 直接在CMake项目中编译GoogleTest和GoogleMock作为项目的一部分
- 详解MySQL基准测试和sysbench工具
- 支持向量机(Support Vector Machine)-----SVM之SMO算法(转)
- java中集合的增删改操作及遍历总结
- 《android开发艺术探索》读书笔记(六)--Drawable
- 本地测试使用Tomcat,生产环境使用GlassFish。
- ServiceStack 多租户的实现方案
- 使用ngxtop实时监控nginx
- 【树】Kth Smallest Element in a BST(递归)
- JAVA synchronized关键字锁机制(中)