Kafka高可用的保证
zookeeper作为去中心化的集群模式,消费者需要知道现在那些生产者(对于消费者而言,kafka就是生产者)是可用的。
如果没有zookeeper每次消费者在消费之前都去尝试连接生产者测试下是否连接成功,这样无法保证效率
Replication & Leader election
Kafka中主题的每个partition有一个预写式日志,每个partition都由一系列有序的、不可变的消息组成,这些消息被连续的追加到partition中,
partition中的每个消息都由一个连续的序列号叫做offset,确定他在分区日志中唯一的位置。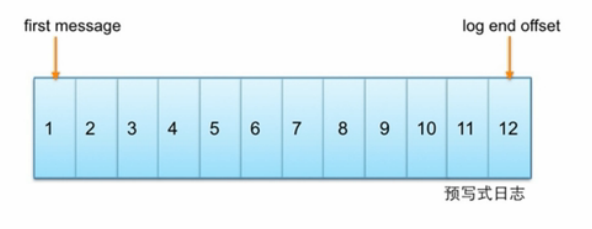
分布式:
每个分区在Kafka集群的若干服务中都有副本,这样这些持有副本的服务可以共同处理数据和请求,副本数量是可以配置的,副本使Kafka具备了容错能力。
每个分区都由一个服务器作为leader,零或若干服务器作为followers,leader负责处理消息的读和写,followers则去复制leader,如果leader宕了,
followers中的一台则会自动成为leader。集群中的每个服务都会同时扮演两个角色:作为它所持有的一部分分区的leader,同时作为其他分区的followers,
这样集群就会具有较好的负载均衡。
Replication与leader election:
Replication与leader election配合提供了自动的failover机制,replication对Kafka的吞吐率是有一定影响的,
但极大的增强了可用性。默认情况下,Kafka的replication数量(不能为0,不能大于broker数量)为1,每个partition都有唯一的leader,所有的读写操作
都在leader上完成follower批量从leader上pull数据。和大部分分布式系统一样,Kafka处理失败需要明确定义一个broker
是否alive,对于Kafka而言,Kafka存货包含两个条件,一是它必须维护与zookeeper的会话(这个通过zookeeper的heartbeat机制来实现)
二是follower必须能够及时将leader的writing复制过来。
Kafka每个topic的partition有N个副本,其中N是topic的复制因子,Kafka通过多副本机制实现故障转移,当Kafka集群中的一个Broker
失效情况下仍然保证服务可用。在Kafka中发生复制时确保partition的预写式日志有序地写到其他节点上。N个replications中,其中一个replication
为leader,其他都为follower,leader处理partition的所有读写请求,与此同时,follower会被定期地去复制leader上的数据。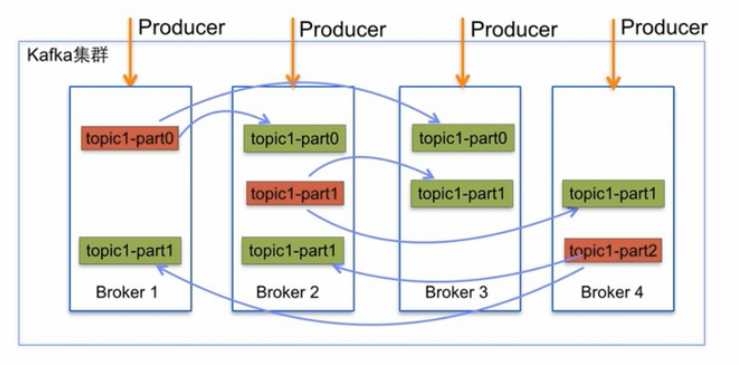
最新文章
- 前端开发必备!Emmet使用手册
- 深入学习jQuery选择器系列第四篇——过滤选择器之属性选择器
- [mysql]知识补充
- js中的引用类型-object
- 中国各城市PM2.5数据间的相关分析
- FRM-10001, FRM-10002, FRM-10003 Oracle Form Builder Error Solution
- 浏览器被hao.360.cn劫持怎么办
- Python基础教程【读书笔记】 - 2016/7/19
- ok6410的LCD裸机范例
- [Fiddler]Unable to Generate Certificate
- 插入标记 方法 insertAdjacentHTML
- java 通过eclipse编辑器用mysql尝试 连接数据库
- CSS中的一下小技巧2之CSS3动画勾选运用
- 第一篇-Html标签中head标签,body标签中input系列,textarea和select标签
- servlet总结:Servlet基础
- USB之HID类Set_Report Request[调试手记1]
- mui init 出现无法引入子页面问题
- Mysql update 一个表中自己的数据
- Xilinx Platform Usb Cable
- webapi 文件下载输出接口