Hadoop项目实战
2024-08-27 14:21:29
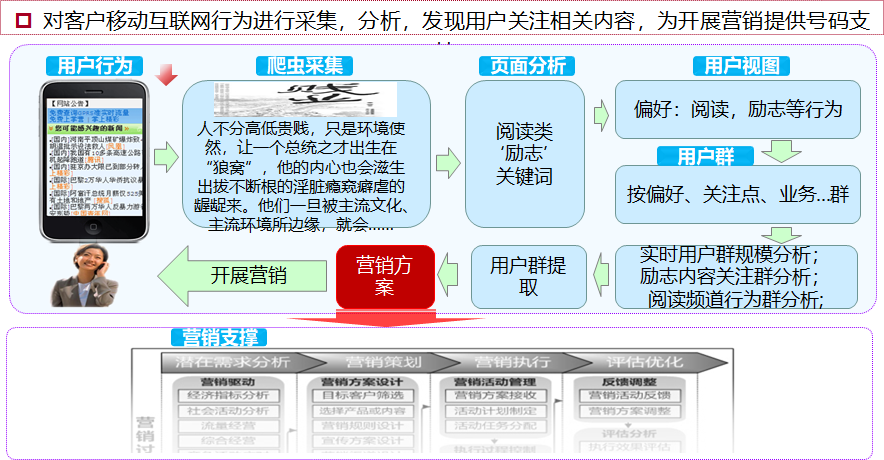
这个项目是流量经营项目,通过Hadoop的离线数据项目。
运营商通过HTTP日志,分析用户的上网行为数据,进行行为轨迹的增强。
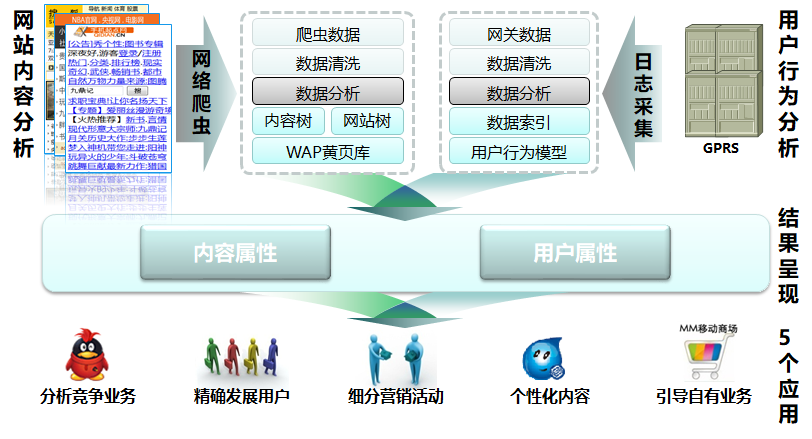
HTTP数据格式为:

流程:


系统架构:
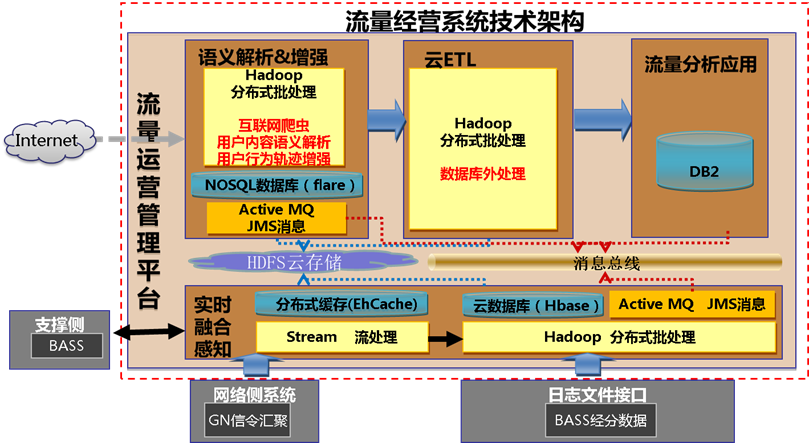
技术选型:

这里只针对其中的一个功能进行说明:
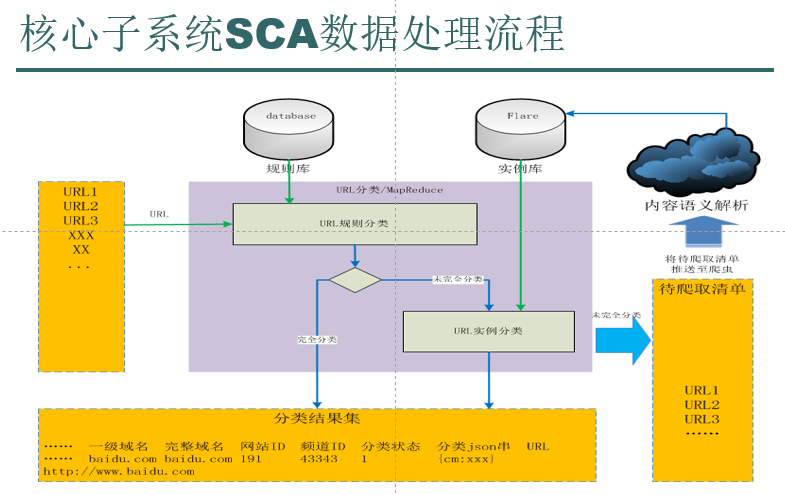
其中规则库是人工填充的,实例库是采用机器学习自动生成的,形式都是<url,info>。
(一)统计流量排名前80%的URL,只有少数的URL流量比特别高,绝大多数的URL流量极低,没有参考价值,应当舍弃。
FlowBean.java:
package cn.itcast.hadoop.mr.flowsum; import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException; import org.apache.hadoop.io.Writable;
import org.apache.hadoop.io.WritableComparable; public class FlowBean implements WritableComparable<FlowBean>{ private String phoneNB;
private long up_flow;
private long d_flow;
private long s_flow; //在反序列化时,反射机制需要调用空参构造函数,所以显示定义了一个空参构造函数
public FlowBean(){} //为了对象数据的初始化方便,加入一个带参的构造函数
public FlowBean(String phoneNB, long up_flow, long d_flow) {
this.phoneNB = phoneNB;
this.up_flow = up_flow;
this.d_flow = d_flow;
this.s_flow = up_flow + d_flow;
} public void set(String phoneNB, long up_flow, long d_flow) {
this.phoneNB = phoneNB;
this.up_flow = up_flow;
this.d_flow = d_flow;
this.s_flow = up_flow + d_flow;
} public String getPhoneNB() {
return phoneNB;
} public void setPhoneNB(String phoneNB) {
this.phoneNB = phoneNB;
} public long getUp_flow() {
return up_flow;
} public void setUp_flow(long up_flow) {
this.up_flow = up_flow;
} public long getD_flow() {
return d_flow;
} public void setD_flow(long d_flow) {
this.d_flow = d_flow;
} public long getS_flow() {
return s_flow;
} public void setS_flow(long s_flow) {
this.s_flow = s_flow;
} //将对象数据序列化到流中
@Override
public void write(DataOutput out) throws IOException { out.writeUTF(phoneNB);
out.writeLong(up_flow);
out.writeLong(d_flow);
out.writeLong(s_flow); } //从数据流中反序列出对象的数据
//从数据流中读出对象字段时,必须跟序列化时的顺序保持一致
@Override
public void readFields(DataInput in) throws IOException { phoneNB = in.readUTF();
up_flow = in.readLong();
d_flow = in.readLong();
s_flow = in.readLong(); } @Override
public String toString() { return "" + up_flow + "\t" +d_flow + "\t" + s_flow;
} @Override
public int compareTo(FlowBean o) {
return s_flow>o.getS_flow()?-1:1;
} }
TopkURLMapper.java:
package cn.itcast.hadoop.mr.llyy.topkurl; import java.io.IOException; import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; import cn.itcast.hadoop.mr.flowsum.FlowBean; public class TopkURLMapper extends Mapper<LongWritable, Text, Text, FlowBean> { private FlowBean bean = new FlowBean();
private Text k = new Text(); @Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException { String line = value.toString(); String[] fields = StringUtils.split(line, "\t");
try {
if (fields.length > 32 && StringUtils.isNotEmpty(fields[26])
&& fields[26].startsWith("http")) {
String url = fields[26]; long up_flow = Long.parseLong(fields[30]);
long d_flow = Long.parseLong(fields[31]); k.set(url);
bean.set("", up_flow, d_flow); context.write(k, bean);
}
} catch (Exception e) { System.out.println(); }
} }
TopkURLReducer.java:
package cn.itcast.hadoop.mr.llyy.topkurl; import java.io.IOException;
import java.util.Map.Entry;
import java.util.Set;
import java.util.TreeMap; import org.apache.hadoop.hdfs.server.namenode.HostFileManager.EntrySet;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; import cn.itcast.hadoop.mr.flowsum.FlowBean; public class TopkURLReducer extends Reducer<Text, FlowBean, Text, LongWritable>{
private TreeMap<FlowBean,Text> treeMap = new TreeMap<>();
private double globalCount = 0; // <url,{bean,bean,bean,.......}>
@Override
protected void reduce(Text key, Iterable<FlowBean> values,Context context)
throws IOException, InterruptedException {
Text url = new Text(key.toString());
long up_sum = 0;
long d_sum = 0;
for(FlowBean bean : values){ up_sum += bean.getUp_flow();
d_sum += bean.getD_flow();
} FlowBean bean = new FlowBean("", up_sum, d_sum);
//每求得一条url的总流量,就累加到全局流量计数器中,等所有的记录处理完成后,globalCount中的值就是全局的流量总和
globalCount += bean.getS_flow();
treeMap.put(bean,url); } //cleanup方法是在reduer任务即将退出时被调用一次
@Override
protected void cleanup(Context context)
throws IOException, InterruptedException { Set<Entry<FlowBean, Text>> entrySet = treeMap.entrySet();
double tempCount = 0; for(Entry<FlowBean, Text> ent: entrySet){ if(tempCount / globalCount < 0.8){ context.write(ent.getValue(), new LongWritable(ent.getKey().getS_flow()));
tempCount += ent.getKey().getS_flow(); }else{
return;
} } } }
TopkURLRunner.java:
package cn.itcast.hadoop.mr.llyy.topkurl; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; import cn.itcast.hadoop.mr.flowsum.FlowBean; public class TopkURLRunner extends Configured implements Tool{ @Override
public int run(String[] args) throws Exception { Configuration conf = new Configuration();
Job job = Job.getInstance(conf); job.setJarByClass(TopkURLRunner.class); job.setMapperClass(TopkURLMapper.class);
job.setReducerClass(TopkURLReducer.class); job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class); job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class); FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1])); return job.waitForCompletion(true)?0:1;
} public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new TopkURLRunner(), args);
System.exit(res); } }
(二)将统计的URL导入到数据库中,这是URL规则库,一共就两个字段,URL和info说明,info是人工来实现,贴上标签。
将上面的运行结果通过sqoop导入到数据库中,然后通过数据库读取再跑mapreduce程序。
DBLoader.java:数据库的工具类。
package cn.itcast.hadoop.mr.llyy.enhance;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
import java.util.HashMap; public class DBLoader { public static void dbLoader(HashMap<String, String> ruleMap) { Connection conn = null;
Statement st = null;
ResultSet res = null; try {
Class.forName("com.mysql.jdbc.Driver");
conn = DriverManager.getConnection("jdbc:mysql://weekend01:3306/urlcontentanalyse", "root", "root");
st = conn.createStatement();
res = st.executeQuery("select url,info from urlrule");
while (res.next()) {
ruleMap.put(res.getString(1), res.getString(2));
} } catch (Exception e) {
e.printStackTrace(); } finally {
try{
if(res!=null){
res.close();
}
if(st!=null){
st.close();
}
if(conn!=null){
conn.close();
} }catch(Exception e){
e.printStackTrace();
}
} } public static void main(String[] args) {
DBLoader db = new DBLoader();
HashMap<String, String> map = new HashMap<String,String>();
db.dbLoader(map);
System.out.println(map.size());
} }
LogEnhanceOutputFormat.java:默认是TextOutputFormat,这里我需要实现将不同的结果输到不同的文件中,而不是_SUCCESS中,所以我需要重写一个format。
package cn.itcast.hadoop.mr.llyy.enhance; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapreduce.RecordWriter;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class LogEnhanceOutputFormat<K, V> extends FileOutputFormat<K, V> { @Override
public RecordWriter<K, V> getRecordWriter(TaskAttemptContext job)
throws IOException, InterruptedException { FileSystem fs = FileSystem.get(new Configuration());
FSDataOutputStream enhancedOs = fs.create(new Path("/liuliang/output/enhancedLog"));
FSDataOutputStream tocrawlOs = fs.create(new Path("/liuliang/output/tocrawl")); return new LogEnhanceRecordWriter<K, V>(enhancedOs,tocrawlOs);
} public static class LogEnhanceRecordWriter<K, V> extends RecordWriter<K, V>{
private FSDataOutputStream enhancedOs =null;
private FSDataOutputStream tocrawlOs =null; public LogEnhanceRecordWriter(FSDataOutputStream enhancedOs,FSDataOutputStream tocrawlOs){ this.enhancedOs = enhancedOs;
this.tocrawlOs = tocrawlOs; } @Override
public void write(K key, V value) throws IOException,
InterruptedException { if(key.toString().contains("tocrawl")){
tocrawlOs.write(key.toString().getBytes());
}else{
enhancedOs.write(key.toString().getBytes());
} } @Override
public void close(TaskAttemptContext context) throws IOException,
InterruptedException { if(enhancedOs != null){
enhancedOs.close();
}
if(tocrawlOs != null){
tocrawlOs.close();
} } } }
然后再从所有原始日志中抽取URL,查询规则库,如果由info标签,则追加在原始日志后面。否则,这个URL就是带爬取URL,后面追加tocrawl,这两种不同情况要输出到不同文件中。
LogEnhanceMapper.java:
package cn.itcast.hadoop.mr.llyy.enhance; import java.io.IOException;
import java.util.HashMap; import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; /**
*
*
* 读入原始日志数据,抽取其中的url,查询规则库,获得该url指向的网页内容的分析结果,追加到原始日志后
*
* @author duanhaitao@itcast.cn
*
*/ // 读入原始数据 (47个字段) 时间戳 ..... destip srcip ... url .. . get 200 ...
// 抽取其中的url查询规则库得到众多的内容识别信息 网站类别,频道类别,主题词,关键词,影片名,主演,导演。。。。
// 将分析结果追加到原始日志后面
// context.write( 时间戳 ..... destip srcip ... url .. . get 200 ...
// 网站类别,频道类别,主题词,关键词,影片名,主演,导演。。。。)
// 如果某条url在规则库中查不到结果,则输出到带爬清单
// context.write( url tocrawl)
public class LogEnhanceMapper extends
Mapper<LongWritable, Text, Text, NullWritable> { private HashMap<String, String> ruleMap = new HashMap<>(); // setup方法是在mapper task 初始化时被调用一次
@Override
protected void setup(Context context) throws IOException,
InterruptedException {
DBLoader.dbLoader(ruleMap);
} @Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException { String line = value.toString(); String[] fields = StringUtils.split(line, "\t");
try {
if (fields.length > 27 && StringUtils.isNotEmpty(fields[26])
&& fields[26].startsWith("http")) {
String url = fields[26];
String info = ruleMap.get(url);
String result = "";
if (info != null) {
result = line + "\t" + info + "\n\r";
context.write(new Text(result), NullWritable.get());
} else {
result = url + "\t" + "tocrawl" + "\n\r";
context.write(new Text(result), NullWritable.get());
} } else {
return;
}
} catch (Exception e) {
System.out.println("exception occured in mapper.....");
}
} }
LogEnhanceRunner.java:
package cn.itcast.hadoop.mr.llyy.enhance; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; public class LogEnhanceRunner extends Configured implements Tool{ @Override
public int run(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(LogEnhanceRunner.class); job.setMapperClass(LogEnhanceMapper.class); job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class); job.setOutputFormatClass(LogEnhanceOutputFormat.class); FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1])); return job.waitForCompletion(true)?0:1;
} public static void main(String[] args) throws Exception {
int res = ToolRunner.run(new Configuration(), new LogEnhanceRunner(),args);
System.exit(res);
} }
这里不写reduce也行。
MapReduce实现Top K问题:https://blog.csdn.net/u011750989/article/details/11482805?locationNum=5
最新文章
- java集合你了解多少?
- hrbust1841再就业(状态压缩dp)
- attr和prop区别
- c++学习--面向对象一实验
- Hash函数及其应用
- BZOJ1841 : 蚂蚁搬家
- 未能找到类型或命名空间名称“Coco”(是否缺少 using 指令或程序集引用)
- 让ORACLE LIKE 时不区分大小写
- spark与Hadoop区别
- 初涉C#防止黑客攻击站短
- 微信 token 验证
- Handler学习小结
- struts2-剩余
- thinkphp5.0 ajax分页
- Exp3 免杀原理和实践
- 73.纯 CSS 创作一只卡通狐狸
- 04_安装Nginx图片服务器
- Linux背背背(1)
- 一、linux IO 编程---内存管理
- bzoj4697: 猪