day17-jdbc 5.url介绍
2024-09-06 18:25:47

url用于标识数据库的位置,用于标识找哪个数据库。

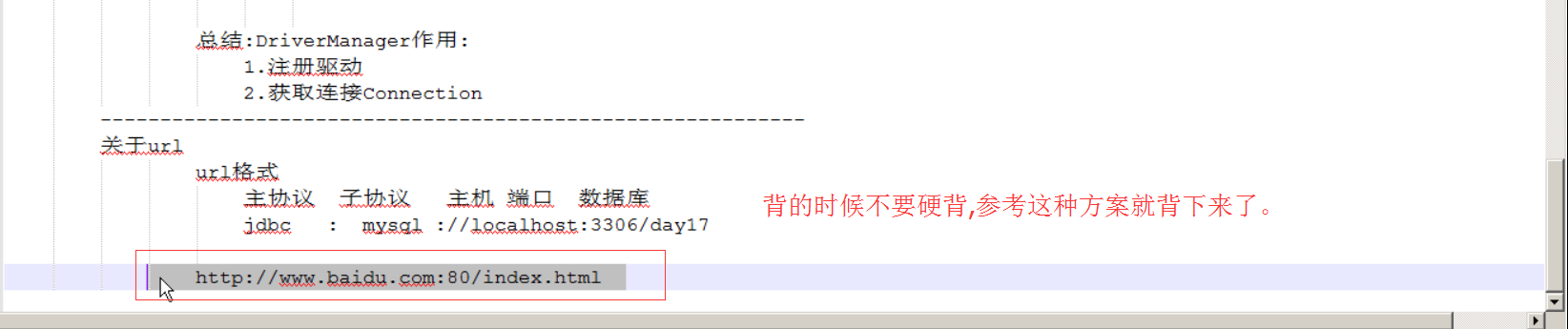
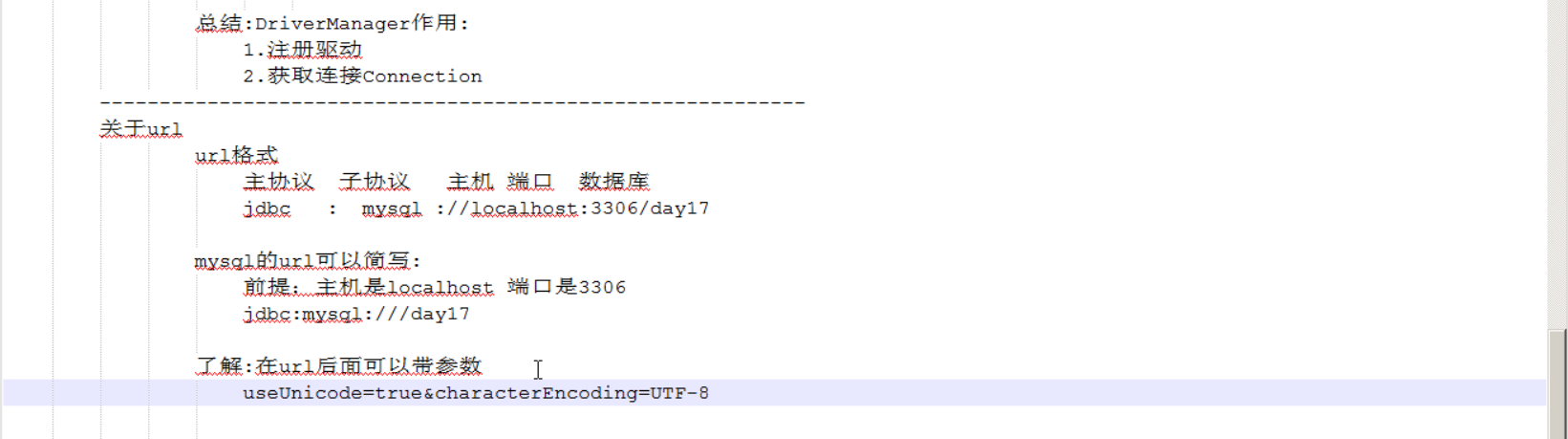
总结:url是路径,其实就是确定是哪个数据库。用来确定我用的是哪一个数据库,并且通知我这个Connection或者是这个DriverManager获取这个连接的时候找的是哪个数据库。
package cn.itcast.jdbc; import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement; import com.mysql.jdbc.Driver;
//解决关于加载驱动问题
public class JdbcDemo2 {
public static void main(String[] args) throws SQLException, ClassNotFoundException { //1.注册驱动
//DriverManager.registerDriver(new Driver());//一注册驱动,驱动就加载到内存里面了 也就是说我们就可以用它了 加载了两个驱动
Class.forName("com.mysql.jdbc.Driver");//优点是加载一次 替换registerDriver()这个方法 这个不耦合,根本就没用mysql驱动的东西 不是意味着那就不用驱动了,只是不依赖jar包
//在代码上、表现上根本就看不到驱动那包 用的都是公共的那种接口(Connection、DriverManager、ResultSet、SQLException、Statement),就是JDK里面提供的公共的接口
//编程的都知道不依赖任何东西是最好的,因为没有耦合,但是那是不可能的。所以要尽量让耦合度降低
//加载mysql驱动
Class.forName("oracle.jdbc.driver.OracleDriver");//加载oracle驱动
//它怎么知道这是oracle驱动还是mysql驱动呢?它是如何区分的? //String url = "jdbc:mysql://localhost:3306/day17";
String url = "jdbc:mysql:///day17"; //2.获取连接对象
Connection con = DriverManager.getConnection(url, "root", "");
System.out.println(con);
//connection是接口,是驱动,驱动肯定把这个接口实现了 编程用最顶层去接收操作起来会比较方便 前面是父,后面是子 用最顶层接收
//3.通过连接对象获取操作sql语句的Statement
Statement st = con.createStatement();
//4.操作sql语句
String sql = "select * from user";
ResultSet rs = st.executeQuery(sql);//ResultSet就是查询的结果,可以想象成是集合,但是它不是集合 //5.遍历结果集
/* boolean flag = rs.next();//向下移动,返回值为true,代表有下一条记录。 System.out.println(flag);
int id = rs.getInt(1);
int id1 = rs.getInt("id");
System.out.println(id);
System.out.println(id1);
String username = rs.getString(2);
String username1 = rs.getString("username");
System.out.println(username);
System.out.println(username1);*/
while(rs.next()){
int id = rs.getInt("id");
String username = rs.getString("username");
String password = rs.getString("password");
String email = rs.getString("email");
System.out.println(id+" "+username+" "+password+" "+email);
}
//只要Java程序跟任何设备进行了连接,用完之后必须释放资源。最简单基础班讲I/O流,Java跟文件进行了连接,用完之后关闭文件流。数据库也是一个设备。Java跟数据库连接上了用完之后也要关闭。必须把资源释放。
//6.释放资源
rs.close();//结果集得关
st.close();
con.close();
//直接把con关闭了,数据库和程序断开了。但是statement和resultset没有及时释放,它还在内存存着。close()是释放和回收资源。
//close()的顺序和进门出门是一样的,是进门的时候先进大门,出门的时候是最后才出大门
//=============
//Java可以操作数据库
}
}
最新文章
- Ubuntu 14 Trusty安装hue
- 深入浅出JMS(一) JMS基本概念
- vuex2.0.0爬坑记录 -- mutations的第一个参数state不能解构
- tmtTable设计说明文档
- Java的注解机制——Spring自动装配的实现原理
- 资源: StaticResource, ThemeResource
- 让下拉框中同时显示Key与Value
- 序列化LinkedHashMap,有序输出Json字符串
- visualvm添加远程管理-centos
- JapserReport导出PDF Could not load the following font错误
- 谈谈WCF中的Data Contract(3):WCF Data Contract对Collection & Dictionary的支持
- LCS算法思想
- Mongoose的使用
- Redis介绍——Linux环境Redis安装全过程和遇到的问题及解决方案
- getHibernateTemplate() VS getSession()
- 【Web安全】DoS及其家族
- 闲聊 Exp/Imp 命令使用
- LINUX内核PCI扫描过程
- react中的传参方式
- [Leetcode 37]*数独游戏 Sudoku Solver 附解释