linux中O(1)调度算法与全然公平(CFS)调度算法
一、O(1)调度算法
1.1:优先级数组
O(1)算法的:一个核心数据结构即为prio_array结构体。
该结构体中有一个用来表示进程动态优先级的数组queue,它包括了每一种优先级进程所形成的链表。
1 |
#define |
2 |
#define |
3 |
#define |
4 |
typedef struct prio_array |
5 |
struct prio_array |
6 |
unsigned int nr_active; |
7 |
unsigned long bitmap[BITMAP_SIZE]; |
8 |
struct list_head |
9 |
}; |
因为进程优先级的最大值为139,因此MAX_PRIO的最大值取140(详细的是,普通进程使用100到139的优先级。实时进程使用0到99的优先级)。因此,queue数组中包括140个可执行状态的进程链表,每一条优先级链表上的进程都具有同样的优先级,而不同进程链表上的进程都拥有不同的优先级。
除此之外,prio_array结构中还包含一个优先级位图bitmap。该位图使用一个位(bit)来代表一个优先级,而140个优先级最少须要5个32位来表示,因此BITMAP_SIZE的值取5。起初。该位图中的全部位都被置0,当某个优先级的进程处于可执行状态时。该优先级所相应的位就被置1。
因此,O(1)算法中查找系统最高的优先级就转化成查找优先级位图中第一个被置1的位。
与2.4内核中依次比較每一个进程的优先级不同,因为进程优先级个数是定值,因此查找最佳优先级的时间恒定。它不会像曾经的方法那样受可运行进程数量的影响。
假设确定了优先级。那么选取下一个进程就简单了,仅仅需在queue数组中相应的链表上选取一个进程就可以。
1.2:活动进程和过期进程
在操作系统原理课上我们知道,当处于执行态的进程用完时间片后就会处于就绪态。此时调度程序再从就绪态的进程中选取一个作为即将要执行的进程。
而在详细Linux内核中,就绪态和执行态统一称为可执行态(TASK_RUNNING)。
对于系统内处于可执行状态的进程,我们能够分为三类。首先是正处于执行状态的那个进程;其次,有一部分处于可执行状态的进程则还没实用完他们的时间片。他们等待被执行;剩下的进程已经用完了自己的时间片,在其它进程没实用完它们的时间片之前,他们不能再被执行。
据此,我们将进程分为两类,活动进程,那些还没实用完时间片的进程。过期进程。那些已经用完时间片的进程。因此,调度程序的工作就是在活动进程集合中选取一个最佳优先级的进程,假设该进程时间片恰好用完,就将该进程放入过期进程集合中。
在可执行队列结构中,arrays数组的两个元素分别用来表示刚才所述的活动进程集合和过期进程集合,active和expired两个指针分别直接指向这两个集合。
关于可执行队列和两个优先级数组的关系可參考以下的图:
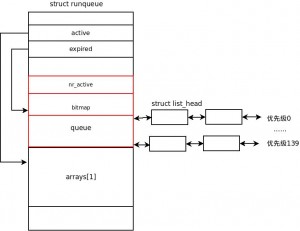
正如上面分析的那样,可执行队列结构和优先级数组结构使得Q(1)调度算法在有限的时间内就能够完毕,它不依赖系统内可执行进程的数量。
1.3:时间片的计算
Linux2.4版本号的内核调度算法理解起来简单:在每次进程切换时。内核依次扫描就绪队列上的每个进程,计算每个进程的优先级,再选择出优先级最高的进程来执行;虽然这个算法理解简单。可是它花费在选择优先级最高进程上的时间却不容忽视。
系统中可执行的进程越多。花费的时间就越大。时间复杂度为O(n)。
伪代码例如以下:
1 |
for (系统中的每一个进程) |
2 |
又一次计算时间片; |
3 |
又一次计算优先级; |
4 |
} |
而2.6内核所採用的O(1)算法则非常好的攻克了这个问题,该算法能够在恒定的时间内为每一个进程又一次分配好时间片,并且在恒定的时间内能够选取一个最高优先级的进程,重要的是这两个过程都与系统中可执行的进程数无关,这也正是该算法取名为O(1)的缘故。
O(1)算法採用过期进程数组和活跃进程数组解决以往调度算法所带来的O(n)复杂度问题。过期数组中的进程都已经用完了时间片。而活跃数组的进程还拥有时间片。当一个进程用完自己的时间片后,它就被移动到过期进程数组中。同一时候这个过期进程在被移动之前就已经计算好了新的时间片。
能够看到O(1)调度算法是採用分散计算时间片的方法,并不像以往算法中集中为全部可执行进程又一次计算时间片。
当活跃进程数组中没有不论什么进程时。说明此时全部可执行的进程都用完了自己的时间片。那么此时仅仅须要交换一下两个数组就可以将过期进程切换为活跃进程,进而继续被调度程序所调度。两个数组之间的切换事实上就是指针之间的交换,因此花费的时间是恒定的。以下的代码说明了两个数组之间的交换:
1 |
struct prop_array |
2 |
if (array->nr_active |
3 |
rq->active |
4 |
rq->expired |
5 |
} |
通过分散计算时间片、交换过期和活跃两个进程集合的方法能够使得O(1)算法在恒定的时间内为每一个进程又一次计算好时间片。
进程调度的本质就是在当前可执行的进程集合中选择一个最佳的进程,这个最佳则是以进程的动态优先级为选取标准的。
无论是过期进程集合还是活跃进程集合,都将每一个优先级的进程组成一个链表,因此每一个集合就有140个不同优先级的进程链表。同一时候。两个集合中还採用优先级位图来标记每一个优先级链表中是否存在进程。
调度程序在选取最高优先级的进程时。首先利用优先级位图从高到低找到第一个被设置的位,该位相应着一条进程链表。这个链表中的进程是当前系统全部可执行进程中优先级最高的。在该优先级链表中选取头一个进程,它拥有最高的优先级。即为调度程序立即要执行的进程。
上述进程的选取过程可用下述代码描写叙述:
01 |
struct task_struct |
02 |
struct list_head |
03 |
struct prio_array |
04 |
int idx; |
05 |
06 |
prev |
07 |
array |
08 |
idx |
09 |
queue |
10 |
nextstruct task_struct, |
11 |
if (prev |
12 |
context_switch(); |
sehed_find_first_bit()用于在位图中高速查找第一个被设置的位。假设prev和next不是一个进程。那么此时进程切换就開始运行。
通过上述的内容能够发现。在恒定的时间又一次分配时间片和选择一个最佳进程是Q(1)算法的核心。
二、全然公平(CFS)调度算法
一个调度算法中最重要的两点就是调度哪个进程以及该被调度进程的执行时间是多少,以下我们分别来讨论
2.1:调度哪个进程
O(1)算法是依据进程的优先级来选择调度进程的,而CFS是依据进程的虚拟执行时间来进行调度的,当然,该虚拟执行时间也会受到优先级的影响。但不全是。以下看看什么是虚拟执行时间。以及怎样依据它来选择下一个调度进程。
CFS算法的初衷就是让全部进程同一时候执行在一个CPU上,比如两个进程都须要执行10ms的时间,则CFS算法下,连个进程同一时候执行在CPU上,且时间为20ms,而不是每一个进程分别执行10ms。可是这仅仅是一种理想的执行方式,CFS为了近似这样的执行算法,就提出了虚拟执行时间(vruntime)的概念。
vruntime记录了一个可执行进程到当前时刻为止执行的总时间(须要以进程总数n进行归一化,而且依据进程的优先级进行加权)。依据vruntime的定义能够知道,vruntime越大,说明该进程执行的越久,所以被调度的可能性就越小。所以我们的调度算法就是每次选择vruntime值最小的进程进行调度。内核中使用红黑树能够方便的得到vruntime值最小的进程。
至于每一个进程怎样更新自己的vruntime?内核中是依照例如以下方式来更新的:vruntime
+= delta* NICE_0_LOAD/ se.weight;当中:
NICE_0_LOAD是个定值。及系统默认的进程的权值;se,weight是当前进程的权重(优先级越高。权重越大);
delta是当前进程执行的时间;我们能够得出这么个关系:vruntime与delta成正比,即当前执行时间越长vruntime增长越快
vruntime与se.weight成反比,即权重越大vunruntime增长越慢。简单来说,一个进程的优先级越高,并且该进程执行的时间越少,则该进程的vruntime就越小,该进程被调度的可能性就越高。
2.2:调度进程的执行时间
如今知道了怎样调度进程了,可是当该进程执行时,它的执行时间是多少呢?
CFS的执行时间是有当前系统中全部可调度进程的优先级的比重来确定的,假如如今进程中有三个可调度进程A、B、C,它们的优先级分别为5,10,15,则它们的时间片分别为5/30,10/30,15/30。
而不是由自己的时间片计算得来的,这种话,优先级为1,2的两个进程与优先级为50,100的两个进程分的时间片是同样的。
简单来说,CFS採用的全部进程优先级的比重来计算每一个进程的时间片的,是相对的而不是绝对的。
这样就从以上两个方面来分析了CFS进程调度算法
最新文章
- 第五篇 基于.net搭建热插拔式web框架(拦截器---请求管道)
- Struts2 Result 类型和对应的用法详解
- 简单的DropDownButton(Winform)
- kvm 简介
- 【Hibernate 7】浅谈Hibernate的缓存机制
- PHP开发圣经读书笔记01
- php获取apk信息
- POJ3264——Balanced Lineup(线段树)
- spring boot + mybatis + druid
- 企业推动移动化战略中为什么需要Moli?
- Bash远程代码执行漏洞(CVE-2014-6271)案例分析
- 省市区三级联选select2.js
- linux进程状态D
- MYSQL数据库链接层- SUMMER-SQL
- learning uboot how to set ddr parameter in qca4531 cpu
- 关于发布程序之后js文件存在缓存问题
- 跳出框架iframe的操作语句
- Linux 增加系统调用 (转)
- 【Jmeter】集合点Synchronizing Timer
- MySQL主从不一致的几种故障总结分析、解决和预防
热门文章
- Pie(二分)
- python 46 css组合选择器 及优先级 、属性选择器
- A - HQ9+
- A - Petya and Strings
- Jenkins上Git ssh登陆配置
- lsit集合去重复 顶级表达式
- TypeError: Object function (req, res, next) { app.handle(req, res, next); } has no method 'configure'
- (转) 前端模块化:CommonJS,AMD,CMD,ES6
- 【Oracle】解决oracle sqlplus 中上下左右backspace不能用
- Caffe: gflag编译出现问题汇总