Scrapy学习(二)、安装及项目结构
一、安装
1、安装pywin32,下载地址:https://sourceforge.net/projects/pywin32/files/pywin32/
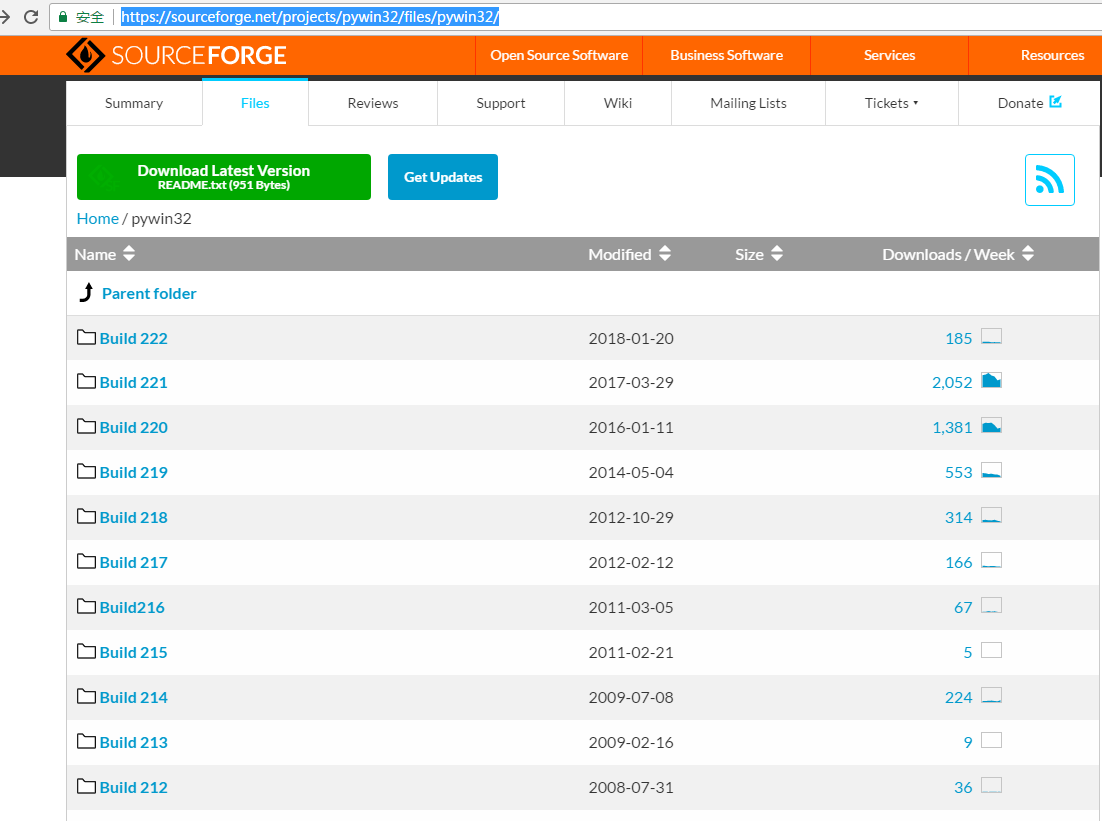
我选择的是Build 221,点进去,根据自己电脑的python版本下载对应的版本
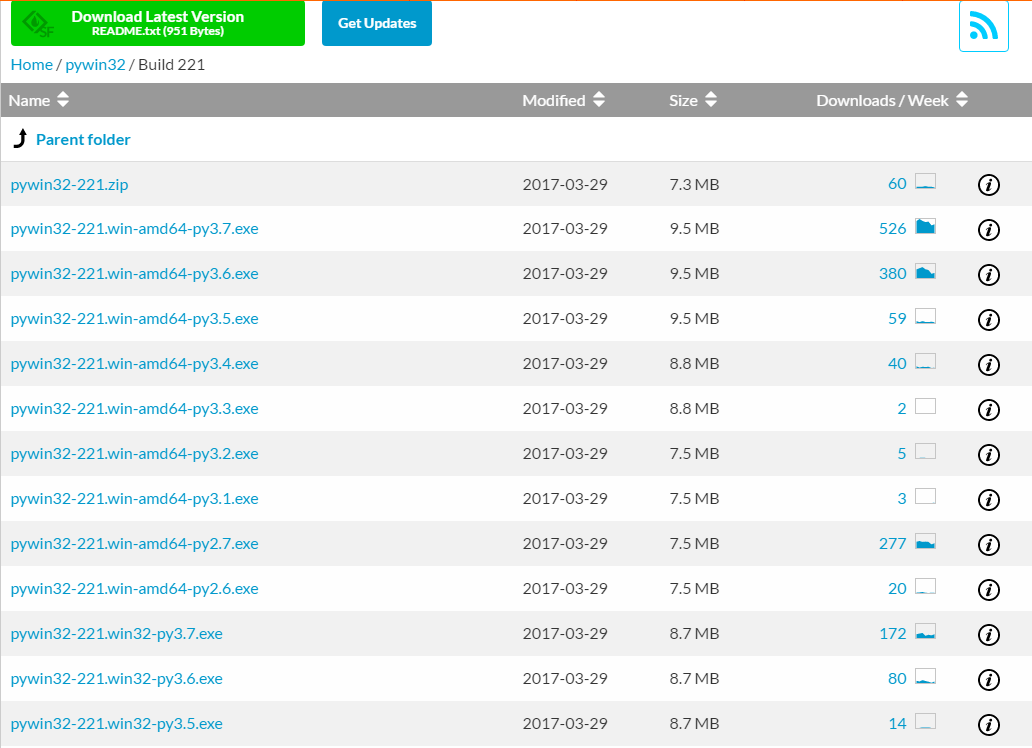
下载下来后,直接运行exe文件,无脑下一步,直至安装完成
2、安装Twisted,下载地址:https://www.lfd.uci.edu/~gohlke/pythonlibs/
找到Twisted,下载对应版本

下载完成后直接pip安装
3、安装scrapy,直接pip install scrapy。不报错就安装成功了
二、项目结构
1、创建项目
进入到工作目录,比如D:\Git\Spider,直接运行命令:scrapy startproject city_58
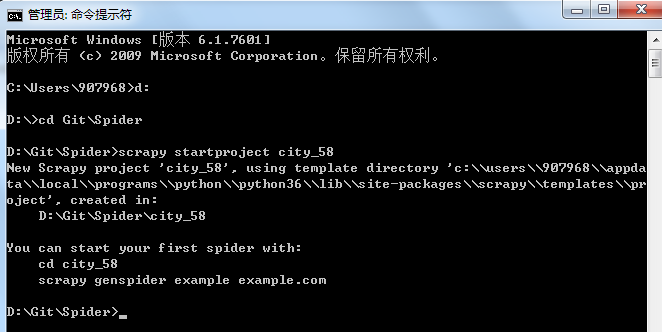
这样就成功创建了一个项目,进入到项目目录下,包含下列内容:
city_58
|scrapy.cfg
|--city_58
| items.py
| middlewares.py
| pipelines.py
| settings.py
| __init__.py
|--spiders
| __init__.py
city_58目录下的文件分别是:
scrapy.cfg:项目部署时的配置文件
city_58/:项目模块,可以在这个目录下加入代码
city_58/items.py:Items的定义,定义爬取的数据结构
city_58/pipelines.py:定义数据管道
city_58/middlewares.py:定义爬取时的中间件
city_58/settings.py:配置文件
city_58/spiders/:放置Spiders的文件夹
2、创建Spider
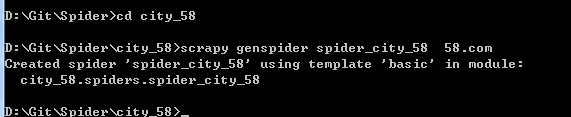
进入项目模块文件夹,这里是city_58,运行命令: scrapy genspider spider_city_58 58.com,其中spider_city_58 为爬虫名称,用于区别Spider,该名字必须是唯一的;58.com为启动时进行爬取的入口URL
最新文章
- Linux 查看端口被占用情况
- 中断(interrupt)、异常(exception)、陷入(trap)
- php新手:XAMMP打开开源php代码
- Uva 11198 - Dancing Digits
- 【原创】开机出现grub rescue,修复办法
- [置顶] Array ArrayList LinkList的区别剖析
- asp.net生成RSS
- view类的XML属性
- Android Studio 实用调试技巧
- SpannableString 给TextView添加不同的显示样式
- 20165223《网络对抗技术》Exp2 后门原理与实践
- 学习excel的使用技巧四显示正常的数字
- OA系统高性能解决方案(史上最全的通达OA系统优化方案)
- 一步到位之INNODB
- SQL Server 2
- [转]抢先Mark!微信公众平台开发进阶篇资源集锦
- daterangepicker日历插件使用参数注意问题
- dp问题 -挑战例题 2017-7-24
- const修饰的成员是类成员,还是实例成员?
- jQuery异步获取json数据的2种方式