【Webscraper】不懂编程也能爬虫
2024-09-01 14:40:02
一、配置环境
在浏览器中安装web scraper插件。
所有安装包下载链接: https://pan.baidu.com/s/1CfAWf0wMO6WqicoUgdYgkg 提取码: nn2e
安装教程:http://www.iwebscraper.com/webscraper-install/
安装成功后打开任意网站,按F12

二、插件简单介绍
步骤

1、选择器选项

2、sitemap选项

三、爬取58同城——多页爬取
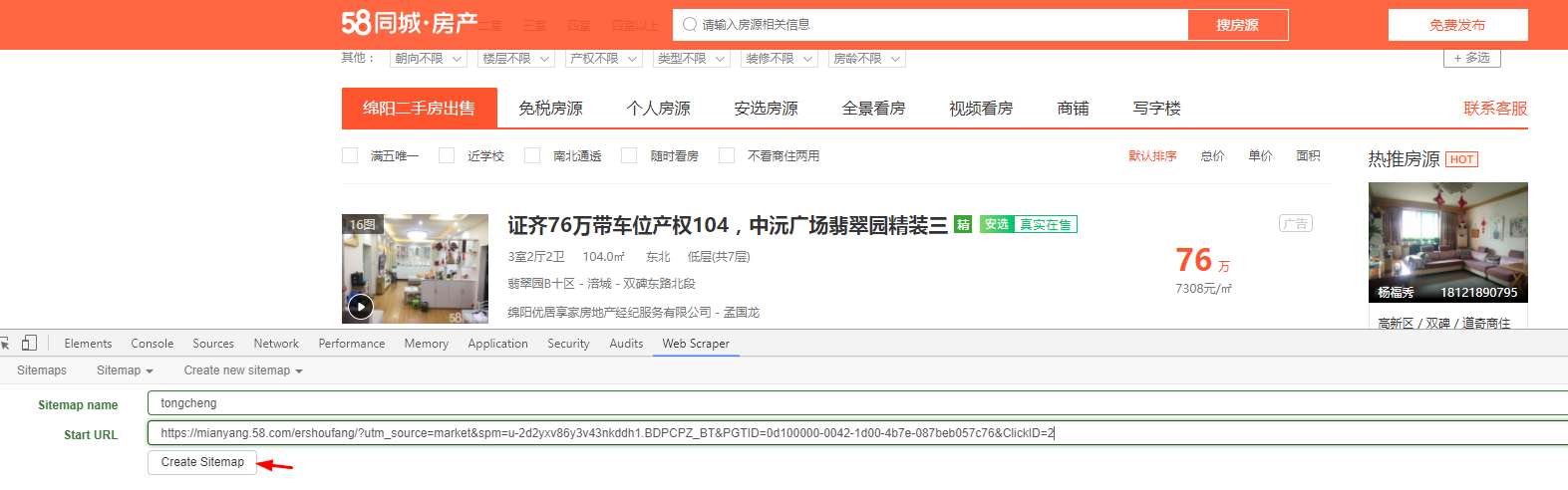

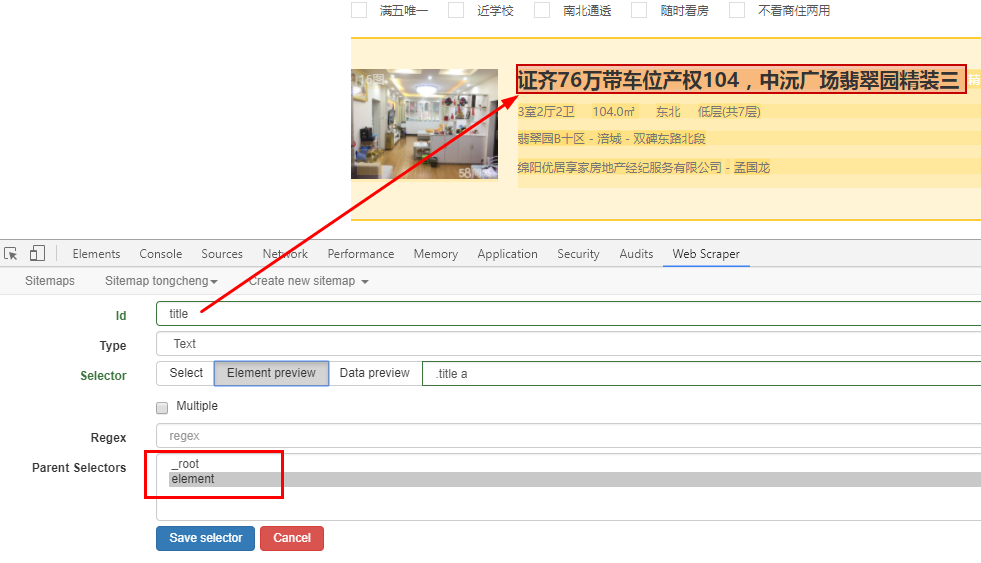


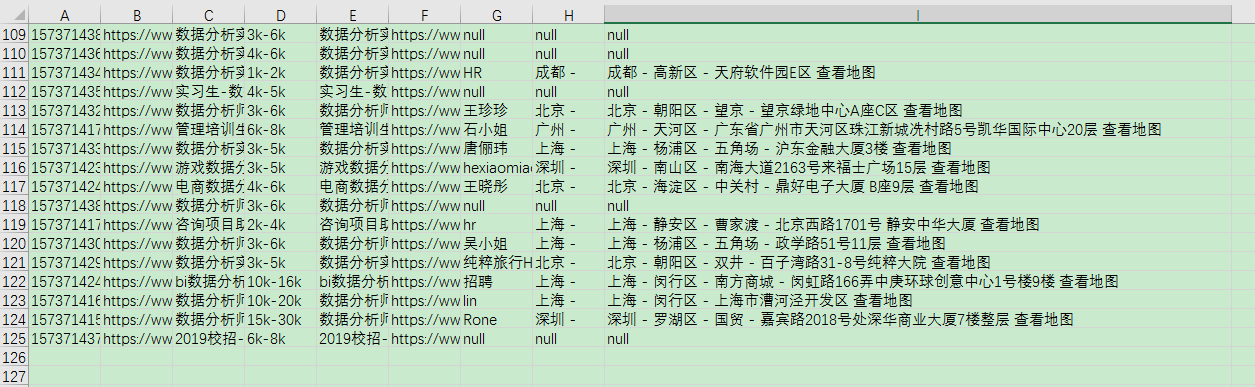
说明:爬取后有多余的换行和空格,在excel中使用trim和clean函数去除空格、换行
爬取多页(1-10页)




四、爬取微博——滚动爬取
element scroll down滚动爬取



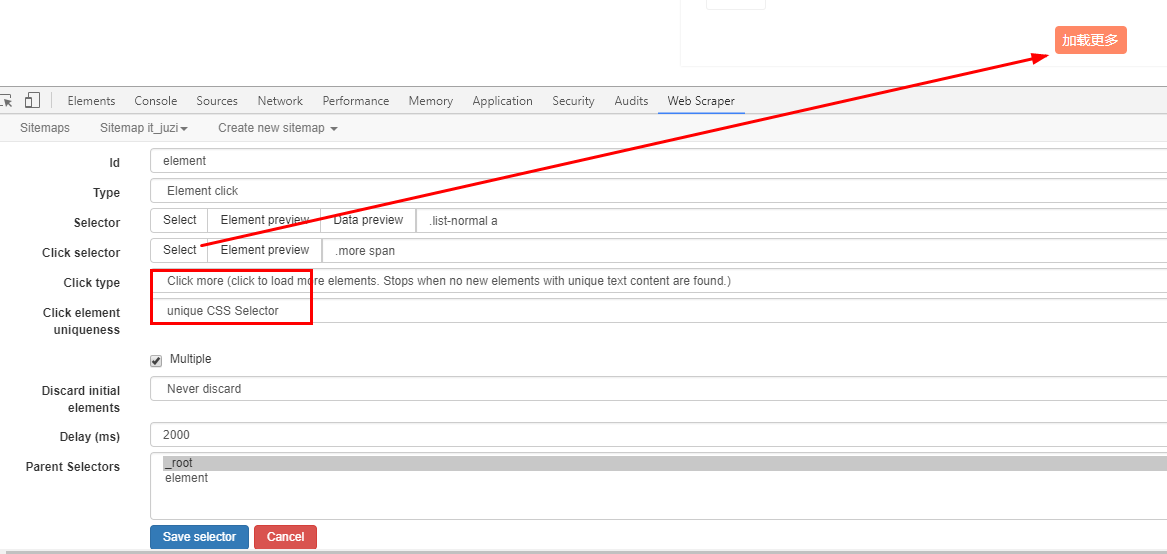
五、点击爬取——爬取IT桔子和微博评论
IT桔子

微博评论
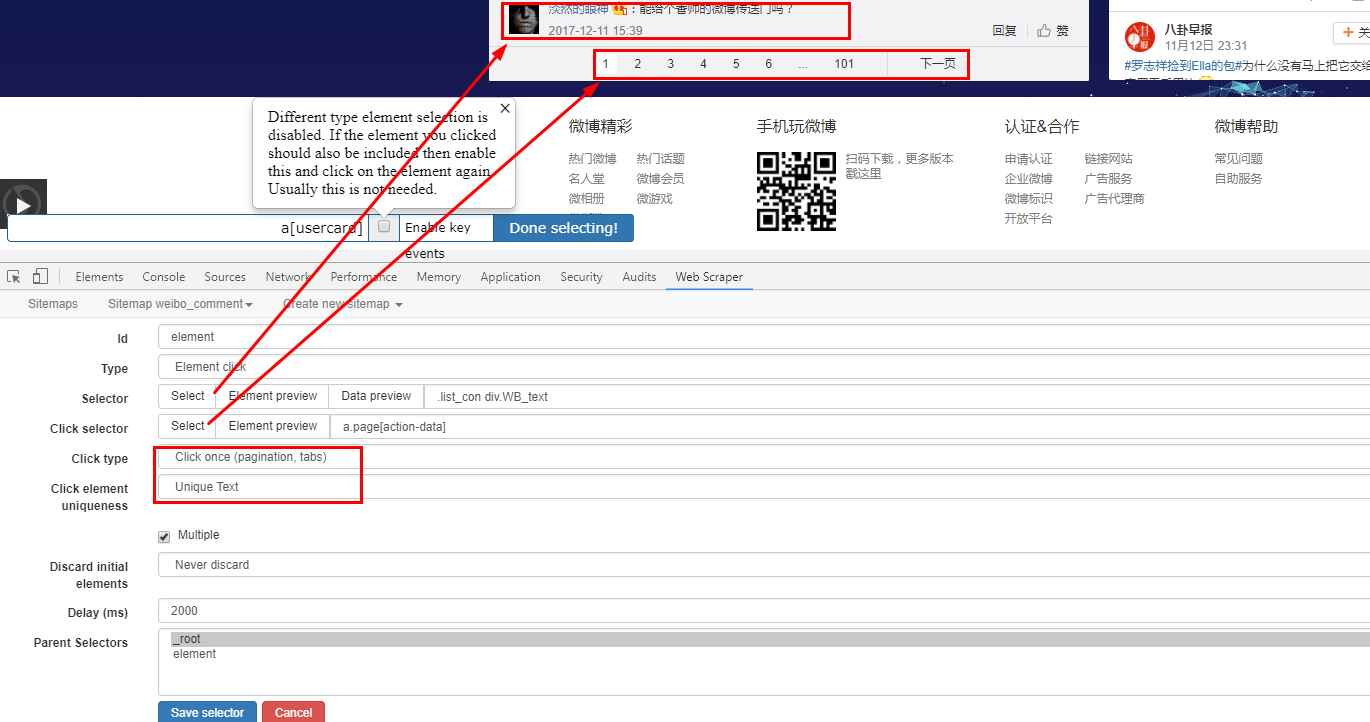

要点解析

抓取多页的方法

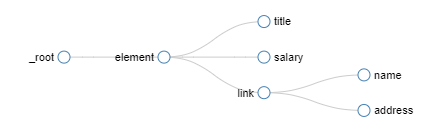
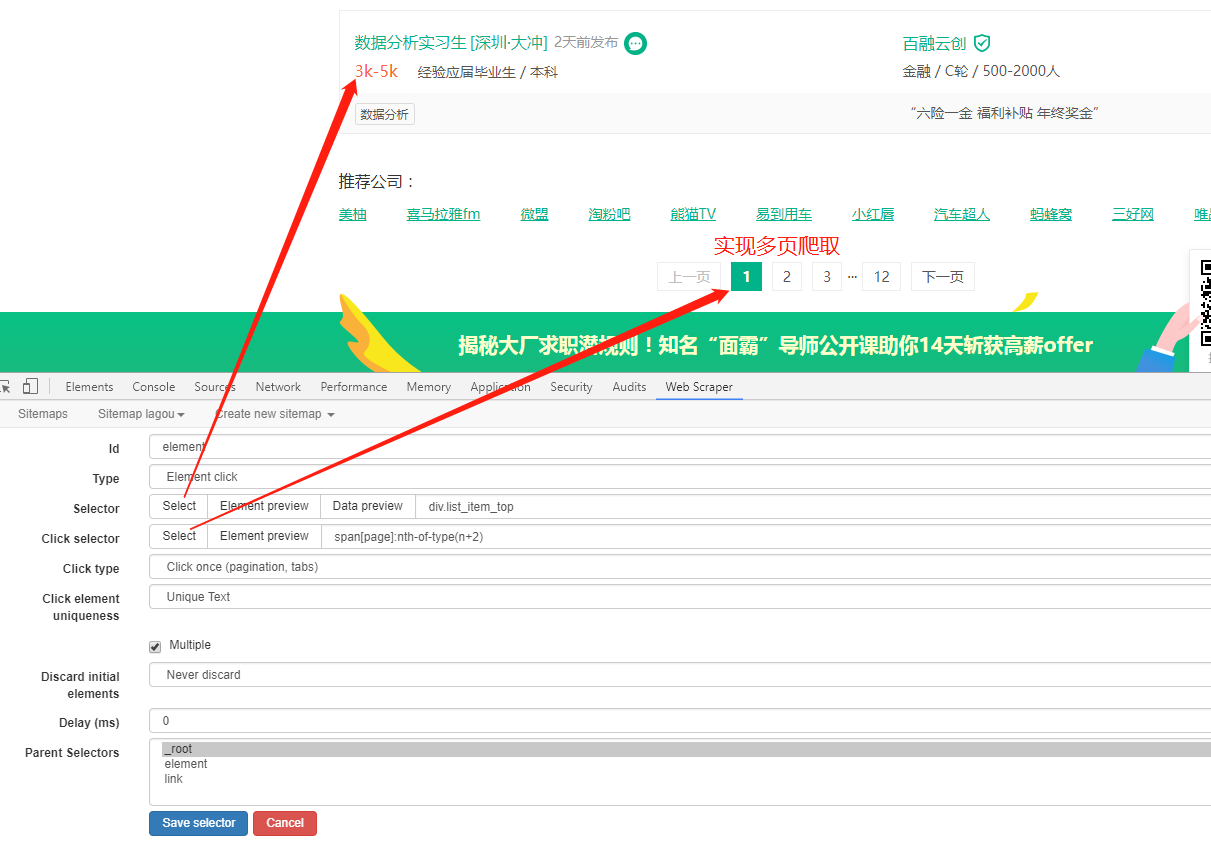
六、爬取拉勾网——二级目录的多页爬取


最新文章
- Linux 下dns的搭建
- flex lineChart 显示所有的数据节点
- HTML 事件属性(下)
- 北京大学信息科学技术学院计算机专业课程大纲选摘--JAVA
- Android2.2快速入门 zz
- sql commands
- make[1]: *** [pcrecpp.lo] 错误 1
- visual studio 2010运行速度提速
- hdu 2177 取(2堆)石子游戏 博弈论
- shell脚本应用(4)--常用命令
- Automatically watermark all uploaded photos (给所有上传的相片加水印)
- List 随机排序
- Cocos2d-x学习笔记(六) 定时器Schedule的简单应用
- Linux下添加shell脚本使得nginx日志每天定时切割压缩
- 基于C#的Appium自动化测试框架(Ⅰ)
- 使用Spring MVC测试Spring Security Oauth2 API
- python 在一个excel存多个sheet
- L-BFGS算法(转载)
- Python3基础 list len 输出元素的个数
- 02-zip文件打包