【CDN+】 Hive 入门 以及Handoop 系统认知
前言
本文主要介绍Hive 的基础概念,以及Handoop的大体架构,组件依赖,对于大数据有个总体的认识
Hive 基础概念
The Apache Hive ™ data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage using SQL. Structure can be projected onto data already in storage. A command line tool and JDBC driver are provided to connect users to Hive.
Apache Hive™数据仓库软件支持使用SQL读取、写入和管理分布存储中的大型数据集。结构可以映射到存储中的数据。提供了一个命令行工具和JDBC驱动程序来将用户连接到Hive。
Hive的 特点:
- Hive是一个构建于Hadoop顶层的数据仓库工具,可以查询和管理PB级别的分布式数据。
- 支持大规模数据存储、分析,具有良好的可扩展性
- 某种程度上可以看作是用户编程接口,本身不存储和处理数据。
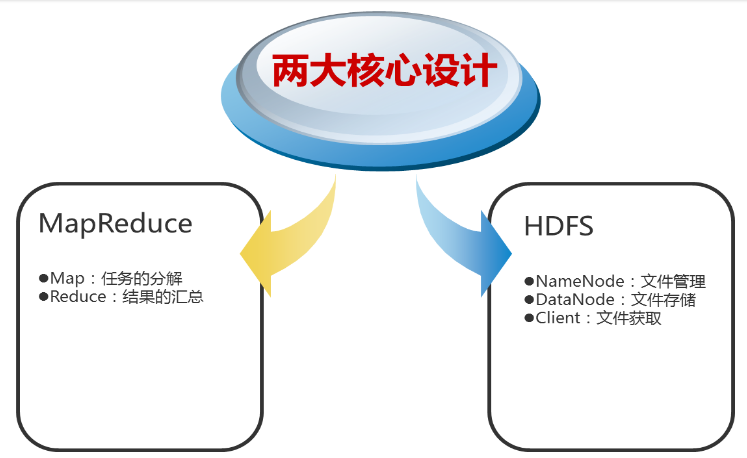
- 依赖分布式文件系统HDFS存储数据。
- 依赖分布式并行计算模型MapReduce处理数据。
- 定义了简单的类似SQL 的查询语言——HiveQL。
- 用户可以通过编写的HiveQL语句运行MapReduce任务。
- 可以很容易把原来构建在关系数据库上的数据仓库应用程序移植到Hadoop平台上。
- 是一个可以提供有效、合理、直观组织和使用数据的分析工具。
Hive应用场景:
- 数据挖掘:用户行为分析;兴趣分区;区域展示;
- 非实时分析:日志分析;文本分析。
- 数据汇总:每天/每周用户点击数,流量统计。
- 数据仓库:数据抽取,加载,转换(ETL)。
思考: Hive 其实不是一个数据库或者数据存储系统,而且是一个数据工具,主要是将SQL语句转化为MapReduce任务执行。
Hive 的结构
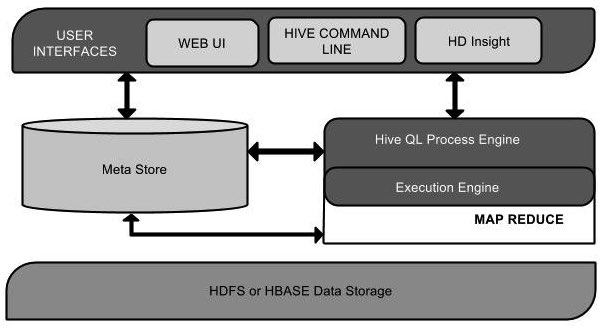
该组件图包含不同的单元。下表描述每个单元:
| 单元名称 | 操作 |
|---|---|
| 用户接口/界面 | Hive是一个数据仓库基础工具软件,可以创建用户和HDFS之间互动。用户界面,Hive支持是Hive的Web UI,Hive命令行,HiveHD洞察(在Windows服务器)。 |
| 元存储 | Hive选择各自的数据库服务器,用以储存表,数据库,列模式或元数据表,它们的数据类型和HDFS映射。 |
| HiveQL处理引擎 | HiveQL类似于SQL的查询上Metastore模式信息。这是传统的方式进行MapReduce程序的替代品之一。相反,使用Java编写的MapReduce程序,可以编写为MapReduce工作,并处理它的查询。 |
| 执行引擎 | HiveQL处理引擎和MapReduce的结合部分是由Hive执行引擎。执行引擎处理查询并产生结果和MapReduce的结果一样。它采用MapReduce方法。 |
| HDFS 或 HBASE | Hadoop的分布式文件系统或者HBASE数据存储技术是用于将数据存储到文件系统。 |
Hive的工作原理
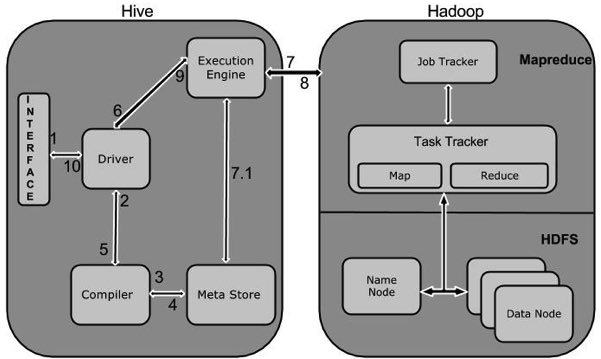
下表定义Hive和Hadoop框架的交互方式:
| Step No. | 操作 |
|---|---|
| 1 | Execute Query
Hive接口,如命令行或Web UI发送查询驱动程序(任何数据库驱动程序,如JDBC,ODBC等)来执行。 |
| 2 | Get Plan
在驱动程序帮助下查询编译器,分析查询检查语法和查询计划或查询的要求。 |
| 3 | Get Metadata
编译器发送元数据请求到Metastore(任何数据库)。 |
| 4 | Send Metadata
Metastore发送元数据,以编译器的响应。 |
| 5 | Send Plan
编译器检查要求,并重新发送计划给驱动程序。到此为止,查询解析和编译完成。 |
| 6 | Execute Plan
驱动程序发送的执行计划到执行引擎。 |
| 7 | Execute Job
在内部,执行作业的过程是一个MapReduce工作。执行引擎发送作业给JobTracker,在名称节点并把它分配作业到TaskTracker,这是在数据节点。在这里,查询执行MapReduce工作。 |
| 7.1 | Metadata Ops
与此同时,在执行时,执行引擎可以通过Metastore执行元数据操作。 |
| 8 | Fetch Result
执行引擎接收来自数据节点的结果。 |
| 9 | Send Results
执行引擎发送这些结果值给驱动程序。 |
| 10 | Send Results
驱动程序将结果发送给Hive接口。 |
Handoop 的结构

(1)Pig是一个基于Hadoop的大规模数据分析平台,Pig为复杂的海量数据并行计算提供了一个简单的操作和编程接口;
(2)Hive是基于Hadoop的一个工具,提供完整的SQL查询,可以将sql语句转换为MapReduce任务进行运行;
(3)ZooKeeper:高效的,可拓展的协调系统,存储和协调关键共享状态;
(4)HBase是一个开源的,基于列存储模型的分布式数据库;
(5)HDFS是一个分布式文件系统,有着高容错性的特点,适合那些超大数据集的应用程序;
(6)MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。
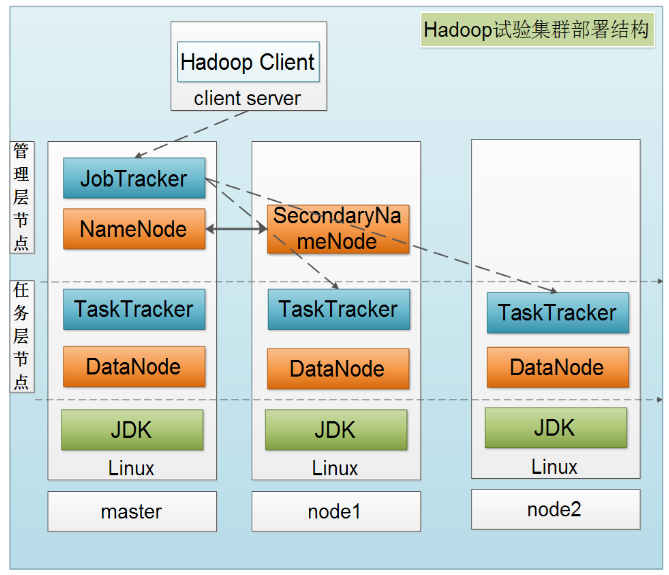
Handoop 集群部署
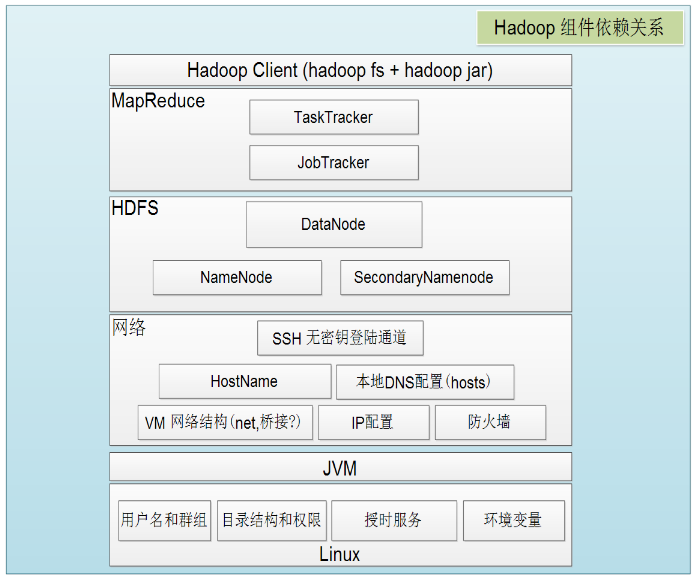
Handoop 组件依赖关系
Handoop的核心

参考资料:
https://blog.csdn.net/zl834205311/article/details/80334346
https://www.cnblogs.com/tieandxiao/p/8799287.html
https://www.jianshu.com/p/d68272609bf8
最新文章
- jsp+servlet+mysql 实现简单的银行登录转账功能
- (转)Java API设计清单
- 票据OCR前预处理 (附Demo)
- --hdu 2124 Repair the Wall(贪心)
- cookie注入的形成,原理,利用总结
- CodeForces 321A
- sql修改表结构、临时表应用
- JavaScript入门介绍(二)
- 利用html+ashx实现aspx的功能
- server配置学习 ---- 关闭防火墙
- ECharts图表系统 特性总览
- JBPM之JPdl小叙
- YYHS-Floor it
- Celery 源码解析五: 远程控制管理
- 最简单的基于libVLC的例子:最简单的基于libVLC的推流器
- [java]final关键字的几种用法
- iframe ios中h5页面 样式变大
- vim编辑器显示行号
- PMP:10.项目采购管理
- python 前端 css