Solr7.2.1环境搭建和配置ik中文分词器
solr7.2.1环境搭建和配置ik中文分词器
安装环境:Jdk 1.8、 windows 10
安装包准备:
solr 各种版本集合下载:http://archive.apache.org/dist/lucene/solr/

tomcat下载(apache-tomcat-8.5.27-windows-x64.zip):https://tomcat.apache.org/download-80.cgi
下载ik分词器:IK Analyzer 2012FF_hf1.zip,这里这个版本已经不能使用,ik-analyzer官网:https://code.google.com/p/ik-analyzer/

这个网站不翻墙是访问不了的,可以去下面这个网站下载:https://www.developerfusion.com/project/41221/ikanalyzer/
IK分词器2012年以后就没有更新过,其所依赖的lucene相关组件的版本为4.X,而solr7.2下面的lucene版本为7.2,会导致分词功能不能正常使用;
解决办法:需要下载以下两个分词jar包solr-analyzer-ik-5.1.0.jar ik-analyzer-solr5-5.x.jar。
下载地址:http://files.cnblogs.com/files/wander1129/ikanalyzer-solr6.5.zip
1、搭建solr环境
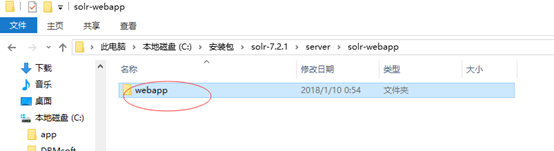
1 解压下载的solr-7.2.1压缩包,将解压后的solr-7.2.1文件夹下server\solr-webapp\webapp文件夹拷贝到tomcat安装目录下的webapps文件夹中,并重命名为solr。如下图:
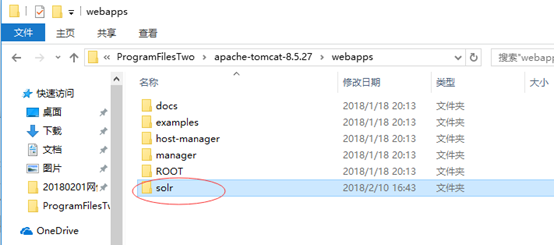
2 创建一个solr_home的文件夹作为solr的安装目录,如:C:\ProgramFilesTwo\solr_home
3 将解压后的solr-7.2.1文件夹下server\lib\ext内的所有jar包、server\lib内以metrics开头的所有jar包,以及gmetric4j-1.0.7.jar复制到tomcat安装目录下的webapps\solr\WEB-INF\lib下。

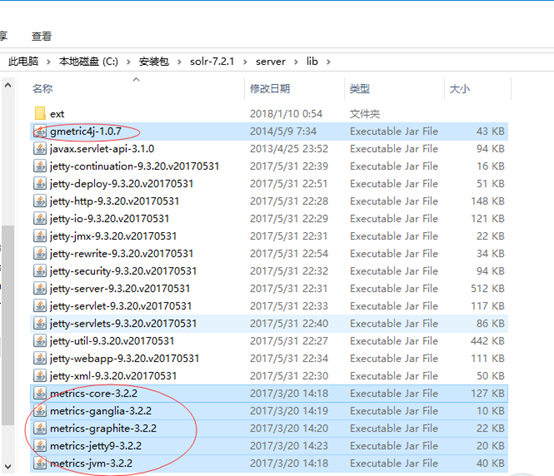
4 在tomcat安装目录下的webapps\solr\WEB-INF中,新建一个classes文件夹,将解压后的solr-7.2.1文件夹下server\resources内的log4j.properties文件拷贝到里面
5 拷贝solr-7.2.1文件夹下server\solr内的所有文件到solr_home的文件夹中(即solr的安装目录)
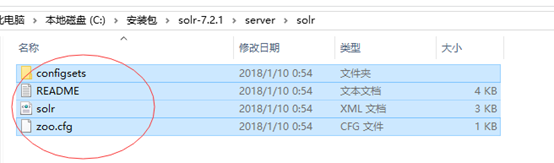
6在solr_home文件夹下新建一个logs文件夹。
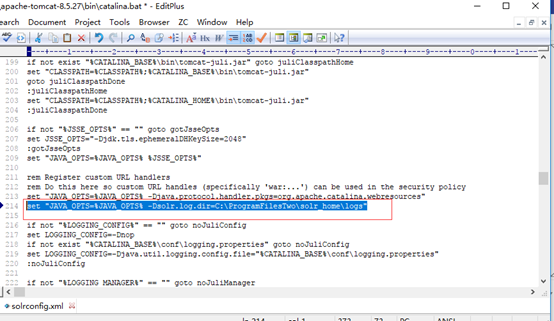
7修改tomcat安装目录下bin文件夹中的catalina.bat,添加solr.log.dir系统变量, 指定solr日志记录存放地址(即上面创建的logs文件夹路径)。例如:
set "JAVA_OPTS=%JAVA_OPTS% -Dsolr.log.dir=C:\ProgramFilesTwo\solr_home\logs"
8.在solr_home文件夹下新建一个new_core文件夹,将解压后的solr-7.2.1文件夹下server\solr\configsets\_default下的conf文件夹拷贝到里面,然后修改conf文件夹里solrconfig.xml文件,如下:
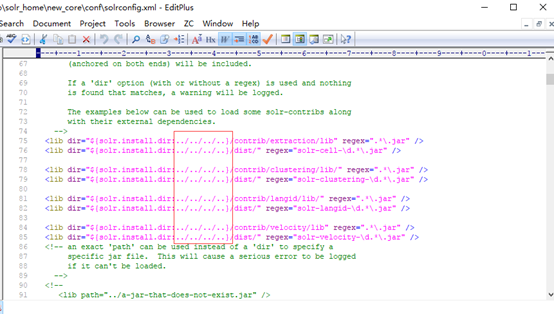
改为:
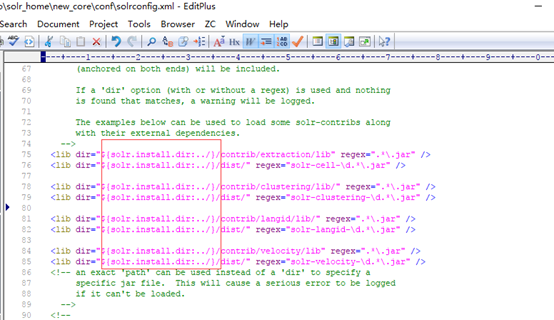
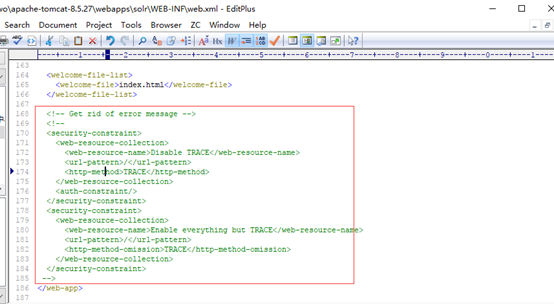
9.修改tomcat安装目录下webapps\solr\WEB-INF内的web.xml文件:
添加内容:

注释内容:
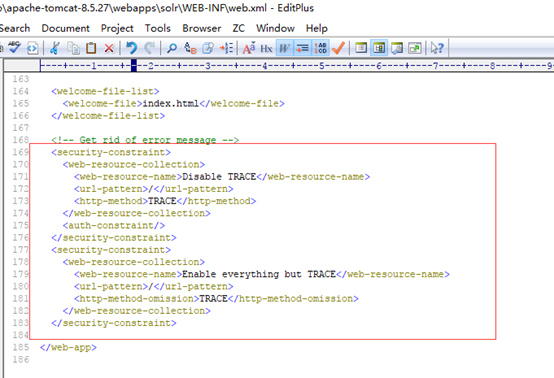
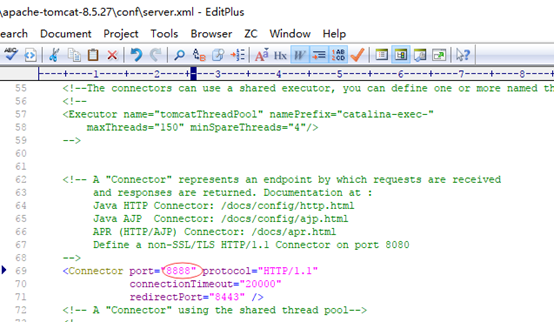
10. 修改端口,默认是8080(看需要设置),修改在tomcat安装目录下conf文件夹内的server.xml文件:
11.查看solr, http://localhost:8888/solr/index.html#/
点击Core Admin菜单,如果没有Core,会弹出如下框,提示添加。
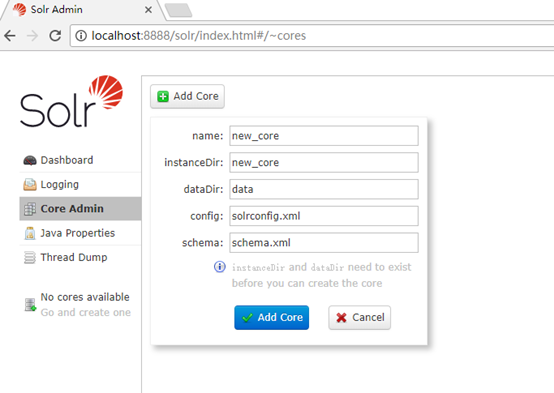
instanceDir: solr安装目录下的new_core文件夹的路径
dataDir: solr安装目录下的new_core\data文件夹的路径
config: solr安装目录下的new_core\conf\solrconfig.xml文件的路径
schema: solr安装目录下的new_core\conf\managed-schema文件的路径
添加以后就可以选择使用了
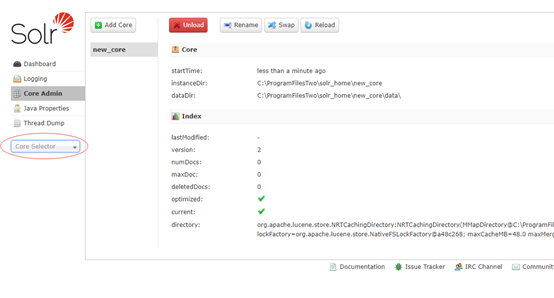
到这里solr的环境就搭建好了,下面开始整合中文分词器;
2、整合分词器
1、使用.solr7.2.1自带的中文分词器
将解压后的solr-7.2.1\contrib\analysis-extras\lucene-libs下的lucene-analyzers-smartcn-7.2.1.jar 放到Tomcat8\webapps\solr\WEB-INF\lib下。

在Tomcat8\solr_h\solrhome\solr_core\conf找到managed-schema 添加已下代码
<fieldType name="text_ik_zd" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.cn.smart.HMMChineseTokenizerFactory"/>
</analyzer>
</fieldType>
重新启动Tomcat8,就可以使用solr自带的分词器了
2、配置ik中文分词器(好处:IKAnalyzer支持屏蔽关键词、新词汇的配置)
解压IK Analyzer 2012FF_hf1压缩包:
ext.dic为扩展字典,改为mydict.dic 这个扩展词收录了搜狗词库
stopword.dic为停止词字典
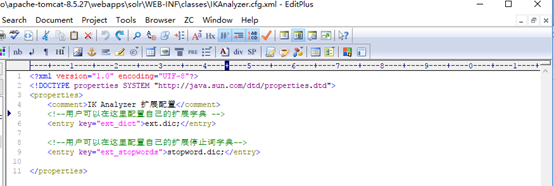
IKAnalyzer.cfg.xml为配置文件
solr-analyzer-ik-5.1.0.jar ik-analyzer-solr5-5.x.jar为分词jar包。
将IK分词器 JAR 包拷贝到C:\ProgramFilesTwo\apache-tomcat-8.5.27\webapps\solr\WEB-INF\lib下
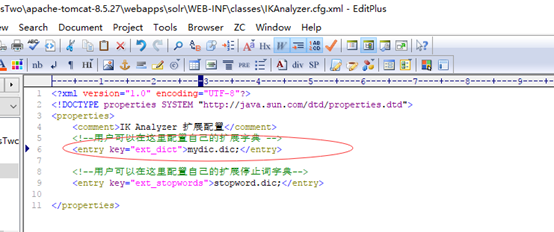
将词典配置文件拷贝到 C:\ProgramFilesTwo\apache-tomcat-8.5.27\webapps\solr\WEB-INF\classes下
更改在C:\ProgramFilesTwo\solr_home\new_core\conf找到managed-schema配置文件,添加以下:
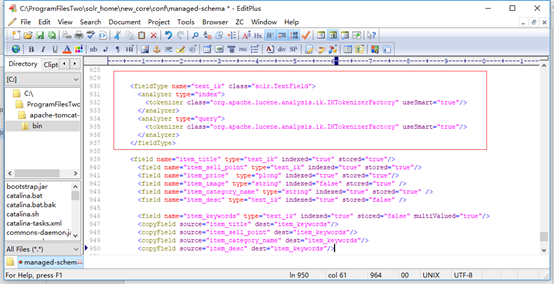
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory" useSmart="true"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory" useSmart="true"/>
</analyzer>
</fieldType>
<field name="item_title" type="text_ik" indexed="true" stored="true"/>
<field name="item_sell_point" type="text_ik" indexed="true" stored="true"/>
<field name="item_price" type="plong" indexed="true" stored="true"/>
<field name="item_image" type="string" indexed="false" stored="true" />
<field name="item_category_name" type="string" indexed="true" stored="true" />
<field name="item_desc" type="text_ik" indexed="true" stored="false" />
<field name="item_keywords" type="text_ik" indexed="true" stored="false" multiValued="true"/>
<copyField source="item_title" dest="item_keywords"/>
<copyField source="item_sell_point" dest="item_keywords"/>
<copyField source="item_category_name" dest="item_keywords"/>
<copyField source="item_desc" dest="item_keywords"/>
重新启动Tomcat8.5.27,就可以使用ik的分词器了
参考博文:
http://blog.csdn.net/lingzhangjie/article/details/79114993
http://blog.csdn.net/m0_37044606/article/details/79155144
https://www.cnblogs.com/kehaocheng/p/8005532.html
最新文章
- python的__future__特性
- CentOS安装开发组相关的包
- Math APP 2.0
- php抽象类的简单应用
- SQL Server数据库(作业讲解和复习)
- Anroid 异常:is not valid; is your activity running?
- [翻译]你不会想知道的kobject,kset,和ktypes
- CentOS系统中常用查看日志命令
- 判断浏览器是否支持某个css3属性的javascript方法
- easyUI的doCellTip 就是鼠标放到单元格上有个提示的功能
- (札记)Java应用架构设计-模块化模式与OSGi
- Visual Studio 中的单元测试 UNIT TEST
- CSS vertical-align属性
- Swiper 判断上滑下拉操作
- 问题1:Oracle数据库监听启动失败(重启监听,提示The listener supports no services)
- GitHub:我们是这样弃用jQuery的
- sticky footer 模板
- [IR] Time and Space Efficiencies Analysis of Full-Text Index Techniques
- tyvj 1031 热浪 最短路
- Java输入输出处理技术2