tensorflow实战笔记(18)----textCNN
一、import 包
import os
import pandas as pd
import csv
import time
import datetime
import numpy as np
import tensorflow as tf
import re
import sys
from __future__ import print_function
import matplotlib.pyplot as plt
from tqdm import tqdm
二、数据处理:
1、问题:将【句子,click label】数据进行点击二分类预测。
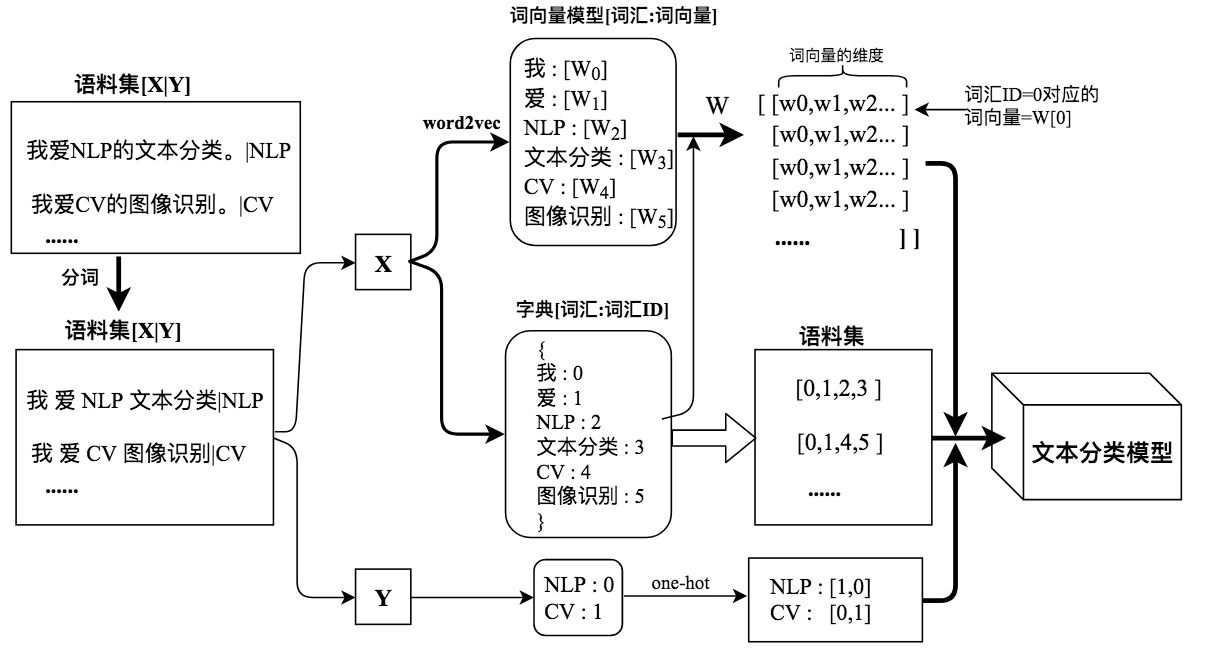
数据:show数据(展示广告log):句子,click数据(点击广告log):句子。还有word2vec一个词向量词典:(词,vec)。
2、由于数据量有点大,总体数据有一亿个样本,其中需要做的数据处理有:
1、show和click数据都去重去空并将show数据进行分词----show:【句子,分词】【在集群上采用pig脚本跑】
2、由于有(show 数据)和(click 数据),两者需要做left Join获取标签,即如果show在click中出现,则其label为1,否则为0。最终数据样本形式为 show:【句子,click label】。
然后对句子的分词进行word count 转化为Word id。
然后将word ID 和Word2vec进行mapping,即【word,ID,vec】,需要放入模型中。
然后将word ID 和 show:【句子,click label】,show:【句子,分词】进行leftJoin以及map,转成【句子,词1ID,词2ID,词3ID……,label】(每个句子固定有36个词,不够则补ID 0,超过则砍掉),需要放入模型中。
Scala代码:
import com.qihoo.spark.app.SparkAppJob
import org.apache.spark.SparkContext
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
import org.kohsuke.args4j.{Option => ArgOption}
import org.apache.spark.sql.functions._ class DataProcessJob extends SparkAppJob {
//input
@ArgOption(name = "-word-vector-input", required = true, aliases = Array("--wordVecInput"), usage = "wordVecInput")
var wordVecInput: String = _
@ArgOption(name = "-sentence-segment-input", required = true, aliases = Array("--sentenceSegInput"), usage = "sentenceSegInput")
var sentenceSegInput: String = _
@ArgOption(name = "-sentence-label-input", required = true, aliases = Array("--sentenceLabelInput"), usage = "sentenceLabelInput")
var sentenceLabelInput: String = _
//output
@ArgOption(name = "-word-id-vector-output", required = true, aliases = Array("--wordIdVecOutput"), usage = "wordIdVecOutput")
var wordIdVecOutput: String = _
@ArgOption(name = "-sentence-ids-label-output", required = true, aliases = Array("--sentenceIdsLabelOutput"), usage = "sentenceIdsLabelOutput")
var sentenceIdsLabelOutput: String = _ override protected def run(sc: SparkContext): Unit = {
import sparkSession.implicits._
val sentenceSegmentRaw = sparkSession.read.text(sentenceSegInput).as[String].filter(_.trim.length() != 0)
sentenceSegmentRaw.show()
val wordVectorRaw = sparkSession.read.text(wordVecInput).as[String].filter(_.trim.length() != 0)
wordVectorRaw.show()
val sentenceLabelRaw = sparkSession.read.text(sentenceLabelInput).as[String].filter(_.trim.length() != 0)
sentenceLabelRaw.show()
val n = 36 val (wordIdVec,sentenceIdsLabel) = wordCountMapVectorJob.getWordId(sparkSession,sentenceSegmentRaw,wordVectorRaw,sentenceLabelRaw,n)
wordIdVec.show()
sentenceIdsLabel.show() val concatWordIdVec = wordIdVec.select(concat_ws("\t", $"word", $"id",$"vec"))
concatWordIdVec.write.text(wordIdVecOutput) val concatSentenceIdsLabel = sentenceIdsLabel.select(concat_ws("\t", $"_1", $"_2",$"_3"))
concatSentenceIdsLabel.write.text(sentenceIdsLabelOutput) }
} object wordCountMapVectorJob {
def getWordId(sparkSession: SparkSession, sentenceSegmentRaw: Dataset[String], wordVectorRaw: Dataset[String], sentenceLabelRaw: Dataset[String], n: Int):(DataFrame,Dataset[(String,String, Int)]) = {
import sparkSession.implicits._ //get wordSegment rows
def sentenceSegmentRows(line: String) = {
val tokens = line.split("\t", 2)
(tokens(0), tokens(1))
} //get wordVec rows
def wordVecRows(line: String) = {
val tokens = line.split(" ", 2)
(tokens(0), tokens(1)) } //get WordsLabel rows
def sentenceLabelRows(line: String) = {
val tokens = line.split("\t")
(tokens(0), tokens(1).toInt) } //wordCount
def wordCountJob(segment: Dataset[String]) = {
val wordCount = segment
.map(line => line.split("\t"))
.flatMap(line => line(1).trim.split(" "))
.groupByKey(value => value)
.count()
.withColumnRenamed("count(1)", "count")
wordCount
} // create three DataFrame
val sentenceSegmentDf = sentenceSegmentRaw.map(sentenceSegmentRows).toDF("sentence", "segment")
val wordVec = wordVectorRaw.map(wordVecRows).toDF("word", "vec")
val sentenceLabelDf = sentenceLabelRaw.map(sentenceLabelRows).toDF("sentence", "label") //get word Id
val wordCount = wordCountJob(sentenceSegmentRaw) val wordCountJoinVec = wordCount.join(wordVec, wordCount("value") === wordVec("word"), "inner") val idDf = Window.partitionBy().orderBy($"value")
val wordVecAddIdDf = wordCountJoinVec.withColumn("id", row_number().over(idDf)) val wordIdVec = wordVecAddIdDf.select("word", "id","vec")
wordIdVec.show()
//get each sentence segment ID and label
val wordDictMap = wordIdVec.map(row => (row.getString(0), row.getInt(1))).rdd.collectAsMap()
val wordDictMapBd = sparkSession.sparkContext.broadcast(wordDictMap) // sentenceSegmentDf left join sentenceLabelDf => ( segment , label )
val segmentLeftJoinLabel = sentenceSegmentDf.join(sentenceLabelDf, sentenceSegmentDf("sentence") === sentenceLabelDf("sentence"), "inner")
segmentLeftJoinLabel.printSchema()
segmentLeftJoinLabel.show() // segmentLabel => ( IDs , label )
val IDLabel = segmentLeftJoinLabel.map { r =>
val ids = r.getString(1).trim().split(" ").map(wordDictMapBd.value.getOrElse(_, 0))
val fixLengthIds = if (ids.length < n) ids.padTo(n, 0) else ids.slice(0, n)
val stringIds = fixLengthIds.mkString(" ")
(r.getString(0),stringIds, r.getInt(3))
}
(wordIdVec , IDLabel) } }
总结:最终放入模型中的数据有:【词1ID,词2ID,词3ID……,label】,【ID,vec】,因为embedding_lookup (【ID,vec】,【词1ID,词2ID,词3ID……,label】)需要这种格式。
3、读入Python中进行的数据处理:
第一次执行Python脚本时:
# load data
train_data = pd.read_csv('./data/train_data/traindata.txt',sep = '\t',quoting = csv.QUOTE_NONE, header = None,names = ['sentence','ids','label']) ## lower_sample 下采样
des = train_data['label'].value_counts()
print("positive number : {:d} and negtive number : {:d} ,pos/neg : {:d} / 1".format(des[1] , des[0] , des[0]/des[1])) def lower_sample(train_data,percent):
pos_data = train_data[train_data['label'] == 1]
neg_data = train_data[train_data['label'] == 0]
neg , pos = len(neg_data), len(pos_data)
index = np.random.choice( neg ,size = percent * pos ,replace = False)
lower_sample = neg_data.iloc[list(index)]
return(pd.concat([pos_data, lower_sample]))
percent = 2
lower_data = lower_sample(train_data,percent)
再优化一下,因为从文本中读取:【句子,词1ID,词2ID,词3ID……,label】还需要进行string.split()处理,还是比较耗时,所以以下代码采用np.save来存储【词1ID,词2ID,词3ID……,label】,这样再采用np.load加载比较快速,而且不包含句子文本数据。
(第一次也要运行)如果是第二次执行该脚本,就直接运行以下代码加载x和y,不用运行上面的代码读取traindata了。
# get data x and y
TRAIN_X_NPY='./data/train_data/train_sequence_data_x.npy'
TRAIN_Y_NPY='./data/train_data/train_sequence_data_y.npy'
SENTENCE_ONLY='./data/train_data/train_sentence_data.txt'
if os.path.exists(TRAIN_X_NPY) and os.path.exists(TRAIN_Y_NPY):
x = np.load(TRAIN_X_NPY)
y = np.load(TRAIN_Y_NPY)
else:
chunksize = train_data.count()[1]
ndim = 36
y = np.array(train_data['label'])
x = np.zeros((chunksize, ndim))
for i,line in tqdm(enumerate(train_data['ids'])):
x[i] = np.array(list(map(int,line.strip().split(" "))))
np.save(TRAIN_X_NPY, x)
np.save(TRAIN_Y_NPY, y)
text_data = list(train_data['sentence'])
with open(SENTENCE_ONLY, 'w') as f:
for line in text_data:
f.write(line)
f.write('\n') ## data x and y lower sample
pos_indices = [index for index,label in enumerate(list(y)) if label > 0]
neg_indices = [index for index, label in enumerate(list(y)) if label <= 0]
sampled_neg_indices = np.random.choice(neg_indices, len(neg_indices) / 5, replace=False)
x = np.concatenate((x[sampled_neg_indices],x[pos_indices]), axis=0)
y = np.concatenate((y[sampled_neg_indices],y[pos_indices]))
print('sampled shape: x %d, %d, y %d' % (x.shape[0], x.shape[1], y.shape[0]))
加载【ID,vec】词向量
# embedding_map
EMBEDDING_SIZE = 100
embedding_map = pd.read_csv('./data/train_data/idvec.txt',sep = '\t',quoting = csv.QUOTE_NONE, header = None,names = ['word','id','vec'])
embedded_rows = embedding_map.count()[1]
embedding_map = embedding_map.sort_values(by = 'id')
embedded_mat = np.zeros((embedded_rows + 1, EMBEDDING_SIZE))
def get_embedded_mat(embedding_map , embedded_rows , EMBEDDING_SIZE):
for i,line in enumerate(embedding_map['vec']):
if i != 0:
embedded_mat[i] = np.array(list(map(float,line.strip().split(' '))))
return embedded_mat
embedded_mat = get_embedded_mat(embedding_map , embedded_rows , EMBEDDING_SIZE)
shuffle数据集和切分训练集和测试集,注意测试集不要分太大,本来分了79万数据,(dev_sample_ratio = 0.05),training时报错:resource ehxousted error,训练test step时会OOM。
# Data Preparation
# ================================================== # Randomly shuffle data
np.random.seed(100)
dev_sample_ratio = 0.01
n = len(y) ## undersample
indices = [i for i in range(n)] shuffle_indices = np.random.permutation(indices)
x_shuffled = [x[i] for i in shuffle_indices]
y_shuffled = [y[i] for i in shuffle_indices] # Split train/test set
# TODO: This is very crude, should use cross-validation
dev_sample_index = np.int(dev_sample_ratio * len(shuffle_indices))
x_dev, x_train = x_shuffled[:dev_sample_index], x_shuffled[dev_sample_index:]
y_dev, y_train = y_shuffled[:dev_sample_index], y_shuffled[dev_sample_index:] # del x, y, x_shuffled, y_shuffled
## train_pos : train_neg = 2037815 : 11109457 = 5
## Test_pos : Test_neg: 226257 : 1234551 = 5
print("Train/Dev split: {:d}/{:d}".format(len(y_train), len(y_dev)))
print("Train_pos and Train_neg: {:f} {:f}".format(int(sum(y_train)) , int(len(y_train)-sum(y_train))))
print("Test_pos and Test_neg: {:f} {:f}".format(int(sum(y_dev)) , int(len(y_dev)-sum(y_dev))))
print("Test_neg / Test_all: {:f}".format((len(y_dev)-sum(y_dev))/float(len(y_dev))))
三、模型搭建

class TextCNN(object):
"""
A CNN for text classification.
Uses an embedding layer, followed by a convolutional, max-pooling and softmax layer.
"""
def __init__(
self, sequence_length, num_classes, embedding_size, filter_sizes,
num_filters, embedding_matrix, early_stop_steps=3000, learning_rate = 0.01,
nRestarts = 10, restart = 0, l2_reg_lambda=0.0): # Placeholders for input, output and dropout
self.input_x = tf.placeholder(tf.int64, [None, sequence_length], name="input_x")
self.input_y = tf.placeholder(tf.int64, [None, num_classes], name="input_y")
self.dropout_keep_prob = tf.placeholder(tf.float32, name="dropout_keep_prob")
self.best_dev_tstep = 0
self.best_dev_loss = 999
self.learning_rate = learning_rate
self.best_model_path = ''
self.early_stop_steps = early_stop_steps
self.restart = restart
self.nRestarts = nRestarts # Keeping track of l2 regularization loss (optional)
l2_loss = tf.constant(0.0) # Embedding layer for fine-tune
with tf.device('/gpu:0'), tf.name_scope("embedding"):
self.W = tf.Variable(
tf.constant(embedding_matrix, dtype=tf.float32, name='pre_weights'),
name="W", trainable=True)
self.embedded_chars = tf.nn.embedding_lookup(self.W, self.input_x)
self.embedded_chars_expanded = tf.expand_dims(self.embedded_chars, -1) # Create a convolution + maxpool layer for each filter size
pooled_outputs = []
for i, filter_size in enumerate(filter_sizes):
with tf.name_scope("conv-maxpool-%s" % filter_size):
# Convolution Layer
filter_shape = [filter_size, embedding_size, 1, num_filters]
W = tf.Variable(tf.truncated_normal(filter_shape, stddev=0.1), name="W")
b = tf.Variable(tf.constant(0.1, shape=[num_filters]), name="b")
conv = tf.nn.conv2d(
self.embedded_chars_expanded,
W,
strides=[1, 1, 1, 1],
padding="VALID",
name="conv")
# Apply nonlinearity
h = tf.nn.relu(tf.nn.bias_add(conv, b), name="relu")
# Maxpooling over the outputs
pooled = tf.nn.max_pool(
h,
ksize=[1, sequence_length - filter_size + 1, 1, 1],
strides=[1, 1, 1, 1],
padding='VALID',
name="pool")
pooled_outputs.append(pooled) # Combine all the pooled features
num_filters_total = num_filters * len(filter_sizes)
self.h_pool = tf.concat(pooled_outputs, 3)
self.h_pool_flat = tf.reshape(self.h_pool, [-1, num_filters_total]) # Add dropout
with tf.name_scope("dropout"):
self.h_drop = tf.nn.dropout(self.h_pool_flat, self.dropout_keep_prob) # Final (unnormalized) scores and predictions
with tf.name_scope("output"):
W = tf.get_variable(
"W",
shape=[num_filters_total, num_classes],
initializer=tf.contrib.layers.xavier_initializer())
b = tf.Variable(tf.constant(0.1, shape=[num_classes]), name="b")
l2_loss += tf.nn.l2_loss(W)
l2_loss += tf.nn.l2_loss(b) self.scores = tf.sigmoid(tf.nn.xw_plus_b(self.h_drop, W, b, name="scores"), name="sigmoid_scores")
self.predictions = tf.cast(self.scores > 0.5, tf.int64,name = "predictions") # Calculate mean cross-entropy loss
with tf.name_scope("loss"):
losses = tf.nn.sigmoid_cross_entropy_with_logits(logits=self.scores, labels=tf.cast(self.input_y, tf.float32))
self.loss = tf.reduce_mean(losses) + l2_reg_lambda * l2_loss # Accuracy
with tf.name_scope("accuracy"):
corrected_prediction = tf.equal(self.predictions, self.input_y)
self.accuracy = tf.reduce_mean(tf.cast(corrected_prediction, tf.float32), name="accuracy")
三、训练模型
tf.nn.conv2d( input,filter,strides,padding,use_cudnn_on_gpu=True,data_format='NHWC',dilations=[1, 1, 1, 1],name=None)
input tensor shape:[batch, in_height, in_width, in_channels]
filter tensor shape:[filter_height, filter_width, in_channels, out_channels]
##取batch_size数据
def batch_iter_for_list(x_train, y_train, batch_size = 512, num_epochs = 50, shuffle = True):
num_data = len(y_train)
num_batches_per_epoch = int((len(y_train)-1) / batch_size) + 1
for epoch in range(num_epochs):
print("===============epoch{}===============".format(epoch + 1))
for batch_num in range(num_batches_per_epoch):
start_index = batch_num * batch_size
end_index = min((batch_num + 1) * batch_size, num_data)
yield x_train[start_index:end_index], np.array(y_train[start_index: end_index]).reshape(-1, 1) # Training
# ==================================================
if __name__ == '__main__':
filter_size = [1,2,3, 5]
nfilter = 100
ndim = 36
num_classes = 1
# vocab_length = embedding_map.count()[0]
EMBEDDING_SIZE = 100
early_stop_steps = -1
l2_reg_lambda=0.0
nRestarts = 8 # reduce on plateau, the best checkpoint will be restored and the
#learning rate will be halved
# reset_graph()
embedding_matrix_rand = np.random.normal(size = embedded_mat.shape) with tf.Graph().as_default(): os.environ["CUDA_VISIBLE_DEVICES"] = ""
config = tf.ConfigProto()
# config.gpu_options.per_process_gpu_memory_fraction = 0.5
config.gpu_options.allow_growth=True # allocate when needed sess = tf.Session(config = config)
with sess.as_default():
global_step = tf.Variable(0, name="global_step", trainable=False)
learning_rate = tf.train.exponential_decay(0.1,global_step,1000,0.96,staircase = True) cnn = TextCNN(
sequence_length = ndim,
# vocab_length = vocab_length,
num_classes = num_classes,
embedding_size = EMBEDDING_SIZE,
filter_sizes = filter_size,
num_filters = nfilter,
embedding_matrix = embedded_mat,
early_stop_steps = early_stop_steps,
learning_rate = learning_rate,
nRestarts = nRestarts,
l2_reg_lambda = l2_reg_lambda) # Define Training procedure
# 定义GD优化器
# optimizer = tf.train.GradientDescentOptimizer(cnn.learning_rate)
optimizer = tf.train.AdamOptimizer()
grads_and_vars = optimizer.compute_gradients(cnn.loss)
train_op = optimizer.apply_gradients(grads_and_vars, global_step=global_step) # Output directory for models and summaries
timestamp = str(int(time.time()))
out_dir = os.path.abspath(os.path.join(os.path.curdir, "runs", timestamp))
print("Writing to {}\n".format(out_dir)) # Summaries for loss and accuracy
loss_summary = tf.summary.scalar("loss", cnn.loss)
acc_summary = tf.summary.scalar("accuracy", cnn.accuracy) # Train Summaries
# train_summary_op = tf.summary.merge([loss_summary, acc_summary, grad_summaries_merged])
train_summary_op = tf.summary.merge([loss_summary, acc_summary])
train_summary_dir = os.path.join(out_dir, "summaries", "train")
train_summary_writer = tf.summary.FileWriter(train_summary_dir, sess.graph) # Dev summaries
dev_summary_op = tf.summary.merge([loss_summary, acc_summary])
dev_summary_dir = os.path.join(out_dir, "summaries", "dev")
dev_summary_writer = tf.summary.FileWriter(dev_summary_dir, sess.graph) # Checkpoint directory. Tensorflow assumes this directory already exists so we need to create it
checkpoint_dir = os.path.abspath(os.path.join(out_dir, "checkpoints"))
checkpoint_prefix = os.path.join(checkpoint_dir, "model")
if not os.path.exists(checkpoint_dir):
os.makedirs(checkpoint_dir)
saver = tf.train.Saver(tf.global_variables(), max_to_keep=1) # Write vocabulary
# vocab_processor.save(os.path.join(out_dir, "vocab")) # Initialize all variables
sess.run(tf.global_variables_initializer()) def train_step(x_batch, y_batch, writer=None):
"""
A single training step
"""
feed_dict = {
cnn.input_x: x_batch,
cnn.input_y: y_batch,
cnn.dropout_keep_prob: 0.8
}
_, step, loss, accuracy , predictions , scores, train_summary = sess.run(
[train_op, global_step, cnn.loss, cnn.accuracy , cnn.predictions , cnn.scores, train_summary_op],
feed_dict)
time_str = datetime.datetime.now().isoformat()
if step % 10 == 0:
print("train: {}: step {}, loss {:g}, acc {:g}".format(time_str, step, loss, accuracy))
if writer:
writer.add_summary(train_summary, step) def dev_step(x_batch, y_batch, writer=None):
"""
Evaluates model on a dev set
"""
feed_dict = {
cnn.input_x: x_batch,
cnn.input_y: y_batch,
cnn.dropout_keep_prob: 1.0
}
step, summaries, loss, accuracy = sess.run(
[global_step, dev_summary_op, cnn.loss, cnn.accuracy],
feed_dict)
if loss < cnn.best_dev_loss:
cnn.best_dev_loss = loss
cnn.best_dev_tstep = step
if step > 100: # min steps to checkpoint
path = saver.save(sess, checkpoint_prefix, global_step=step)
cnn.best_model_path = path
if step % 100 == 0:
print("val-loss {} Saved model checkpoint to {}\n".format(loss, path)) time_str = datetime.datetime.now().isoformat()
print("val: {}: step {}, loss {:g}, acc {:g}".format(time_str, step, loss, accuracy))
if writer:
writer.add_summary(summaries, step)
# print cnn.nRestarts, cnn.restart, cnn.best_dev_loss, cnn.best_dev_tstep, cnn.best_model_path
# early stopping
if cnn.early_stop_steps > 0:
if step - cnn.best_dev_tstep > cnn.early_stop_steps:
if cnn.restart >= cnn.nRestarts:
print('best validation loss of {} at training setp {}'.format(
cnn.best_dev_loss, cnn.best_dev_tstep))
print('early stopping: end training.')
return True
else:
if len(cnn.best_model_path) == 0:
print('Not find best model: end training.')
return True
else:
print('restore best model from ' + cnn.best_model_path + 'at step '\
+ str(cnn.best_dev_tstep))
saver.restore(sess, cnn.best_model_path)
cnn.learning_rate /= 2.0
cnn.early_stop_steps /= 2
step = cnn.best_dev_tstep
cnn.restart += 1
return False
else:
return False
else:
return False # Generate batches
batches = batch_iter_for_list(x_train, y_train, batch_size = 512 , num_epochs = 1000)
y_dev_input = np.array(y_dev).reshape(-1, 1)
# Training loop. For each batch...
for batch_index, (x_batch, y_batch) in enumerate(batches):
train_step(x_batch, y_batch, writer=train_summary_writer)
if batch_index % 100 == 0:
early_stop_flag = dev_step(x_dev, y_dev_input, writer=dev_summary_writer)
if early_stop_flag:
break
最后train loss收敛在0.63左右,acc最好在0.90,一般为0.85。
val loss收敛在0.63,acc收敛在0.85左右。
参考:
http://www.yidianzixun.com/article/0KNcfHXG
最新文章
- window7系统怎么找到开始运行命令
- weapp微信小程序初探demo
- Android自学指导
- [新手学Java]使用内省(Introspector)操作JavaBean属性
- wpfのpack协议
- HDU 2544 最短路【Bellman_Ford 】
- django基本命令备忘录
- android 再按一次退出程序(实现代码)
- Oracle日志性能查看
- 12,C++中 .* 可以出现在什么地方?有何作用?
- ASP.NET MVC 实现AJAX跨域请求的两种方法
- json中文乱码问题
- 重新认识一个强大的 Gson
- ansible服务部署与使用
- Arduino入门笔记(6):温度传感器及感温杯实验
- ES查询-term VS match (转)
- IE6下select被这罩住
- RecyclerView 使用指南
- jsp的9大内置对象和4大作用域
- websevice之三要素