Scrapy里Selectors 四种基础的方法
2024-09-06 05:17:15
在Scrapy里面,Selectors 有四种基础的方法
xpath():返回一系列的selectors,每一个select表示一个xpath参数表达式选择的节点
css():返回一系列的selectors,每一个select表示一个css参数表达式选择的节点
extract():返回一个unicode字符串,为选中的数据
re():返回一串一个unicode字符串,为使用正则表达式抓取出来的内容
/html/head/title: 选择HTML文档<head>元素下面的<title> 标签。
/html/head/title/text(): 选择前面提到的<title> 元素下面的文本内容
//td: 选择所有 <td> 元素
//div[@class="mine"]: 选择所有包含 class="mine" 属性的div 标签元素
以上只是几个使用XPath的简单例子,但是实际上XPath非常强大。
可以参照W3C教程
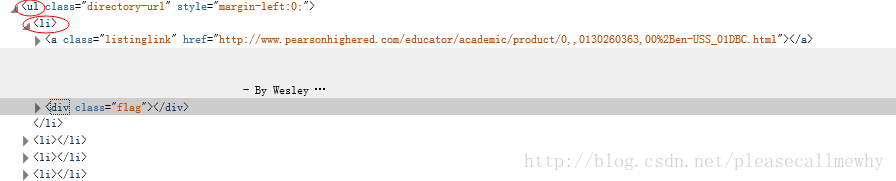
我们可以用如下代码来抓取这个<li>标签:
sel.xpath('//ul/li')
从<li>标签中,可以这样获取网站的描述:
sel.xpath('//ul/li/text()').extract()
可以这样获取网站的标题:
sel.xpath('//ul/li/a/text()').extract()
可以这样获取网站的超链接:
sel.xpath('//ul/li/a/@href').extract()
最新文章
- 【less】Bootstrap / Less 学习
- 简化MSI在WIN10的安装
- Mac 使用 SSH 免密连接服务器
- Noip2016提高组 组合数问题problem
- XE随想4:SuperObject增、删、改
- python类的特性
- node express 学习2
- 题解西电OJ (Problem 1005 -跳舞毯)--动态规划
- Linux 多线程调试(内存占用、死循环、CPU占用率高……)
- COJ 0034 动态的数字三角形
- swift 随机数
- 整合 新浪 腾讯 人人 qq空间 分享地址
- HDOJ 1217 Floyed Template
- 奇葩的UI引用LayoutInflater.from问题
- 使用STM8SF103 ADC采样电压(转)
- Vue-cli安装教程
- [HNOI 2016]大数
- 软件测试-Svn服务器搭建全过程-基于Centos6.7-64bit
- wpf 给listview的数据源转换为集合
- Chapter3_操作符_其他操作符