GIL 信号量 event事件 线程queue
2024-08-27 09:20:36
GIL全局解释器锁
官方解释:
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple
native threads from executing Python bytecodes at once. This lock is necessary mainly
because CPython’s memory management is not thread-safe.
大译:
python解释器有很多种 最常见的就是Cpython解释器
GIL本质也是一把互斥锁:将并发变成串行牺牲效率保证数据的安全
用来阻止同一个进程下的多个线程的同时执行(同一个进程内多个线程无法实现并行但是可以实现并发)
GIL的存在是因为CPython解释器的内存管理不是线程安全的,这种不安全是来自于垃圾回收机制,每个进程下都会有一个内存管理线程

在一个python的进程内,不仅有test.py的主线程或者由该主线程开发的其他线程,还有解释器开启的来及回收等解释器级别的线程,总之,所有线程都运行在这一个进程内. 所有线程的任务,都需要将代码传给解释器去执行,所以首先要解决的是能够访问到解释器代码
如果多个线程的target = work name执行流程是: 多个线程先访问到解释器的代码,即拿到执行权限,然后将target的代码交给解释器的代码执行,解释器的代码是所有线程共享的,所以来及回收线程也可能访问到解释器的代码而去执行,
这就导致了一个问题:对于共一个数据 100,在线程1执行x = 100的同时,垃圾回收机制执行的是回收100的操作,所以需要通过添加GIL锁,保证python解释器同一时间只能执行一个任务代码

问题: python的多线程没法利用多个优势,是不是就没用了
答: 研究python的多线程是否有用需要分情况讨论
例: 1.四个计算密集型任务, 每个10s 单核情况: 开线程更省资源 多核情况: 开进程 10s 开线程 40s 2.四个IO密集型任务, 每个10s 单核情况: 开线程更省资源 多核情况: 开线程更省资源
from multiprocessing import Process
from threading import Thread
import time, os
# 计算密集型
def func():
res = 0
for i in range(10000):
res *= 1
# IO 密集型
def func():
time.sleep(3)
if __name__ == '__main__':
print(os.cpu_count())
list = []
start = time.time()
for i in range(4):
p = Process(target=func) # 多进程
# 计算密集型运行时间:0.21994638442993164
# IO密集型运行时间:3.2253575325012207
p = Thread(target=func) # 多线程
# 运行时间:0.003988504409790039
# IO密集型运行时间:3.0033791065216064
list.append(p)
p.start()
for p in list:
p.join() # 等待所有子进程/子线程运行结束后再运行主进程/主线程
end = time.time()
print('运行时间:%s'%(end - start))
死锁/递归锁
指的是两个进程或线程在执行的过程中,因争抢资源而造成的一种互相等待的现象.
注意: 自己千万不要轻易处理锁
Rlock 递归锁
Rlock可以被第一个抢到锁的人连续的acquire和release
每acquire一次,锁身上的计数加一
每release一个,锁身上的计数减一
只要锁的计数不为0,其他进程/线程都不能抢
from threading import Thread, Lock
import time
# 生成两把锁
mutexA = Lock()
mutexB = Lock()
class MyThread(Thread):
def run(self):
self.func1()
self.func2()
def func1(self):
mutexA.acquire()
print('%s抢到了A锁'%self.name) # self.name 等价于 current_thread(),name
mutexB.acquire()
print('%s抢到了B锁' % self.name)
mutexB.release()
print('%s释放了B锁' % self.name)
mutexA.release()
print('%s释放了A锁' % self.name)
def func2(self):
mutexB.acquire()
print('%s抢到了B锁' % self.name)
time.sleep(1)
mutexA.acquire()
print('%s抢到了A锁' % self.name)
mutexA.release()
print('%s释放了A锁' % self.name)
mutexB.release()
print('%s释放了B锁' % self.name)
for i in range(10):
t = MyThread()
t.start()
# 递归锁
from threading import Thread, RLock
mutexA = mutexB = RLock()
class MyThread(Thread):
def run(self):
self.func1()
self.func2()
def func1(self):
mutexA.acquire()
print('%s抢到了A锁'%self.name) # self.name 等价于 current_thread(),name
mutexB.acquire()
print('%s抢到了B锁' % self.name)
mutexB.release()
print('%s释放了B锁' % self.name)
mutexA.release()
print('%s释放了A锁' % self.name)
def func2(self):
mutexB.acquire()
print('%s抢到了B锁' % self.name)
time.sleep(1)
mutexA.acquire()
print('%s抢到了A锁' % self.name)
mutexA.release()
print('%s释放了A锁' % self.name)
mutexB.release()
print('%s释放了B锁' % self.name)
for i in range(10):
t = MyThread()
t.start()
信号量
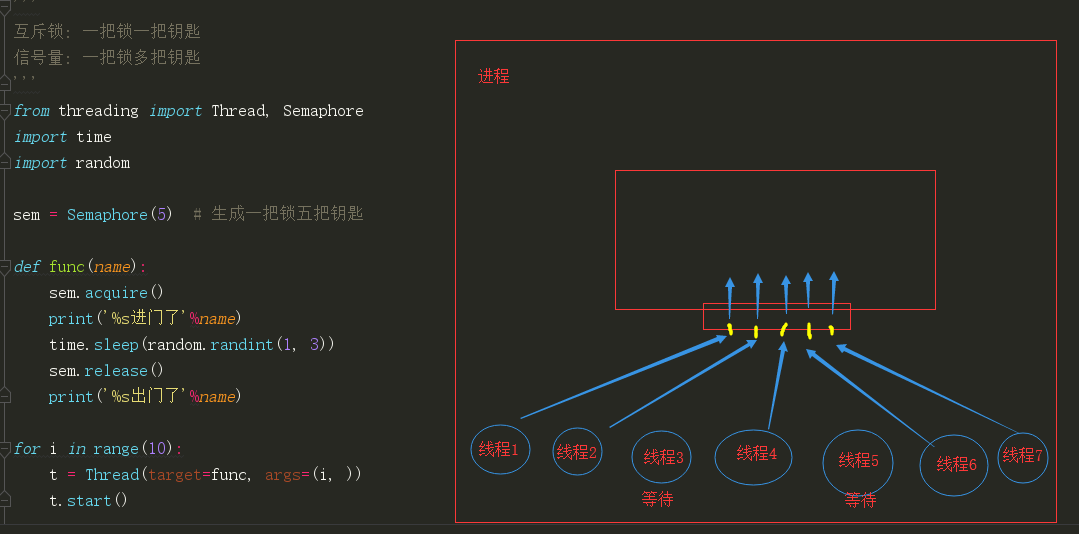
互斥锁: 一把锁一把钥匙
信号量: 一把锁多把钥匙
from threading import Thread, Semaphore
import time
import random
sem = Semaphore(5) # 生成一把锁五把钥匙
def func(name):
sem.acquire()
print('%s进门了'%name)
time.sleep(random.randint(1, 3))
sem.release()
print('%s出门了'%name)
for i in range(10):
t = Thread(target=func, args=(i, ))
t.start()

event事件
e.set() 发信号
e.wait() 等待信号
from threading import Thread, Event
import time
e = Event()
def light():
print('红灯')
time.sleep(3)
e.set()
print('绿灯')
def car(name):
print('%s等红灯'%name)
e.wait()
print('%s开车了'%name)
t = Thread(target=light)
t.start()
for i in range(10):
t = Thread(target=car, args=('车手%i'%i, ))
t.start()
线程queue
同一个进程下的多个线程本来就是数据共享,为什么还要用队列?
因为队列是 管道+锁,使用队列就不需要自己动手操作锁的问题
import queue
q = queue.Queue()
q.put('one')
q.put('two')
q.put('three')
print(q.get()) # >>> one 先进先出
q = queue.LifoQueue()
q.put('one')
q.put('two')
q.put('three')
print(q.get()) # >>> three 堆栈 先进后出
q = queue.PriorityQueue() # 数字越小,优先级越高
q.put((10, 'one'))
q.put((1, 'two'))
q.put((5, 'three'))
print(q.get()) # >>> (1, 'two')
最新文章
- 关于input的file框onchange事件触发一次失效的新的解决方法
- sublime Text3使用笔记
- Ajax异步调用使用
- java技术知识点
- c#中使用servicestackredis操作redis
- node.js在windows下的学习笔记(5)---用NODE.JS创建服务器和客户端
- 《C#并行编程高级教程》第3章 命令式任务并行 笔记
- Java中关键字super与this的区别
- 高速排序-c++(分别用数组和容器实现)
- 《JavaScript权威指南》读书笔记2
- Alamofire源码解读系列(七)之网络监控(NetworkReachabilityManager)
- css自适应
- pyinstaller 工具起步
- MySQL分布式事物(XA事物)的使用
- linux(fedora) 第三课
- jQuery的addClass,removeClass和toggleClass方法
- quake3中求1/sqrt(x)的算法源代码
- mysql数据库中查看当前使用的数据库是哪个数据库?
- 第三百零九节,Django框架,models.py模块,数据库操作——F和Q()运算符:|或者、&并且——queryset对象序列化
- 设计一个栈,设计一个max()函数,求当前栈中的最大元素