12、基于yarn的提交模式
2024-10-21 06:34:03
一、三种提交模式
1、Spark内核架构,其实就是第一种模式,standalone模式,基于Spark自己的Master-Worker集群。 2、第二种,是基于YARN的yarn-cluster模式。 3、第三种,是基于YARN的yarn-client模式。 4、如果,你要切换到第二种和第三种模式,很简单,将我们之前用于提交spark应用程序的spark-submit脚本,加上--master参数,设置为yarn-cluster,或yarn-client,即可。
如果你没设置,那么,就是standalone模式。
二、基于YARN的提交模式
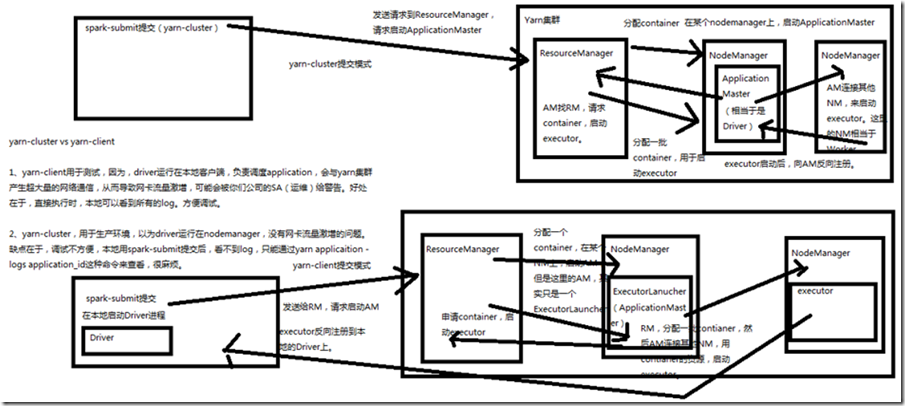
1、基于YARN的yarn-cluster模式
流程详细分析: spark-submit提交(yarn-cluster),发送请求到ResourceManager,请求启动ApplicationMaster,ResourceManager接收到请求后,会在某个NodeManager上分配container,启动ApplicationMaster
ResourceManager分配Container,在某个NodeManager上,启动ApplicationMaster ApplicationMaster(相当于是Driver) ApplicationMaster找ResourceManager,请求container,启动Executor ResourceManager分配一批container,用于启动Executor
ApplicationMaster所在的NodeManager上,可能会启动Executor ApplicationMaster连接其他NodeManager,来启动Executor,这里的NameNode相当于Wroker
Executor启动后,向ApplicationMaster反向注册
2、基于YARN的yarn-client模式
流程详细分析:
spark-submit提交(yarn-client),会在本地启动Driver进程
发送给ResourceManager,请求启动ApplicationMaster ResourceManager分配Container,在某个NodeManager上启动ApplicationMaster,但这里的ApplicationMaster,其实只是一个ExecutorLauncher ExecutorLauncher(ApplicationMaster)申请Container,启动executor ResourceManager分配一批Container
,ExecutorLauncher(ApplicationMaster)所在的NodeManager上,可能会启动Executor ExecutorLauncher(ApplicationMaster)连接其他NodeManager,用Container资源,启动Executor
Executor反向注册到本地的Driver上
3、以上两种模式对比
1、yarn-client模式用于测试,因为driver运行在本地客户端,负责调度application,会与yarn集群产生超大量的网络通信,从而导致网卡流量激增,
可能会被公司的运维给警告,好处在于,直接执行时,本地可以看到所有log,方便调试 2、
yarn-cluster,用于生产环境,因为driver运行在NodeManager,没有网卡流量激增的问题,缺点在于,调试不方便,本地用spark-submit提交后,看不到log,
只能通过yarn application -logs application_id这种命令来查看,很麻烦
4、设置
##修改spark-env.sh
[root@spark1 ~]# vim /usr/local/spark/conf/spark-env.sh #写入hadoop的home
export HADOOP_HOME=/usr/local/hadoop ###脚本文件 yarn-cluster: /opt/module/spark/bin/spark-submit \ --class com.zj.spark.core.WordCountCluster \ --master yarn-cluster \ --num-executors 3 \ --driver-memory 100m \ --executor-memory 100m \ --executor-cores 3 \
/opt/module/datas/sparkstudy/java/mysparkstudy-1.0-SNAPSHOT-jar-with-dependencies.jar \ yarn-client:
/opt/module/spark/bin/spark-submit \ --class com.zj.spark.core.WordCountCluster \ --master yarn-client \ --num-executors 3 \ --driver-memory 100m \ --executor-memory 100m \ --executor-cores 3 \ /opt/module/datas/sparkstudy/java/mysparkstudy-1.0-SNAPSHOT-jar-with-dependencies.jar \
最新文章
- CSS Position 定位属性
- iOS键盘监听的通知
- 简明python教程 --C++程序员的视角(一):数值类型、字符串、运算符和控制流
- TYVJ P1016 装箱问题 Label:01背包 DP
- 将COleDateTime类型数据转换成char *数据
- Wix#可以直接写C#代码来生成Wix的MSI安装文
- Nodejs负载均衡:haproxy,slb以及node-slb - i5ting的个人空间 - 开源中国社区
- C#反射 获取程序集信息和通过类名创建类实例(转载)
- Eclipse --Type /com.xx.app/gen already exists but is not a source folde解决方案
- OpenStack调研
- Linux下查看access访问日志IP统计命令
- Python——正则表达式
- python日常小计
- vlc-ts
- Ionic异常及解决
- MT【40】一道联赛二试题
- K8S 使用简单的NFS 作为 持久存储的 StorageClass 的简单测试.
- [数据库]_[初级]_[sqlite3简单使用]
- Spring启动时获取自定义注解的属性值
- 20145217《网络对抗》 逆向及BOF进阶实践学习总结