Oracle入门笔记 ——启动进阶
1.2 进阶内容:
两个概念:SCN 和 检查点
1.SCN的定义:
system change member ,系统改变号,是数据库中非常重要的一个数据结构。
SCN 用以标示数据库在某个确切时刻提交的版本。在事务提交时,它被赋予一个唯一的标识事务的SCN 。SCN同时被作为Oracle数据库的内部时钟机制,可被看做逻辑时钟,每个数据库都有一个全局的SCN生成器。
作为数据库内部的逻辑时钟,数据库事务依SCN而排序,ORACLE也依据SCN来实现一致性读(Read Consistency)等重要数据库功能。另外对分布式事务(Distributed Transactions),SCN也极为重要。
SCN在数据库中是唯一的,并随时间而增加,但是可能并不连贯。除非重建数据库,SCN的值永远不会被重置为零。
重要的是:1.SCN是Oracle的内部时钟机制;2.通过SCN来维护数据的一致性;3.通过SCN实现Oracle至关重要的恢复机制;
常见的事务表、控制文件、数据文件头、日志文件、数据块头等都有记录SCN值。
冠以不同的前缀,SCN有不同名称,如检查点SCN(Checkpoint SCN)、Resetlogs SCN等。
2.SCN的获取方式:
可以通过以下方式获取数据库当前的或近似的SCN.
从Oracle i9开始,可以使用 dbms_flashback.get_system_change_number 来获得:
select dbms_flashback.get_system_change_number from dual;
3.SCN的进一步说明:
系统的SCN并不是时时改变,通常在事务提交或回滚时改变。在控制文件,数据文件头、数据块、日志文件头、日志文件change vector中都有SCN,但是作用各不相同。
(1)数据头文件中包含了改数据文件的Checkpoint SCN ,表示该数据文件最近一次执行检查点操作的SCN.
从控制文件的dump文件,看到内容:

对于每一个数据文件都包含一个这样的条目,记录该文件的检查点SCN的值以及检查点发生时间,这里的Checkpint SCN, Stop SCN以及Checkpoint Cnt 都是非常重要的数据结构。
(2) 日志文件头包含了 Low SCN 和 Next SCN
Low SCN 和 Next SCN 这两个SCN表示该日志文件包含有介于 Low SCN 和 Next SCN 的重做信息,对于Current的日志文件(当前正在被使用的 Redo Logfile) ,最终的SCN不可知,所以SCN被置为无穷大,ffffffff;

1.2.2 检查点 :
1.检查点(Checkpoint)的本质:
检查点只是一个数据库事件,它存在的根本意义在于减少奔溃恢复的(Crash Recovery)时间。
当修改数据时,需要首先将数据读入内存中(Buffer Cache),修改数据的同时,Oracle会记录重做信息(Redo)用于恢复。因为有了重做信息的存在,Oracle不需要在提交时立即将变化的数据写入磁盘(立即写的效率会很低),
重做的存在正是为了在数据库奔溃之后,数控可以恢复。
最常见的情况,数据库可能因为断电而Crash,那么内存中修改过的、尚未写入文件的数据将会丢失。在下一次数据库启动之后,Oracle可以通过重做日志进行事务重演(也就是进行前滚),将数据库恢复到崩溃之前的状态,然后数据库
可以打开提供使用,之后Oracle可以将未提交的事务进行回滚。
检查点的存在就是为了缩短这个恢复时间。
当检查点发生时(此时的SCN被称为Checkpoint SCN),Oracle 会通知DBWR进程,把修改过的数据,也就是次Checkpoint SCN 之前的脏数据(Dirty Data)从 Buffer Cache 写入磁盘,当写入完成之后,CKPT进程更新控制文件和数据文件头,记录检查点信息,标识变更。
在检查点完成之后,次检查点之前修改过的数据都已经写回磁盘,重做日志文件中的相应重做记录对于崩溃实例恢复不再有用。
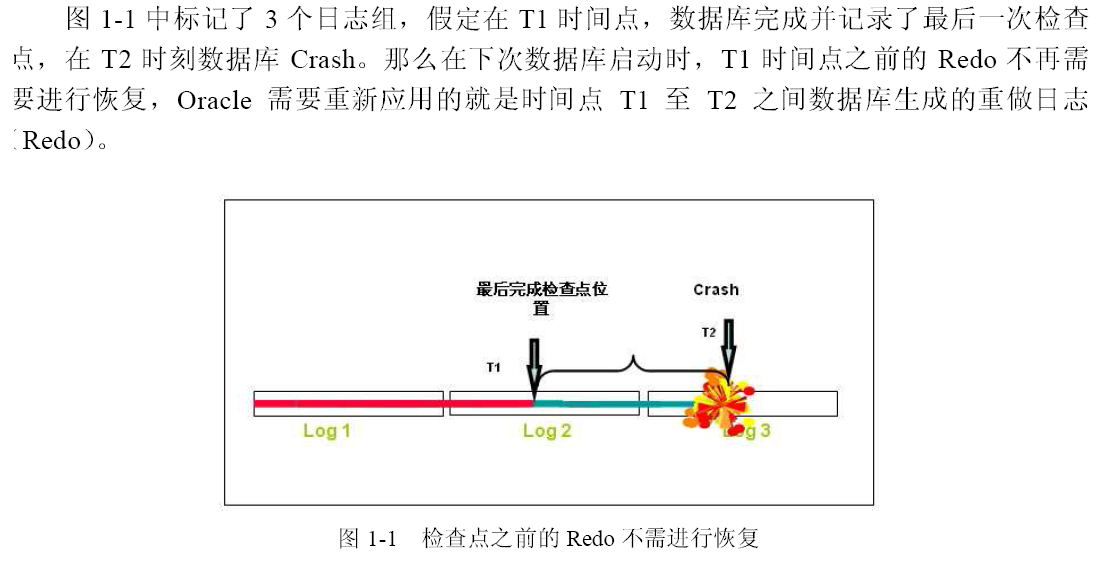
从图1.1 可以看出,检查点的频度对于数据库的恢复时间具有极大地影响 ,如果检查点的频率高,那么恢复时需要应用的重做日志就相对的少,恢复时间就可以缩短。
但是,数据库内部操作的相关性极强,过于频繁的 检查点同样会带来性能问题, 尤其是更新频繁的数据库。所以数据库的优化是一个系统工程,不能草率。
更进一步,如果Oracle可以在性能的允许下,使得SCN逐步逼近Redo的最近更新,那么最终可以获得一个最佳平衡点,使得Oracle可以最大化的减少恢复的时间。
为了实现这一目标,Oracle在不同版本中一直在改进检查点的算法,
2.常规检查点和增量检查点:
为了区分,在Oracle 8 以前,Oracle实施的检查点通常被称为常规检查点(Conventional Checkpoint) ,这类检查点按照一定的条件触发。
从Oracle 8 开始,Oracle 引入了增量检查点,(Incremental Checkpoint)的概念。
新版本Oracle主要引入了检查点队列(Checkpoint Queue)机制,在数据库内部,每一个脏数据都会移动到检查点队列,按照Low RBA 的顺序(第一次对此数据块修改对应的Redo Byte Address)来排队,
如果一个数据块进行过多次修改,该数据块在检查点队列上的顺序并不会发生变化。
当执行检查点时,DBWR从检查点队列按照 Low RBA 的顺序写出,实例检查点因此可以不断增进、阶段性的,CKPT 进程使用非常轻量级的控制文件更新协议,将当前的最低RBA写入控制文件。
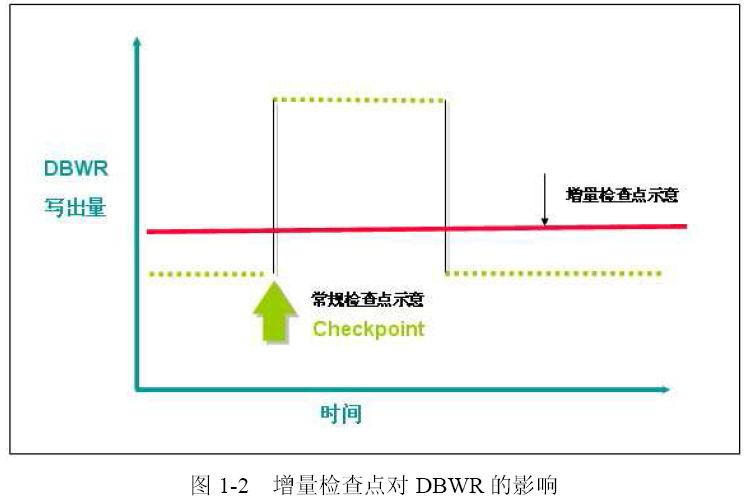
因为增量检查点可以连续的进行,因此检查点 RBA可以比常规检查点更接近数据库的最后状态,从而在数据库实例的恢复中可以极大地减少恢复时间。
而且,通过增量检查点,DBWR 可以持续的进行写出,从而避免了常规检查点出发的峰值写入对I/O 的过度征用,如图1-2
在数据库中,增量检查点是通过Fast-start Checkpoint 特性来实现的,通过查询 v$option 试图,了解这一特性:

改组件包含3个主要特性,可以加快系统在故障后的恢复,提高系统的可用性。
- Fast-Start Checkpoing
- Fast-Start On-Demand Rollback
- Fast-Start Parallel Rollback
Fast-Start Checkpoint 特性在Oracle i8 中, 主要通过参数 FAST_START_IO_TARGET 来实现;在Oracle i9 中,Fast-Start Checkpoint 主要通过参数 FAST_START_MTTR_TARGET 来实现。
3. FAST_START_MTTR_TARGET
FAST_START_MTTR_TARGET 参数从 i9 开始被引入,该参数定义数据库进行Crash 恢复的时间,单位是秒,取值范围是0-3600秒之间。
在Oracle i9中, Oracle推荐这个参数代替FAST_START_IO_TARGET、LOG_CHECKPOINT_TIMEOUT 及 LOG_CHECKPOINT_INTERVAL 参数。缺省情况下,FAST_START_IO_TARGET和FAST_START_IO_TARGET已经被设置为零。
从Oracle 9i R2 开始,Oracle 引入了一个新的视图提供MTTR 建议:

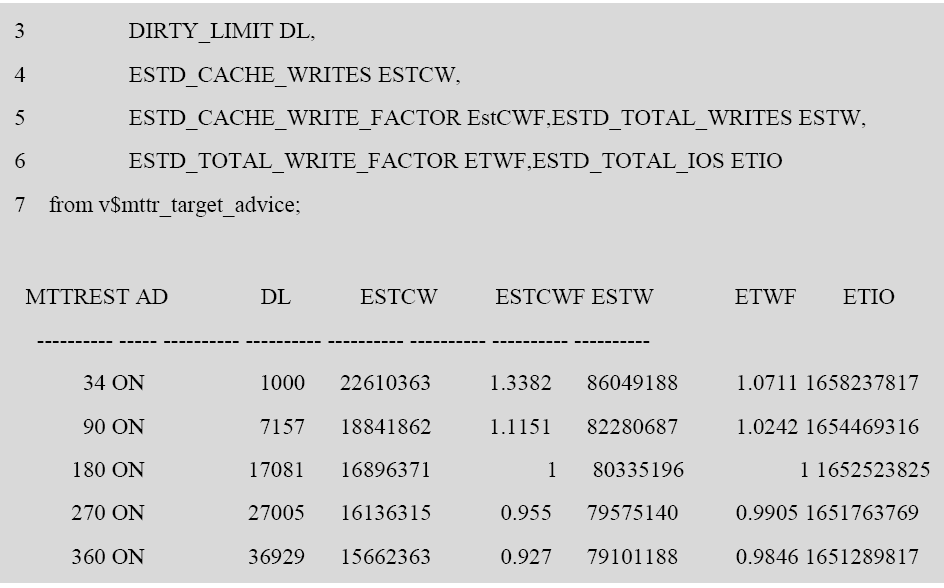
该视图评估在不同 FAST_START_MTTR_TARGET 设置下,系统需要执行的 I/O 次数等操作。用户可以根据数据库的建议,对该参数进行调整。
这个建议信息的收集受到 ORACLE 9i 新引入的初始化参数 statics_level 的控制,该参数设置为typical 或 ALL 时,MTTR 建议信息被收集:

也可以通过 v$statistics_level 试图来查询 MTTR Advice 的当前设置:

数据库当前的实例恢复状态可以通过试图 v$instance_recovery 查询得到:
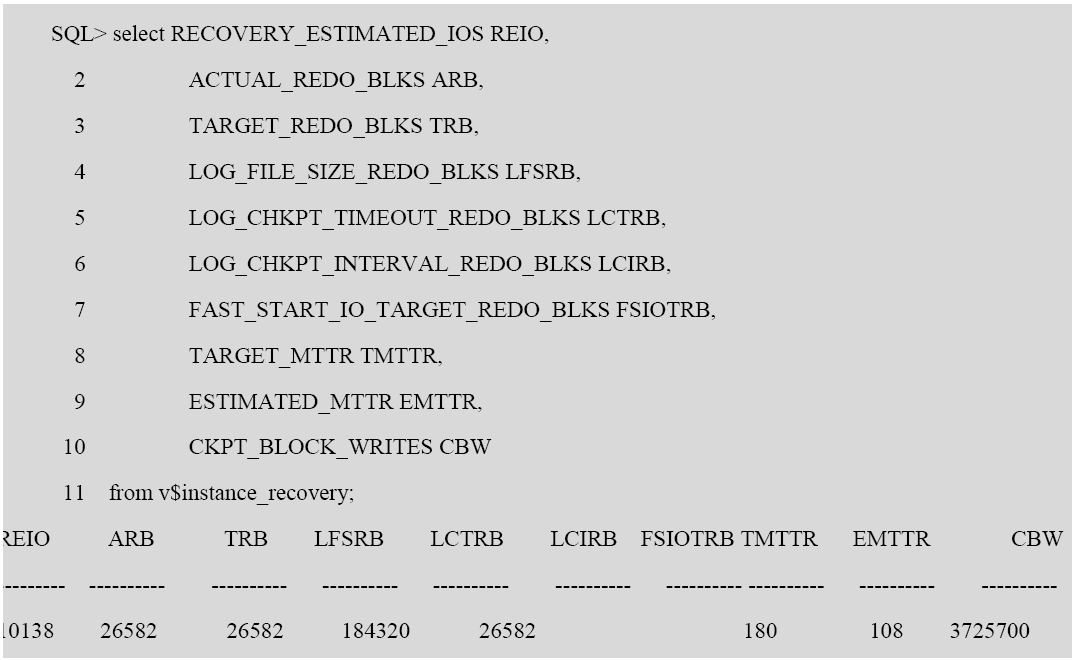
从 v$instance_recovery 视图,可以看到当前数据库估计的平均恢复时间(MTTR)参数: ESTIMATED_MTTR : 这个值的估算是基于 Dirty Buffer 的数量和日志块数量得出来的,也就是数据库崩溃实例恢复将需要的时间。
4. Oracle 10g 自动检测点调整:
从10g开始,数据库可以实现自动调整的检查点,数据库可以利用系统低 I / O ,负载时段写出内存中的脏数据,从而提高数据库的效率。
5.从控制文件获取检查点的信息:
在控制文件的转储中,可以看到检查点进程进度的记录:
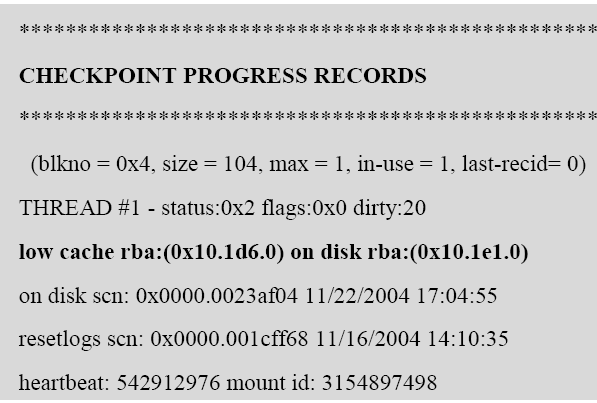

这里 low cache rba (recovery block address )指在Cache中,最低的RBA地址,在实例恢复中,需要从这里开始恢复。
on disk rba 时磁盘上的最高重做值,在进行恢复时应用重做至少要恢复到这个值。
1.2.3 正常关闭数据库的情况:
接下来看一下数据库是怎样根据 SCN 和 Checkpoint 来进行一致性判断及恢复控制的。
在控制文件和数据文件头上,对于每个数据文件都有一个“Checkpoint SCN” 和 “Stop SCN” ,这些Checkpoint 和 SCN至关重要,Oracle通过比较这些SCN来确定数据库是否需要恢复。
下面是一个来自 Clean Shutdown 的数据库的控制文件头的内容。
因为数据库在关闭之前执行了完全检查点,所以线程检查点SCN和所有数据文件检查点SCN和数据文件Stop SCN 都一致。
首先通过 shutdow immediate 关闭数据库,然后在Mount状态转储控制文件内容:


这个trace文件里就记录了控制文件的详细内容。

Redo信息

数据文件的检查点信息:

注意这里,数据库正常关闭之后,由于执行了完全检查点,数据库文件处于一致的状态,检查点SCN在此等于 Stop SCN .
在此情况下,由于 数据库处于一致状态,如果数据库文件没有损失,下次启动Oracle就能通过验证,顺利启动。
1.2.4 数据库异常关闭的情况
通过 shutdown abort 可以模拟一次异常,当使用shutdown abort 方式关闭数据库时,Oracle立即中断所有事务,关闭当前所有数据库连接, 不执行检查点,立即关闭数据库。
使用这种方式关闭数据库和断点以前的故障类似,数据库在下一次启动时必须执行实例恢复才能够启动。除非特别紧急,通常不建议使用这种方式关闭数据库。
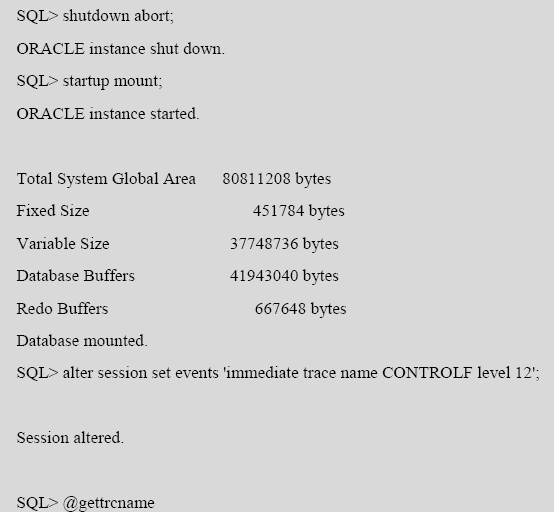

查看此时控制文件的内容:
1.数据库的相关信息:
在Database Entry 部分,可以看到数据库 Thread Checkpoint 信息:

2.控制文件记录的redo信息:
在控制文件中,也可以找到 REDO THREAD 检查点信息:

3.数据文件检查点信息:
以下是控制文件中记录的数据文件检查点信息:

注意,由于数据库异常关闭,数据库没有完成最后的检查点,数据文件的 stop SCN仍然为无穷大fffffff
在以上的信息中, 各部分的Checkpoint SCN 都一致,但是数据库文件的stop SCN不等于checkpoint scn,数据库关闭时没有执行完全检查点,是异常关闭,此时启动数据库需要进行恢复。
4.数据库的实例恢复
在数据库异常关闭之后,下次启动时,Oracle会自动执行实例恢复 Instance Recovery 实例恢复包括两个步骤:Cache Recovery 和 Transaction Recovery。
继续以上的测试,在启动数据库之后可以从 alert_<sid>.log 文件中获得数据库关于恢复的相关信息:

Oracle恢复的过程, 首先读取日志, 从最后完成的检查点开始, 应用所有重做记录,这个过程叫做前滚 Rolling Forward ,也就是Cache Recovery 的过程,完成前滚之后,数据可以被打开提供访问和使用。
此后进入实例恢复的第二阶段,Oracle回滚未提交事务,使用 Fast-Start On-Demand Rollback 和 Fast-Start Parallel Rollback
P48
最新文章
- SpringMVC 参数注入
- [No00007E]2016-面经[中]
- 花式玩转社交App,百变应用场景
- ./fedora_install_oracle.sh bad interpreter
- configure错误列表供参考
- C#中常见的winform控件命名规范
- CSS display 属性详解
- php获取当前域名
- Oracle 琐表和查询谁在琐表并解决
- Windows下切分文件(GnuWin32)
- LeetCode每天一题之两数之和
- POJ 2478Farey Sequence
- composer 重装常见错误
- 1.关于Swift
- finecms在任意页面调用栏目名称和地址等
- redis配置笔记
- js精确计算(js浮点数精度问题)
- Xianfeng轻量级Java中间件平台:用户管理
- Anaconda安装教程+Tensorflow教程
- CPU GPU FPU TPU 及厂商