mongodb MongoDB 聚合 group(转)
MongoDB 聚合
MongoDB中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。有点类似sql语句中的 count(*)。
基本语法为:db.collection.aggregate( [ <stage1>, <stage2>, ... ] )
现在在mycol集合中有以下数据:
{ "_id" : 1, "name" : "tom", "sex" : "男", "score" : 100, "age" : 34 }
{ "_id" : 2, "name" : "jeke", "sex" : "男", "score" : 90, "age" : 24 }
{ "_id" : 3, "name" : "kite", "sex" : "女", "score" : 40, "age" : 36 }
{ "_id" : 4, "name" : "herry", "sex" : "男", "score" : 90, "age" : 56 }
{ "_id" : 5, "name" : "marry", "sex" : "女", "score" : 70, "age" : 18 }
{ "_id" : 6, "name" : "john", "sex" : "男", "score" : 100, "age" : 31 }
1、$sum 计算总和。
Sql: select sex,count(*) from mycol group by sex
MongoDb: db.mycol.aggregate([{group: {_id: 'group: {_id: 'sex', personCount: {$sum: 1}}}])

Sql: select sex,sum(score) totalScore from mycol group by sex
MongoDb: db.mycol.aggregate([{group: {_id: 'group: {_id: 'sex', totalScore: {sum:′score'}}}])

2、$avg 计算平均值
Sql: select sex,avg(score) avgScore from mycol group by sex
Mongodb: db.mycol.aggregate([{group: {_id: 'group: {_id: 'sex', avgScore: {avg:′score'}}}])

3、$max 获取集合中所有文档对应值得最大值。
Sql: select sex,max(score) maxScore from mycol group by sex
Mongodb: db.mycol.aggregate([{group: {_id: 'group: {_id: 'sex', maxScore : {max:′score'}}}])

4、$min 获取集合中所有文档对应值得最小值。
Sql: select sex,min(score) minScore from mycol group by sex
Mongodb: db.mycol.aggregate([{group: {_id: 'group: {_id: 'sex', minScore : {min:′score'}}}])

5、$push 把文档中某一列对应的所有数据插入值到一个数组中。
Mongodb: db.mycol.aggregate([{group: {_id: 'group: {_id: 'sex', scores : {push:′score'}}}])

6、$addToSet 把文档中某一列对应的所有数据插入值到一个数组中,去掉重复的
db.mycol.aggregate([{group: {_id: 'group: {_id: 'sex', scores : {addToSet:′score'}}}])

7、 $first 根据资源文档的排序获取第一个文档数据。
db.mycol.aggregate([{group: {_id: 'group: {_id: 'sex', firstPerson : {first:′name'}}}])

8、 $last 根据资源文档的排序获取最后一个文档数据。
db.mycol.aggregate([{group: {_id: 'group: {_id: 'sex', lastPerson : {last:′name'}}}])

9、全部统计 null
db.mycol.aggregate([{group:{_id:null,totalScore:{group:{_id:null,totalScore:{push:'$score'}}}])

例子
现在在t2集合中有以下数据:
{ "country" : "china", "province" : "sh", "userid" : "a" }
{ "country" : "china", "province" : "sh", "userid" : "b" }
{ "country" : "china", "province" : "sh", "userid" : "a" }
{ "country" : "china", "province" : "sh", "userid" : "c" }
{ "country" : "china", "province" : "bj", "userid" : "da" }
{ "country" : "china", "province" : "bj", "userid" : "fa" }
需求是统计出每个country/province下的userid的数量(同一个userid只统计一次)
过程如下。
首先试着这样来统计:
db.t2.aggregate([ { group: {"_id": { "country" : "group: {"_id": { "country" : "country", "prov": "province"} , "number":{province"} , "number":{sum:1}} } ])
结果是错误的:

原因是,这样来统计不能区分userid相同的情况 (上面的数据中sh有两个 userid = a)
为了解决这个问题,首先执行一个group,其id 是 country, province, userid三个field:
db.t2.aggregate([ { group: {"_id": { "country" : "group: {"_id": { "country" : "country", "province": "province","uid":"province","uid":"userid" } } } ])

可以看出,这步的目的是把相同的userid只剩下一个。
然后第二步,再第一步的结果之上再执行统计:
db.t2.aggregate([
{ group: {"_id": { "country" : "group: {"_id": { "country" : "country", "province": "province","uid":"province","uid":"userid" } } } ,
{ group: {"_id": { "country" : "group: {"_id": { "country" : "_id.country", "province": "_id.province" }, count : {_id.province" }, count : {sum : 1 } } }
])
这回就对了

加入一个$project操作符,把_id去掉
db.t2.aggregate([ { group: {"_id": { "country" : "group: {"_id": { "country" : "country", "province": "province","uid":"province","uid":"userid" } } } ,
{ group: {"_id": { "country" : "group: {"_id": { "country" : "_id.country", "province": "_id.province" }, count: {_id.province" }, count: {sum : 1 } } },
{ project : {"_id": 0, "country" : "project : {"_id": 0, "country" : "_id.country", "province" : "$_id.province", "count" : 1}}
])
最终结果如下:

管道的概念
管道在Unix和Linux中一般用于将当前命令的输出结果作为下一个命令的参数。
MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理。管道操作是可以重复的。
表达式:处理输入文档并输出。表达式是无状态的,只能用于计算当前聚合管道的文档,不能处理其它的文档。
这里我们介绍一下聚合框架中常用的几个操作:
- $project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。
- match:用于过滤数据,只输出符合条件的文档。match:用于过滤数据,只输出符合条件的文档。match使用MongoDB的标准查询操作。
- $limit:用来限制MongoDB聚合管道返回的文档数。
- $skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。
- $unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。
- $group:将集合中的文档分组,可用于统计结果。
- $sort:将输入文档排序后输出。
- $geoNear:输出接近某一地理位置的有序文档。
1、$project实例
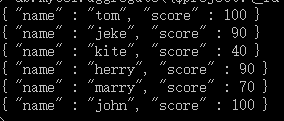
db.mycol.aggregate({$project:{name : 1, score : 1}})
这样的话结果中就只还有_id,name和score三个字段了,默认情况下_id字段是被包含的,如果要想不包含_id话可以这样:
db.mycol.aggregate({$project:{_id : 0, name : 1, score : 1}})
2、$match实例
match用于获取分数大于30小于并且小于100的记录,然后将符合条件的记录送到下一阶段match用于获取分数大于30小于并且小于100的记录,然后将符合条件的记录送到下一阶段group管道操作符进行处理
db.mycol.aggregate([{match :{score: {gt: 30, lt: 100}}},{group:{_id:'sex',count:{sum:1}}}])

3、完整实例
db.cost_price.aggregate([
{"$match":{"sku_id":{"$in":[,,]},"work_time":{"$lte":"2018-01-01"}}},
{"$group":{"_id":"$sku_id","cost_price":{"$last":"$cost_price"},"work_time":{"$last":"$work_time"}}},
{"$project" : {"cost_price" : ,"work_time" : }}
]);
最新文章
- DAC Usage4:从 Backup Package(.bacpac)还原DB
- 上海闪酷成为京东商城第一批独立软件开发商(ISV)
- SQL获取当前时间(日期)
- Install Nvidia driver 367.18 or later
- Yii2.0 执行流程分析
- js事件知识整理
- jQuery类级别插件--返回顶部,底部,去到任何部位
- AsyncResult
- 运维之Linux基础知识(三)
- 深入理解 Linux 的 RCU 机制
- 1034. Head of a Gang (30) -string离散化 -map应用 -并查集
- 【LOJ2542】【PKUWC 2018】随机游走 min-max容斥 树上高斯消元
- Webdriver+Testng实现测试用例失败自动截图功能
- mysql写注释的几种方法
- 【1】windows下IOS开发基础环境搭建
- TimingTool - The Timing Diagram Editor
- 详解Vue中的nextTick
- php学习六:字符串
- javascript的创建对象object.create()和属性检测hasOwnPrototype()和propertyIsEnumerable()
- (zxing.net)一维码EAN 13的简介、实现与解码